 -
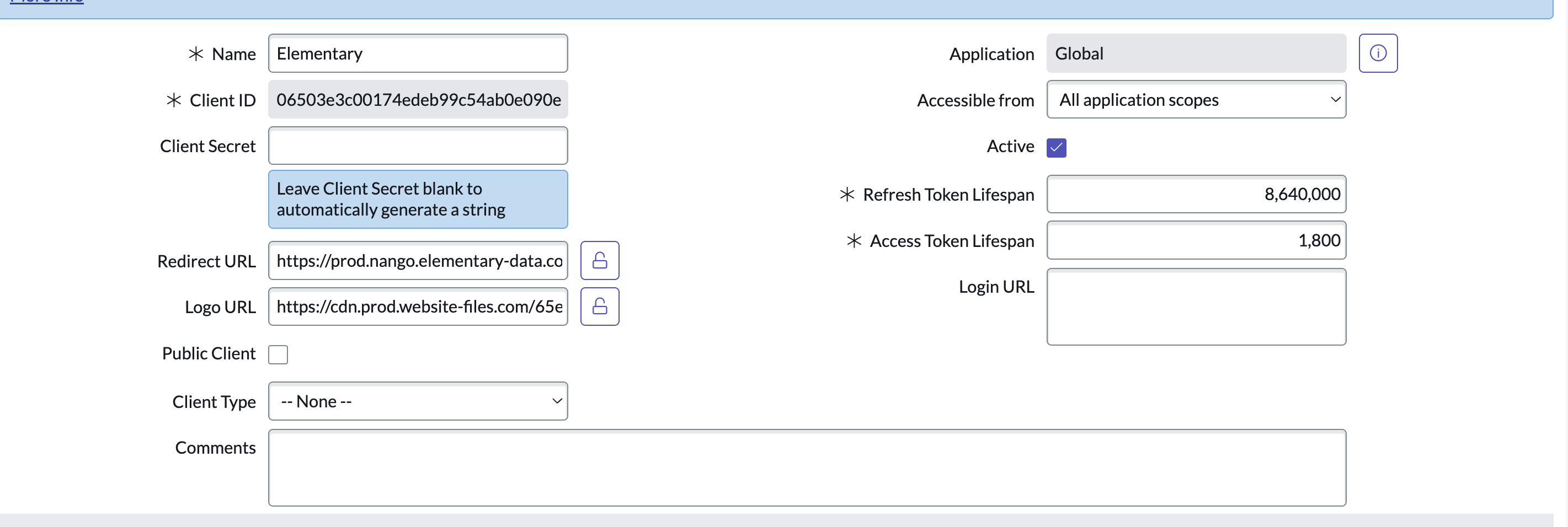
-2. Go to the Service principals tab, then click Add service principal (add photo)
-
-
-
-2. Go to the Service principals tab, then click Add service principal (add photo)
-
-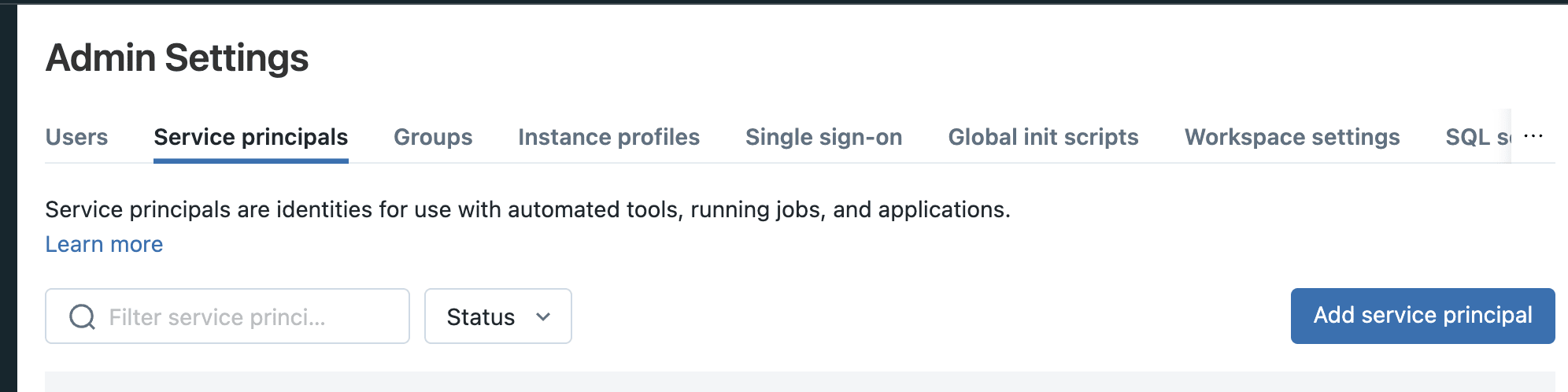 -
-3. Give the service principal a good name (e.g elementary) and click Add (add photo)
-
-
-
-3. Give the service principal a good name (e.g elementary) and click Add (add photo)
-
-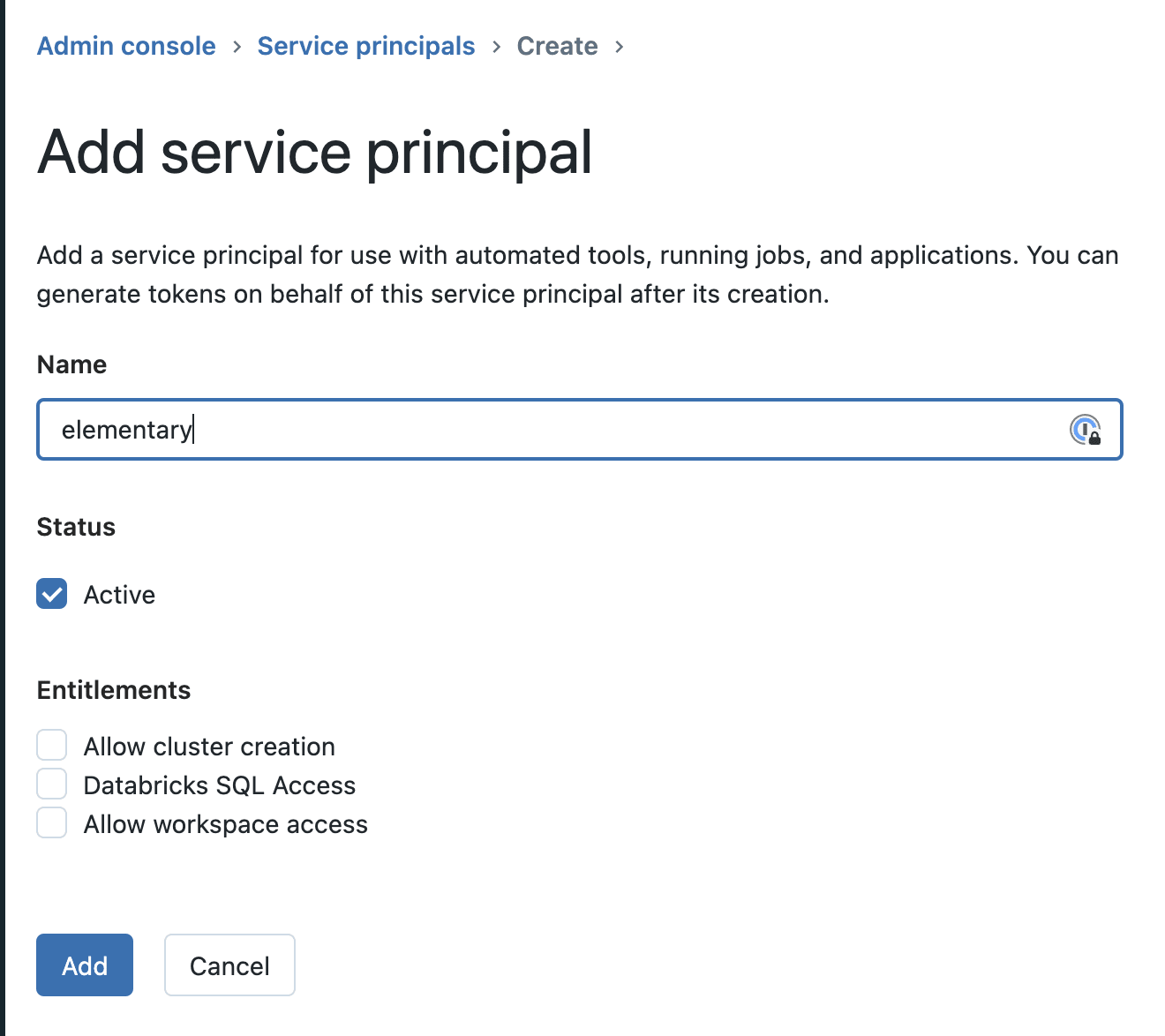 -
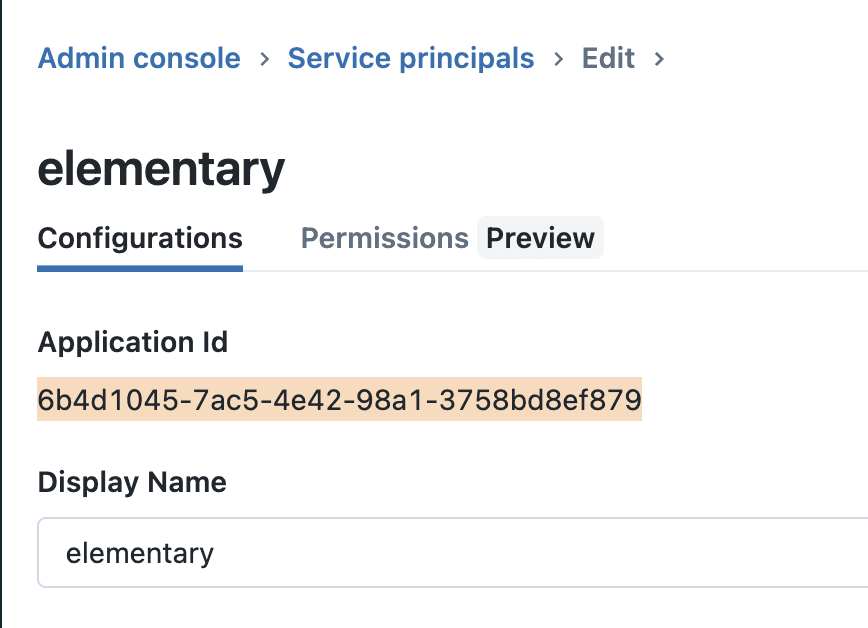
-4. Then, from the service principal configuration view, copy the Application Id (add photo)
-
-
-
-4. Then, from the service principal configuration view, copy the Application Id (add photo)
-
- -
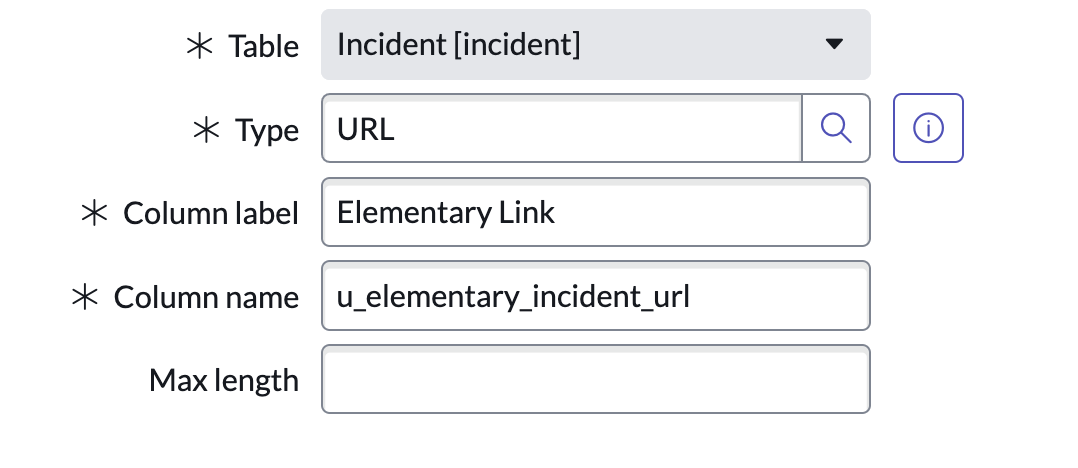
-4. Finally, run the following query:
-
-```
-GRANT SELECT ON SCHEMA
-
-4. Finally, run the following query:
-
-```
-GRANT SELECT ON SCHEMA - - -
 -
-
-### Supported adapters
-
-
-
-
-### Supported adapters
-
- +
+
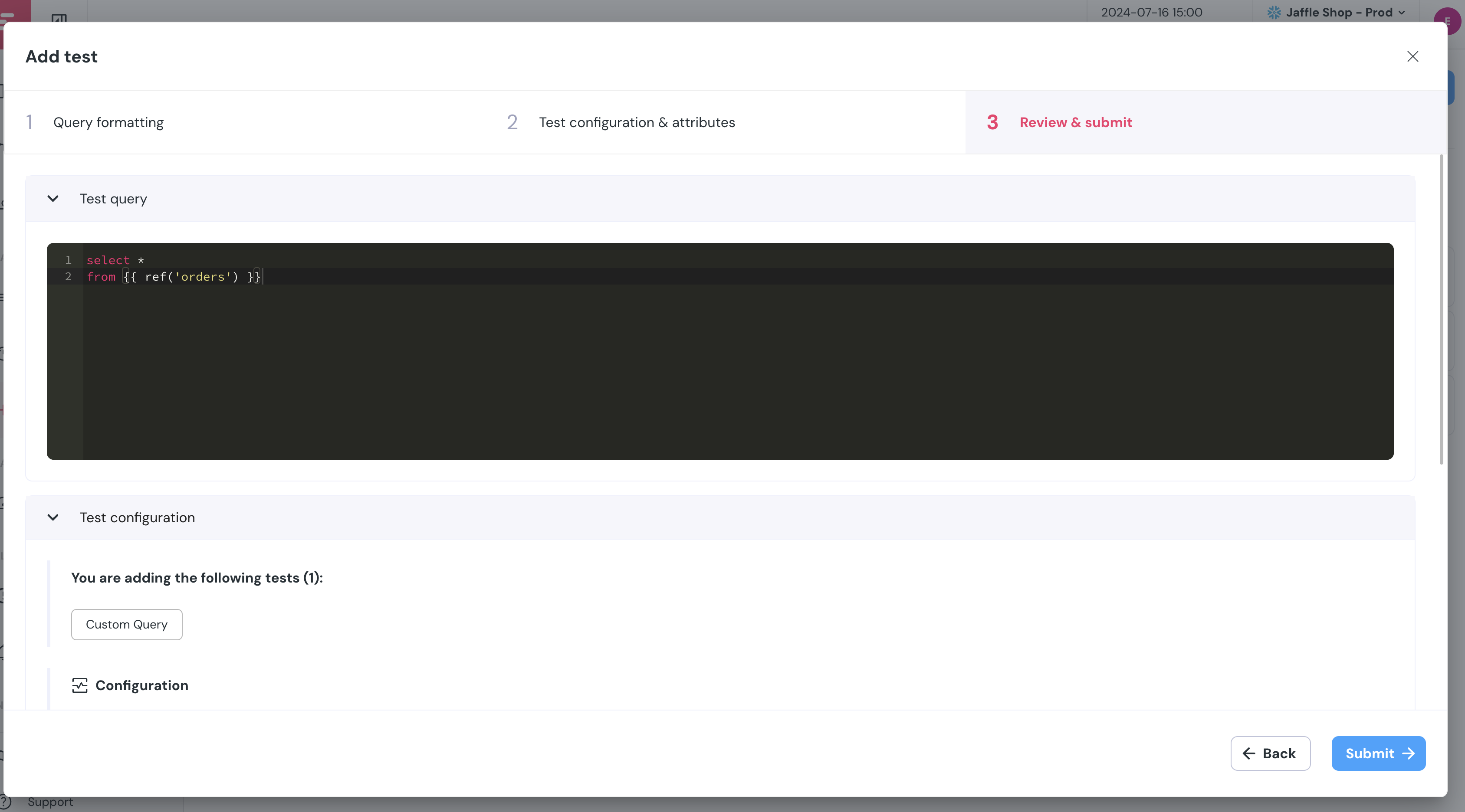
+## Custom SQL tests in UI
+
+
+
+
+## Custom SQL tests in UI
+
+ +
+
+## Model runs in dashboard
+
+
+
+
+## Model runs in dashboard
+
+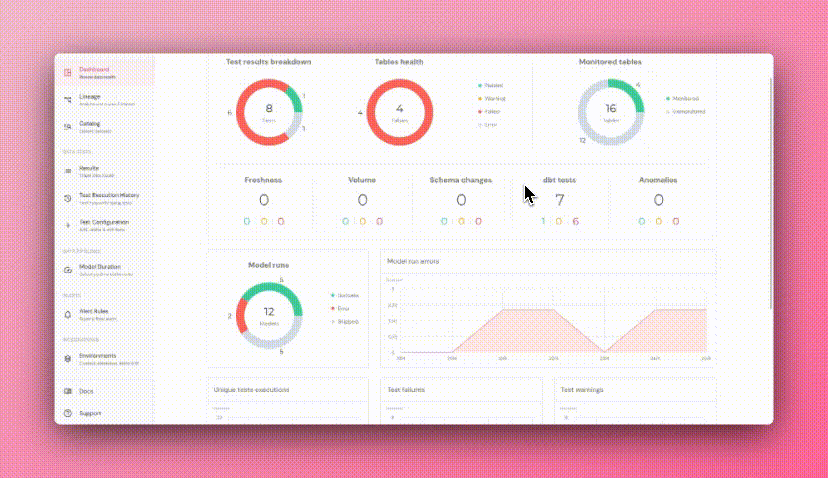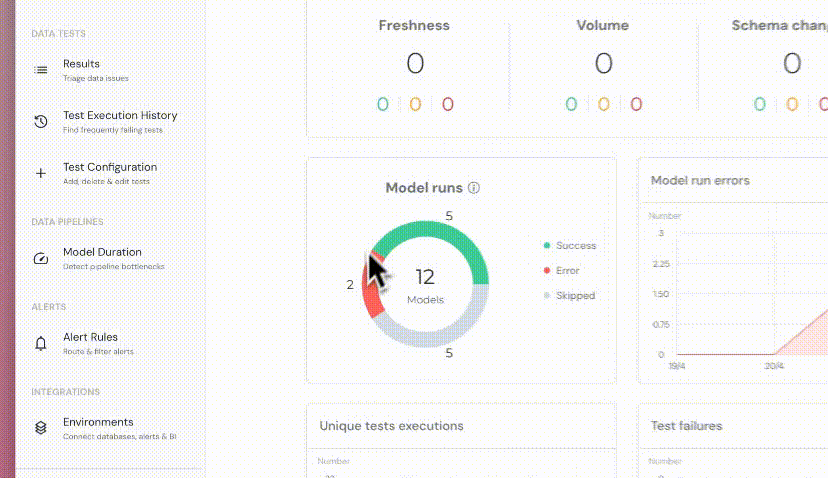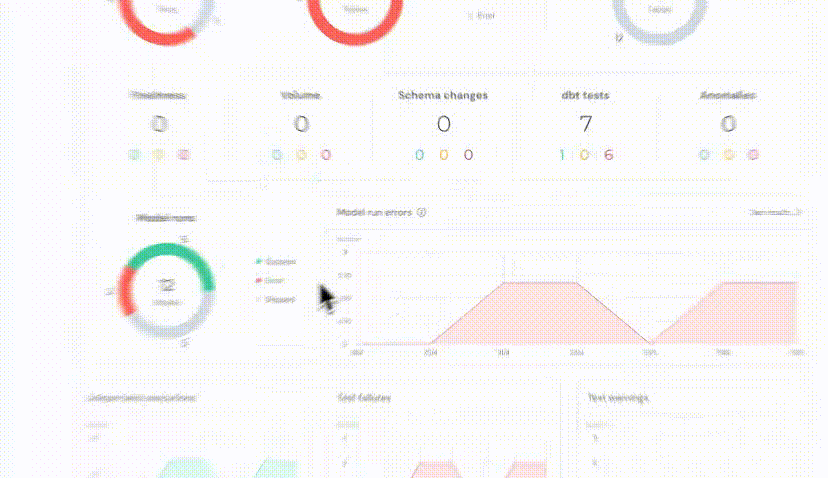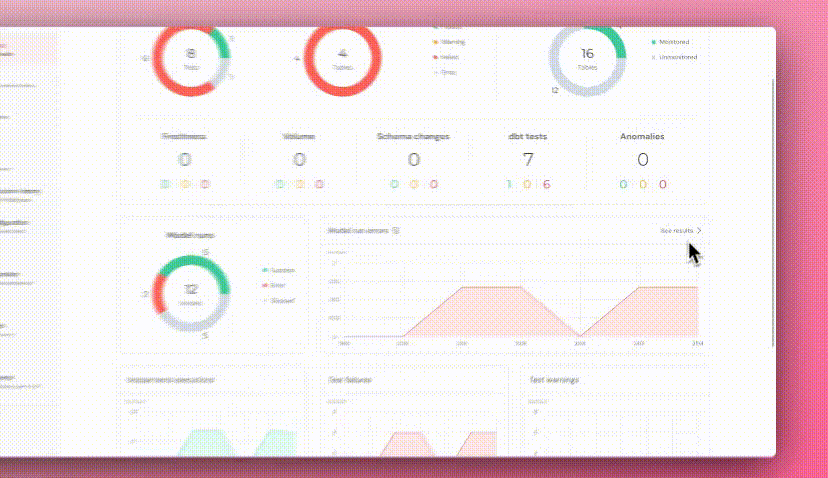 +
+
+## DAG subset in Lineage
+
+
+
+
+## DAG subset in Lineage
+
+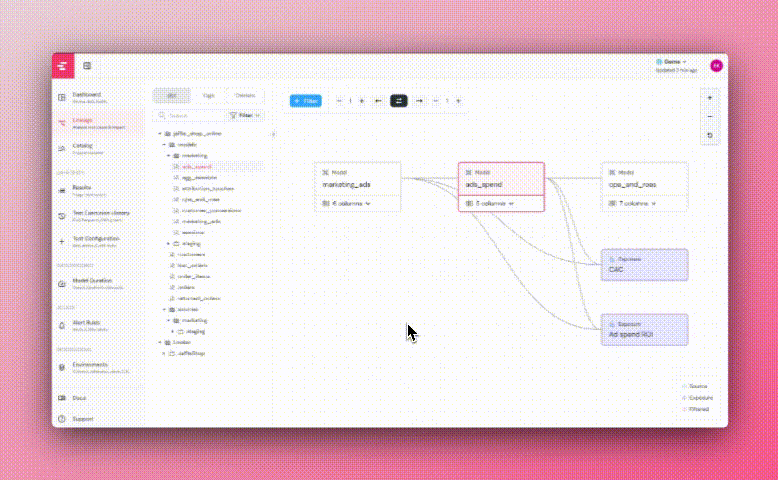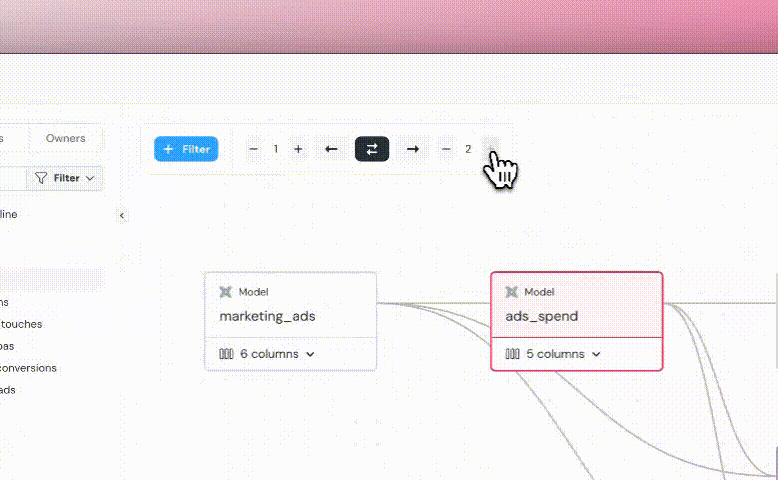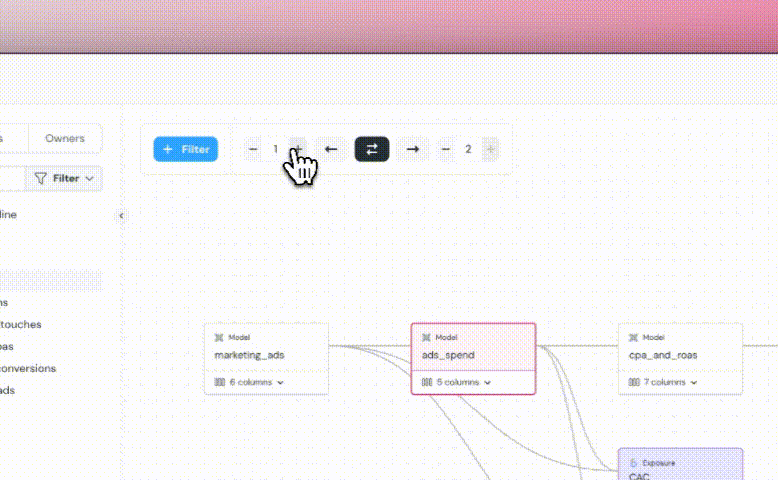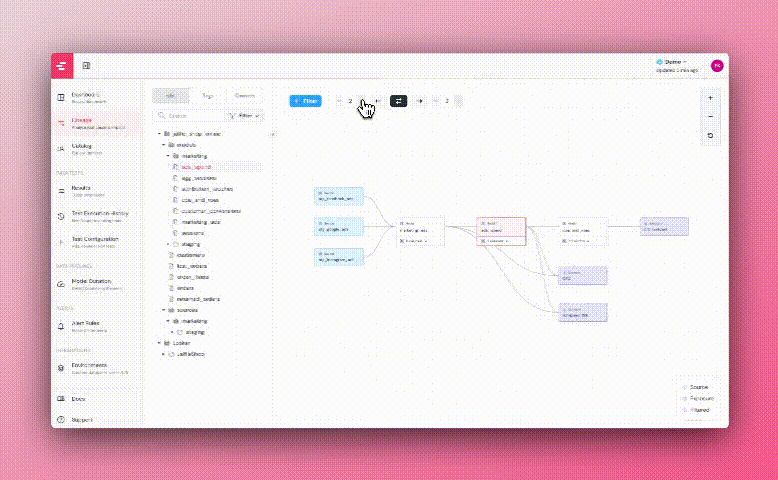 +
+
+## Role-based access control
+
+
+
+
+## Role-based access control
+
+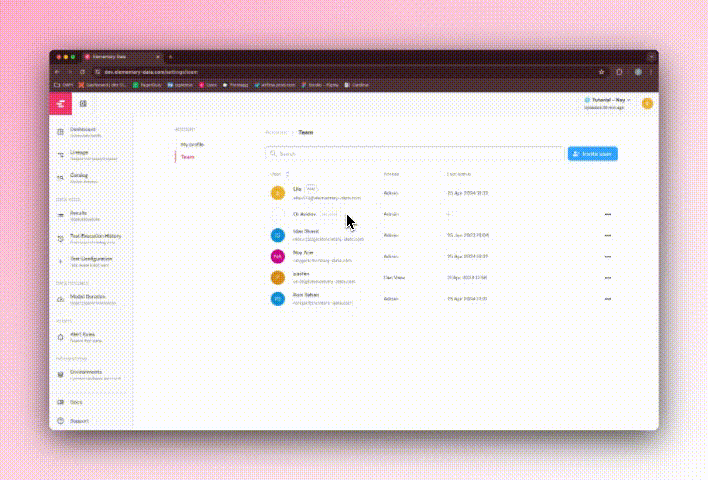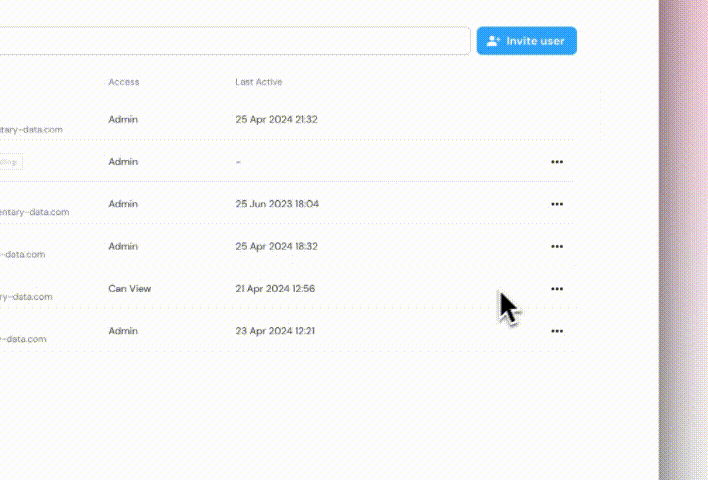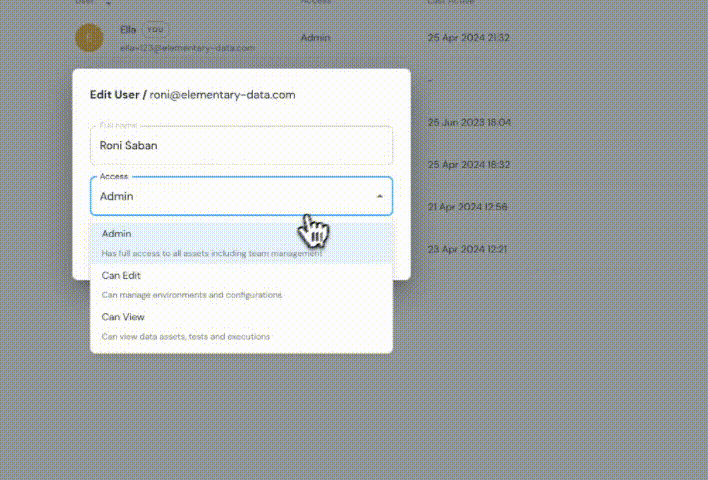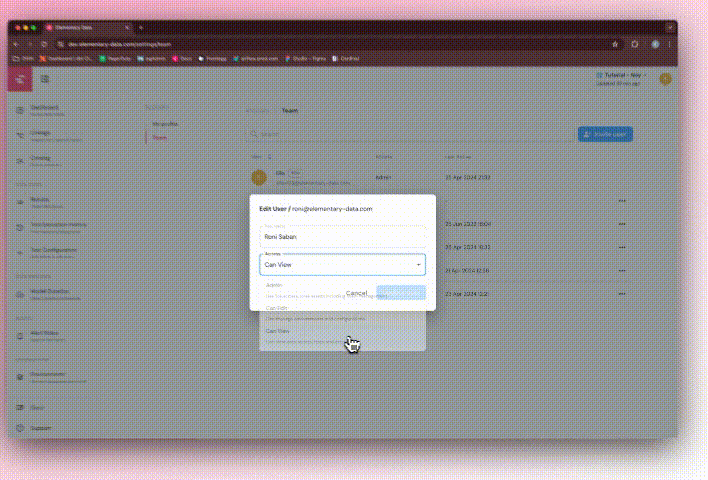 +
diff --git a/docs/cloud/ai-agents/catalog-agent.mdx b/docs/cloud/ai-agents/catalog-agent.mdx
new file mode 100644
index 000000000..98d1275c8
--- /dev/null
+++ b/docs/cloud/ai-agents/catalog-agent.mdx
@@ -0,0 +1,54 @@
+---
+title: "Catalog AI Agent"
+sidebarTitle: "Catalog agent"
+icon: "book-open"
+---
+
+
diff --git a/docs/cloud/ai-agents/catalog-agent.mdx b/docs/cloud/ai-agents/catalog-agent.mdx
new file mode 100644
index 000000000..98d1275c8
--- /dev/null
+++ b/docs/cloud/ai-agents/catalog-agent.mdx
@@ -0,0 +1,54 @@
+---
+title: "Catalog AI Agent"
+sidebarTitle: "Catalog agent"
+icon: "book-open"
+---
+- Anomaly detection and dbt tests
- Automated freshness & volume monitors
- ML-powered anomaly detection
- dbt and cloud tests
- Bulk add/edit for tests
- Basic alerts
- Table-level lineage
- Interactive alerts
- Column-level lineage up to BI
- BI integrations
- Test results history
- Incident management
- Model and test performance
- Model and test performance
- Performance alerts
- No-code test editor
- Data health scores
- External catalog integrations
- Ticketing system integrations
- Catalog
- Metadata in code and UI
 +
+  +
+  +
+
+## How it works
+
+Digest rules are configured under **Alert Rules → Incidents Digest** tab. Each rule defines:
+
+- **When** to send the digest (cadence: daily or weekly, at a specific hour)
+- **What** incidents to include (filters by tag, owner, status, model, or category)
+- **Where** to send it (one or more destinations such as a Slack channel or email)
+
+At the scheduled time, Elementary collects all incidents that match the rule's filters since the last digest was sent, and delivers them as a single message.
+
+
+
+
+
+## How it works
+
+Digest rules are configured under **Alert Rules → Incidents Digest** tab. Each rule defines:
+
+- **When** to send the digest (cadence: daily or weekly, at a specific hour)
+- **What** incidents to include (filters by tag, owner, status, model, or category)
+- **Where** to send it (one or more destinations such as a Slack channel or email)
+
+At the scheduled time, Elementary collects all incidents that match the rule's filters since the last digest was sent, and delivers them as a single message.
+
+
+  +
+
+## Creating a digest rule
+
+Navigate to **Alert Rules** in the left sidebar and select the **Incidents Digest** tab. Click **Create digest rule** to open the configuration drawer.
+
+The filters, categories, and destinations are configured the same way as in [Alert Rules](/cloud/features/alerts-and-incidents/alert-rules). The one addition unique to digest rules is **cadence**.
+
+### Cadence
+
+Choose how often the digest should be sent:
+
+- **Daily** — sent once a day at the hour you choose.
+- **Weekly** — sent once a week on the day and at the hour you choose.
+
+The time is in UTC.
+
+
+
+
+
+## Creating a digest rule
+
+Navigate to **Alert Rules** in the left sidebar and select the **Incidents Digest** tab. Click **Create digest rule** to open the configuration drawer.
+
+The filters, categories, and destinations are configured the same way as in [Alert Rules](/cloud/features/alerts-and-incidents/alert-rules). The one addition unique to digest rules is **cadence**.
+
+### Cadence
+
+Choose how often the digest should be sent:
+
+- **Daily** — sent once a day at the hour you choose.
+- **Weekly** — sent once a week on the day and at the hour you choose.
+
+The time is in UTC.
+
+
+  +
+
+## Managing digest rules
+
+Once created, digest rules appear as cards in the **Incidents Digest** tab. From each card you can:
+
+- **Edit** the rule to change any configuration.
+- **Activate / Deactivate** the rule without deleting it.
+- **Delete** the rule.
+
+
+
+
+
+## Managing digest rules
+
+Once created, digest rules appear as cards in the **Incidents Digest** tab. From each card you can:
+
+- **Edit** the rule to change any configuration.
+- **Activate / Deactivate** the rule without deleting it.
+- **Delete** the rule.
+
+
+  +
+
+## Relationship with alert rules
+
+Digest rules are independent of [Alert Rules](/cloud/features/alerts-and-incidents/alert-rules). You can have both real-time alert rules and digest rules active at the same time — they are evaluated separately. A common pattern is to use real-time alert rules for critical on-call channels and digest rules for broader team summaries.
diff --git a/docs/cloud/features/alerts-and-incidents/incident-management.mdx b/docs/cloud/features/alerts-and-incidents/incident-management.mdx
new file mode 100644
index 000000000..85607407e
--- /dev/null
+++ b/docs/cloud/features/alerts-and-incidents/incident-management.mdx
@@ -0,0 +1,54 @@
+---
+title: Incident Management
+sidebarTitle: Incident management
+---
+
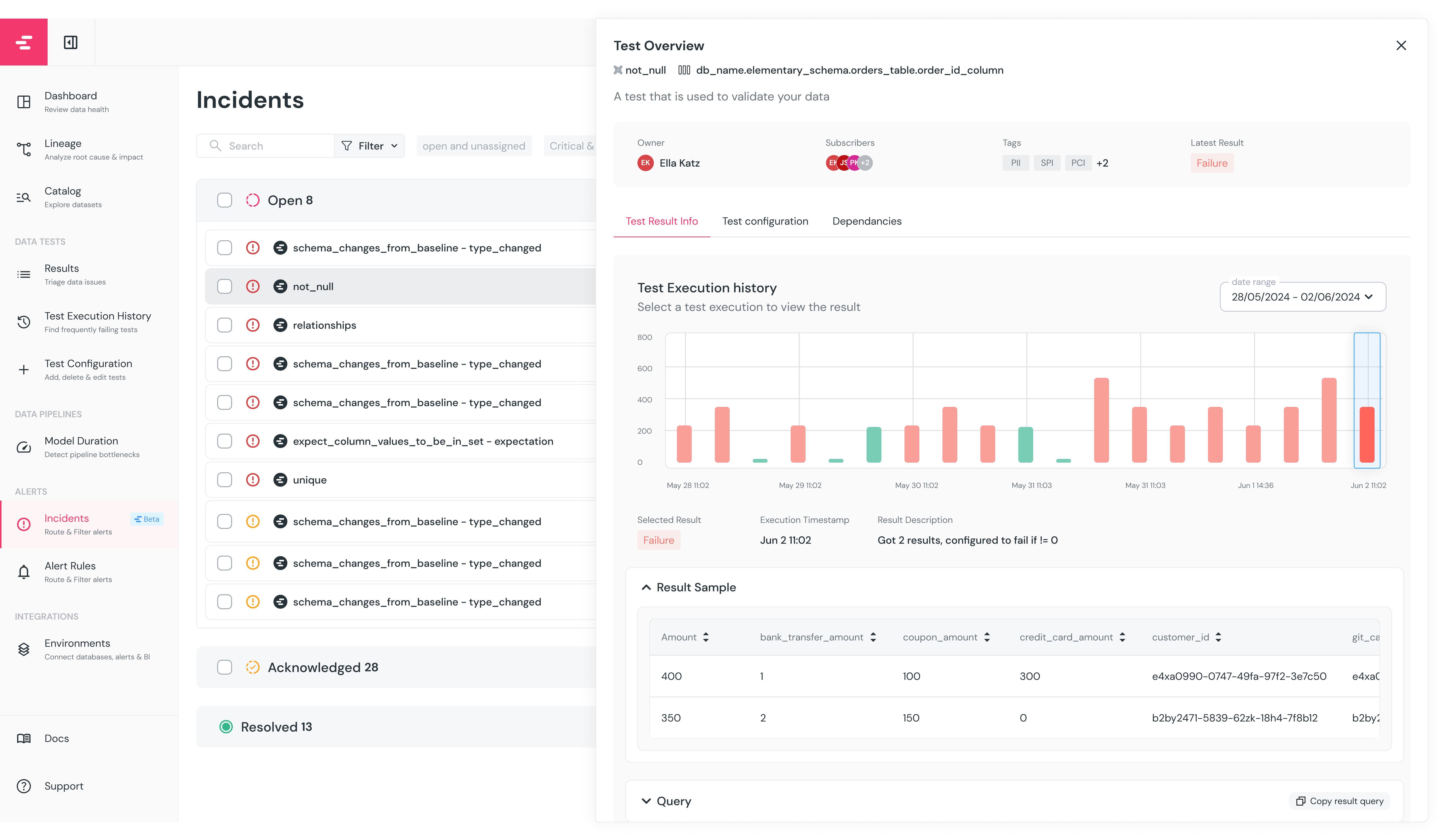
+The `Incidents` page is designed to enable your team to stay on top of open incidents and collaborate on resolving them.
+The page gives a comprehensive overview of all current and previous incidents, where users can view the status, prioritize, assign and resolve incidents.
+
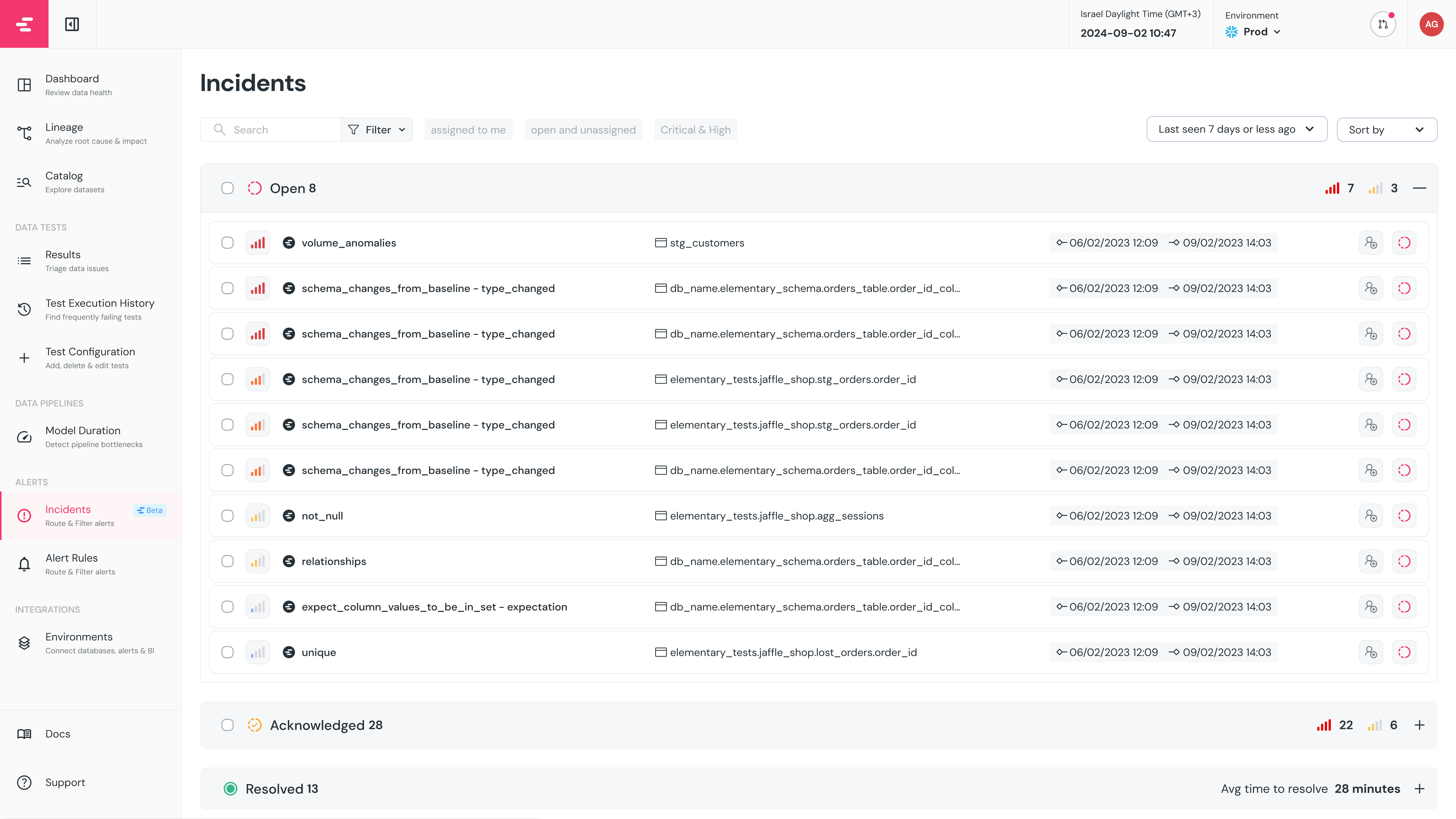
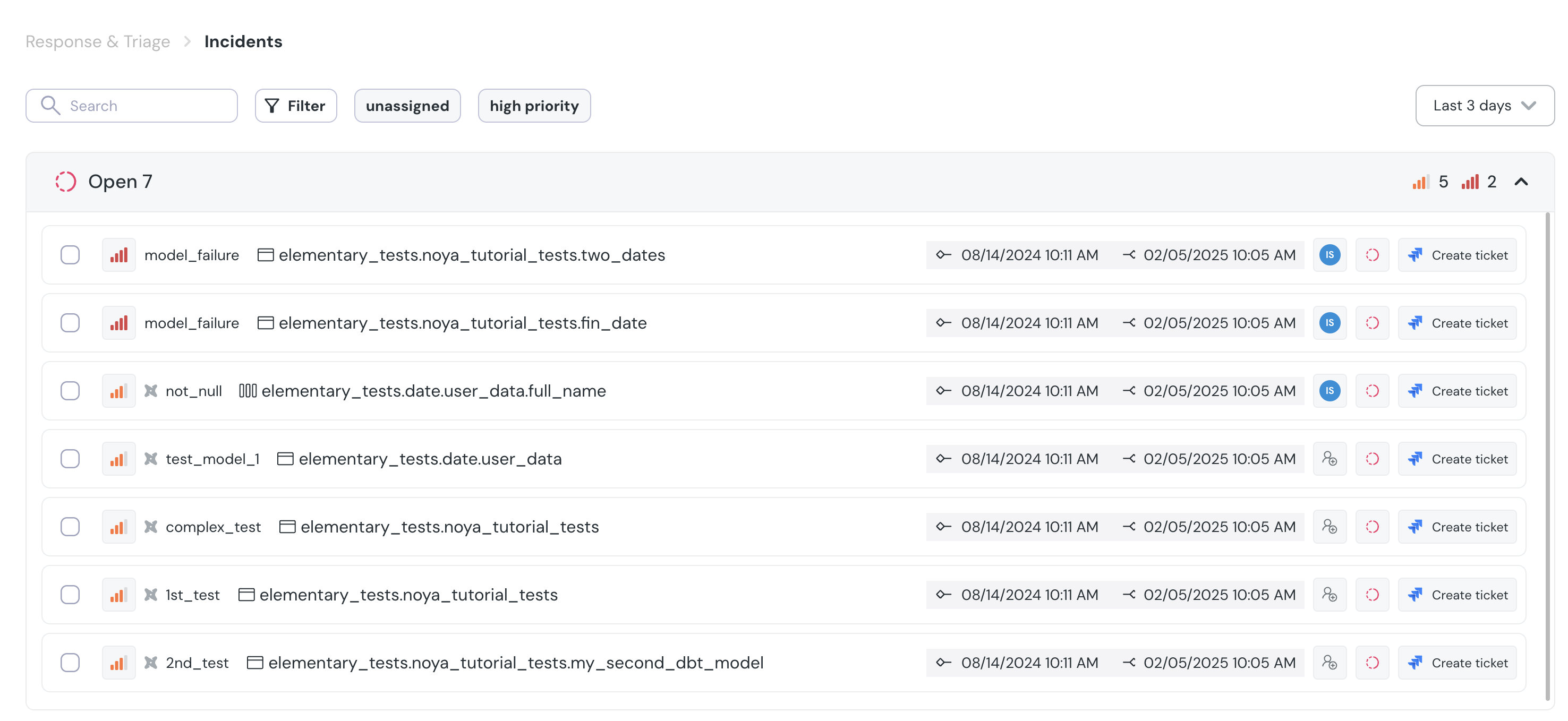
+## Incidents view and filters
+
+The page provides a view of all incidents, and useful filters:
+
+- **Quick Filters:** Preset quick filters for all, unresolved and “open and unassigned” incidents.
+- **Filter:** Allows users to filter incidents based on various criteria such as status, severity, model name and assignee.
+- **Time frame:** Filter incidents which were open in a certain timeframe.
+
+
+
+
+## Interacting with Incidents
+
+An incident has a status, assignee and severity.
+These can be set in the Incidents page, or from an alert in integrations that support alert actions.
+
+- **Incident status**: Will be set to `open` by default, and can be changed to `Acknowledged` and back to `Open`. When an alert is manually or automatically set as `Resolved`, it will close and will no longer be modified.
+- **Incident assignee**: An incident can be assigned to any user on the team, and they will be notified.
+ - If you assign an incident to a user, it is recommended to leave the incident `Open` until the user changes status to `Acknowledged`.
+- **Incident severity**: Severity of an incident can be Low, Normal, High or Critical. By default, model errors are set to Critical, test failures set to High and warnings are marked as Normal, but the severity can be changed manually. _Coming soon_ : Severity will be automated by an analysis of the impacted assets.
+
+
+
+
+## Relationship with alert rules
+
+Digest rules are independent of [Alert Rules](/cloud/features/alerts-and-incidents/alert-rules). You can have both real-time alert rules and digest rules active at the same time — they are evaluated separately. A common pattern is to use real-time alert rules for critical on-call channels and digest rules for broader team summaries.
diff --git a/docs/cloud/features/alerts-and-incidents/incident-management.mdx b/docs/cloud/features/alerts-and-incidents/incident-management.mdx
new file mode 100644
index 000000000..85607407e
--- /dev/null
+++ b/docs/cloud/features/alerts-and-incidents/incident-management.mdx
@@ -0,0 +1,54 @@
+---
+title: Incident Management
+sidebarTitle: Incident management
+---
+
+The `Incidents` page is designed to enable your team to stay on top of open incidents and collaborate on resolving them.
+The page gives a comprehensive overview of all current and previous incidents, where users can view the status, prioritize, assign and resolve incidents.
+
+## Incidents view and filters
+
+The page provides a view of all incidents, and useful filters:
+
+- **Quick Filters:** Preset quick filters for all, unresolved and “open and unassigned” incidents.
+- **Filter:** Allows users to filter incidents based on various criteria such as status, severity, model name and assignee.
+- **Time frame:** Filter incidents which were open in a certain timeframe.
+
+
+
+
+## Interacting with Incidents
+
+An incident has a status, assignee and severity.
+These can be set in the Incidents page, or from an alert in integrations that support alert actions.
+
+- **Incident status**: Will be set to `open` by default, and can be changed to `Acknowledged` and back to `Open`. When an alert is manually or automatically set as `Resolved`, it will close and will no longer be modified.
+- **Incident assignee**: An incident can be assigned to any user on the team, and they will be notified.
+ - If you assign an incident to a user, it is recommended to leave the incident `Open` until the user changes status to `Acknowledged`.
+- **Incident severity**: Severity of an incident can be Low, Normal, High or Critical. By default, model errors are set to Critical, test failures set to High and warnings are marked as Normal, but the severity can be changed manually. _Coming soon_ : Severity will be automated by an analysis of the impacted assets.
+
+ +
+
+
+ +
+ +
+  +
+  +
+  +
+  +
+ +
+
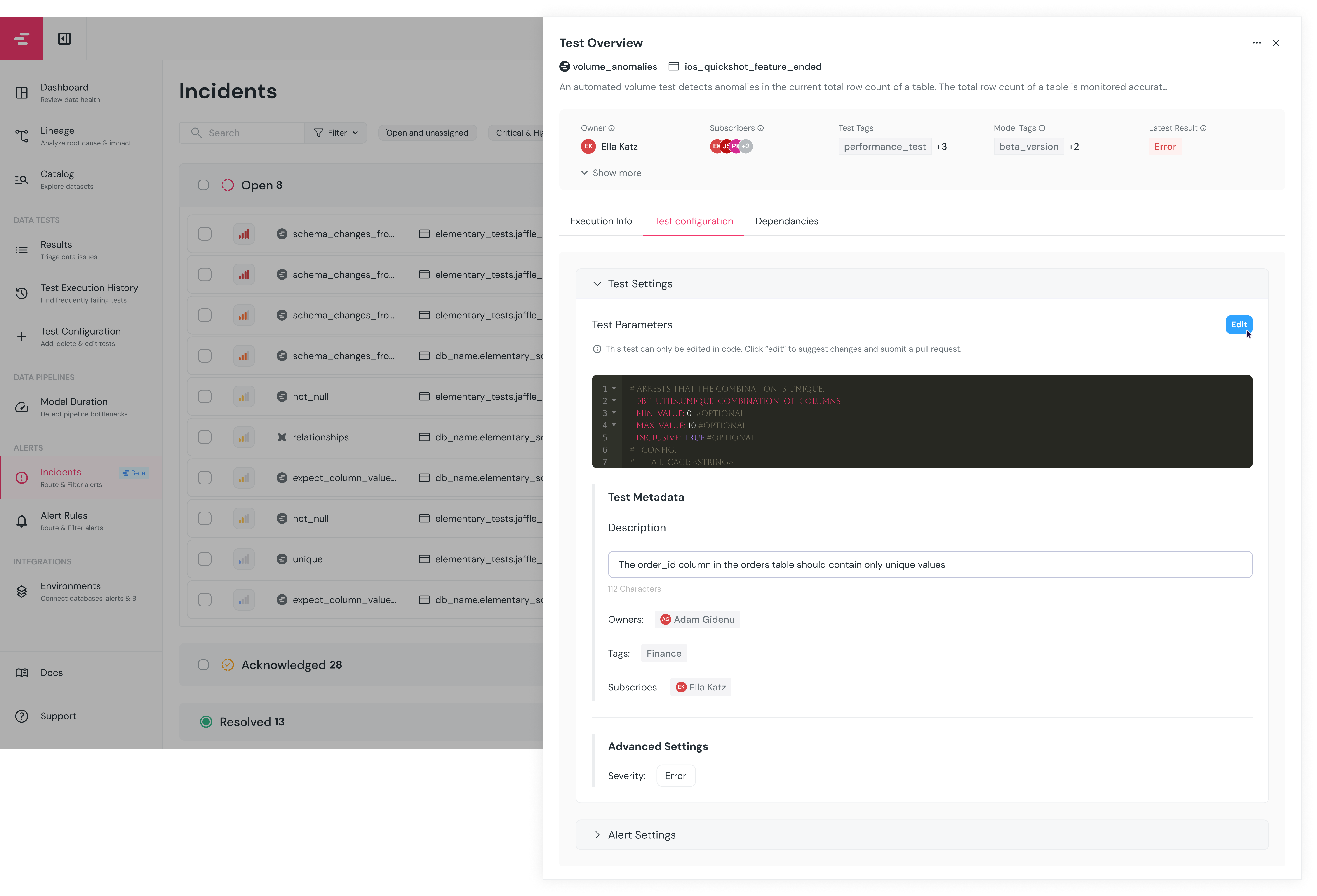
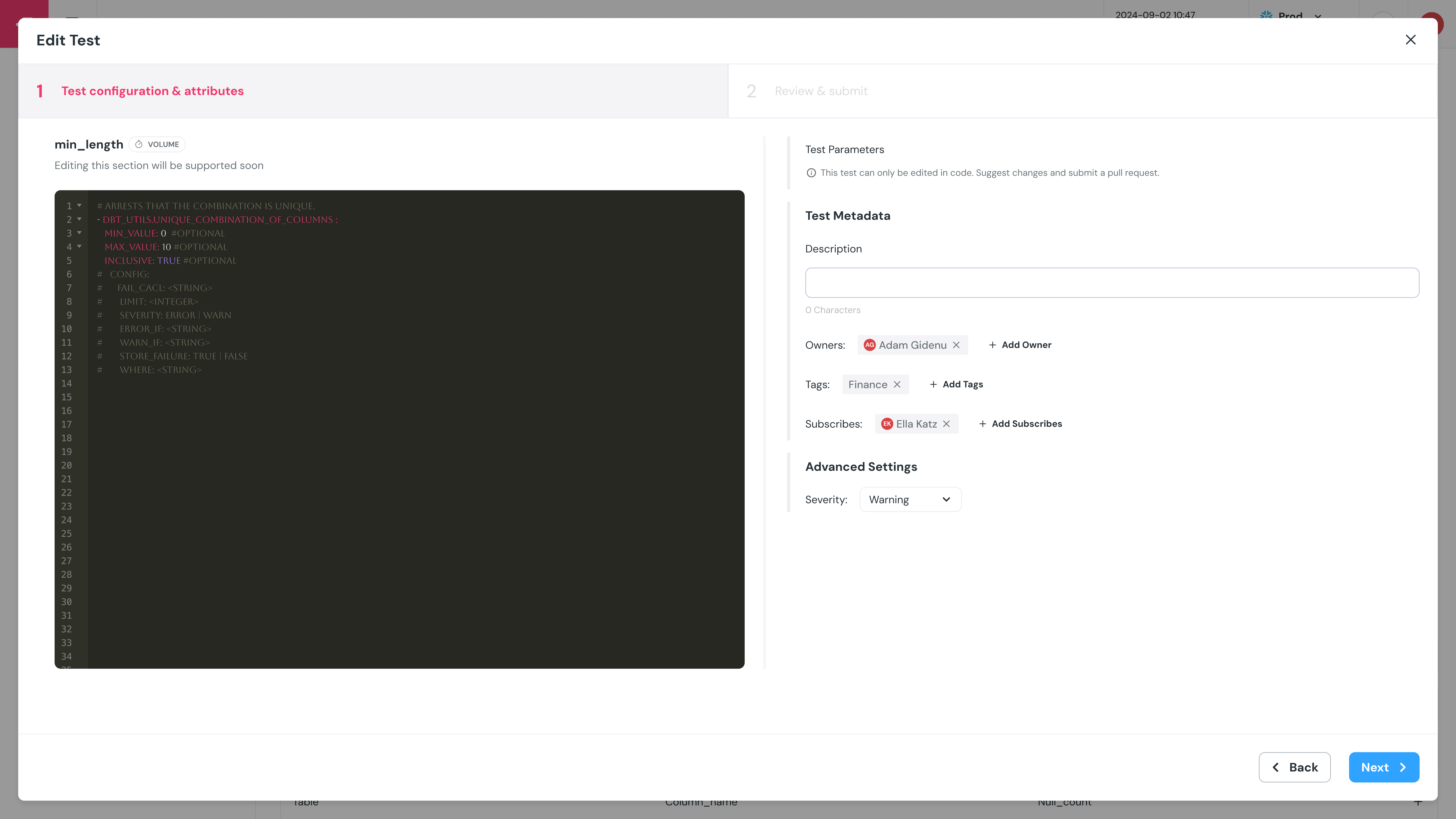
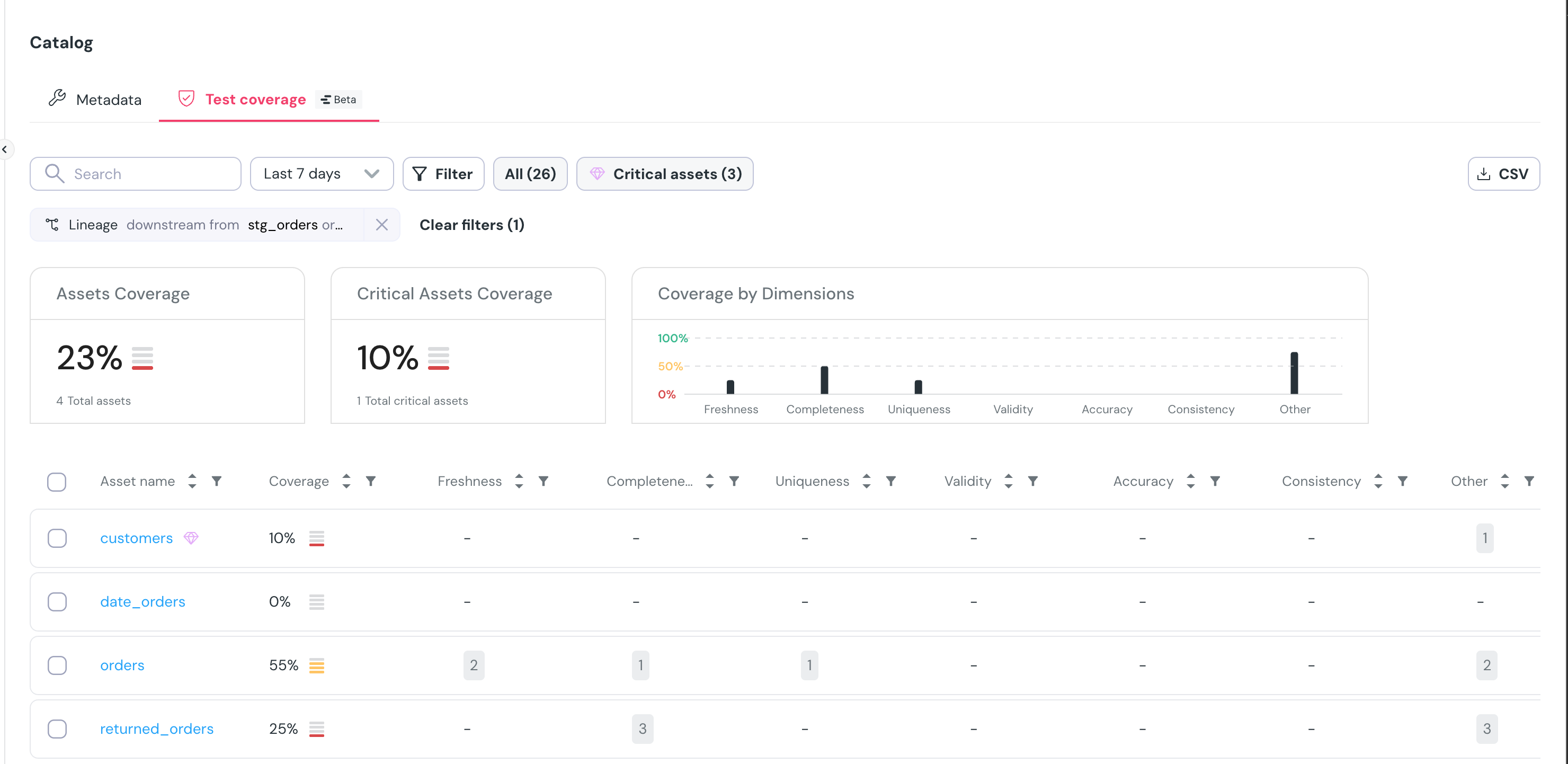
+## How to set up a data content metric?
+
+The monitored metrics are set up in the code, in a way similar to dbt tests.
+
+
+
+
+No mandatory configuration, however it is highly recommended to configure a `timestamp_column`.
+
+{/* prettier-ignore */}
+
+
+
+## How to set up a data content metric?
+
+The monitored metrics are set up in the code, in a way similar to dbt tests.
+
+
+
+
+No mandatory configuration, however it is highly recommended to configure a `timestamp_column`.
+
+{/* prettier-ignore */}
+
+
+ data_tests:
+ -- elementary.collect_metrics:
+ arguments:
+ timestamp_column: column name
+ time_bucket:
+ period: [hour | day]
+ count: int
+ dimensions: sql expression
+ metrics: monitors list
+ name: string
+ type: monitor type
+ columns: list
+ where_expression: sql expression
+
+
+
+ +
+
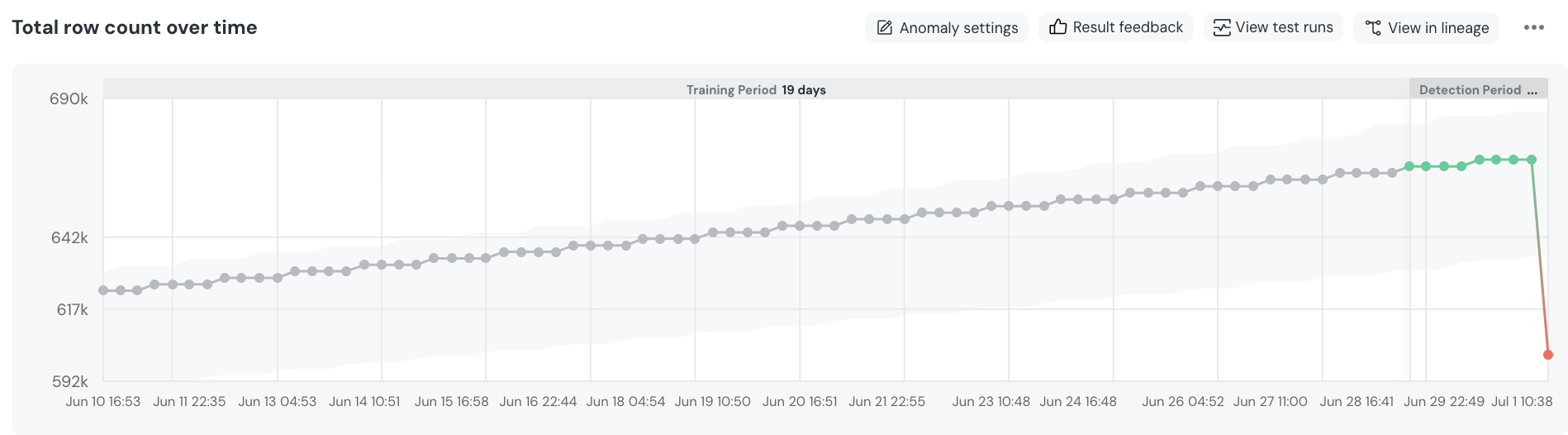
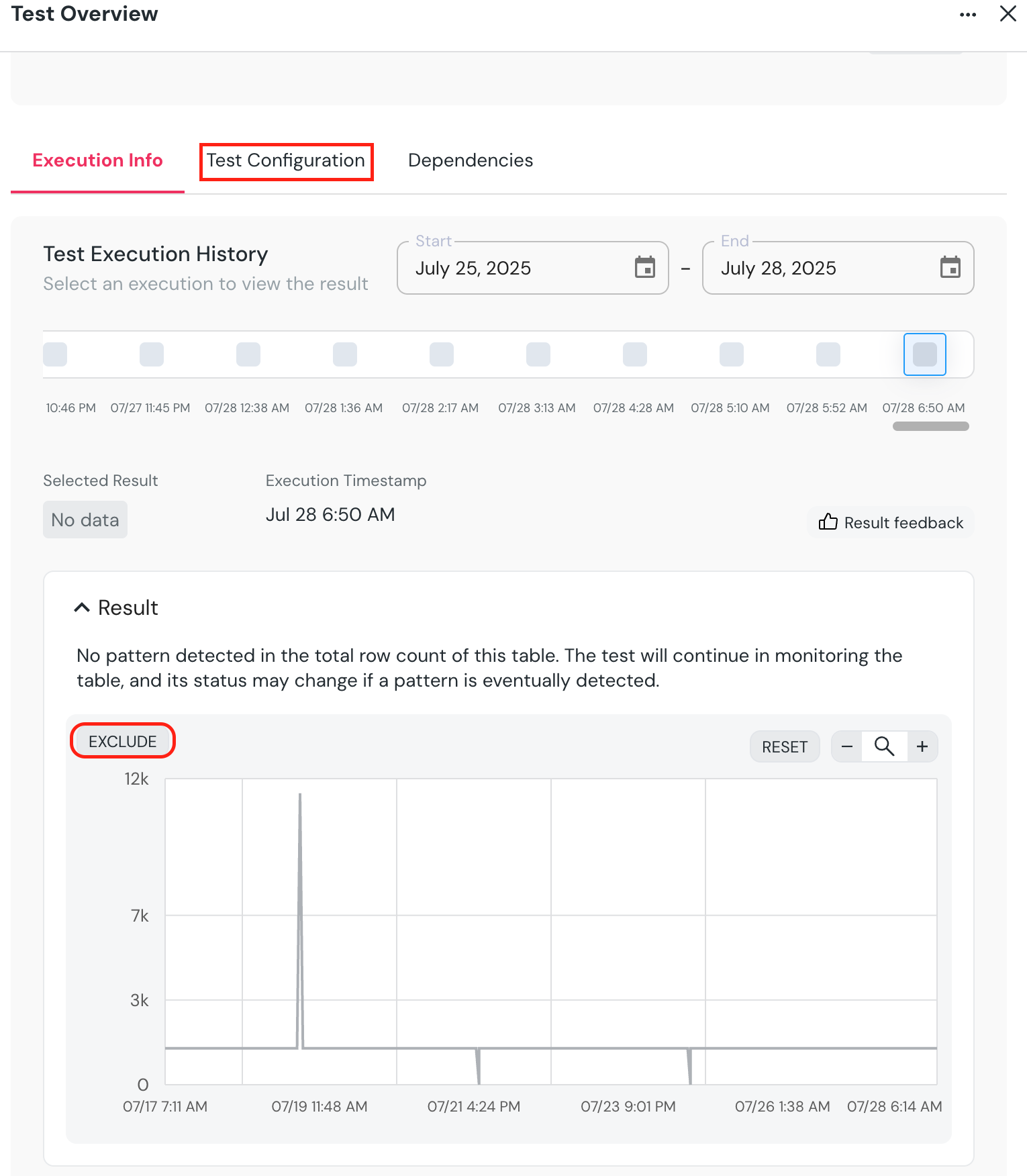
+- Go down the chart, click `EXCLUDE`, and mark the section you want to exclude.
+ - A confirmation dialog will appear, showing the exact samples which will be excluded.
+- On confirmation, the new excluded time range will appear under **`Excluded time ranges`.** You can modify or remove it, and you can also add new ranges using the + sign if you prefer.
+- To test the configuration, click “Simulate configuration”.
+
+
+
+
+- Go down the chart, click `EXCLUDE`, and mark the section you want to exclude.
+ - A confirmation dialog will appear, showing the exact samples which will be excluded.
+- On confirmation, the new excluded time range will appear under **`Excluded time ranges`.** You can modify or remove it, and you can also add new ranges using the + sign if you prefer.
+- To test the configuration, click “Simulate configuration”.
+
+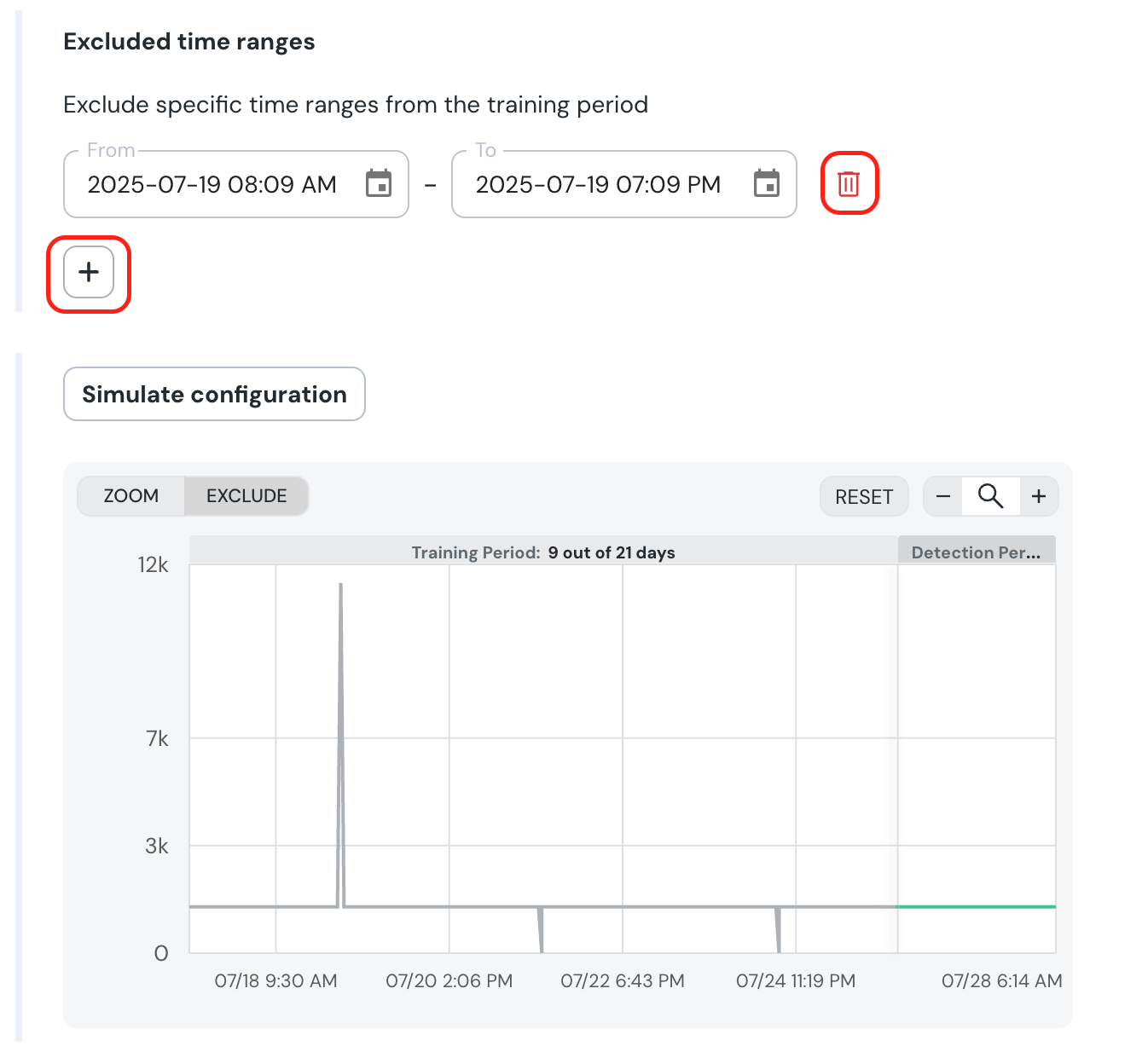 +
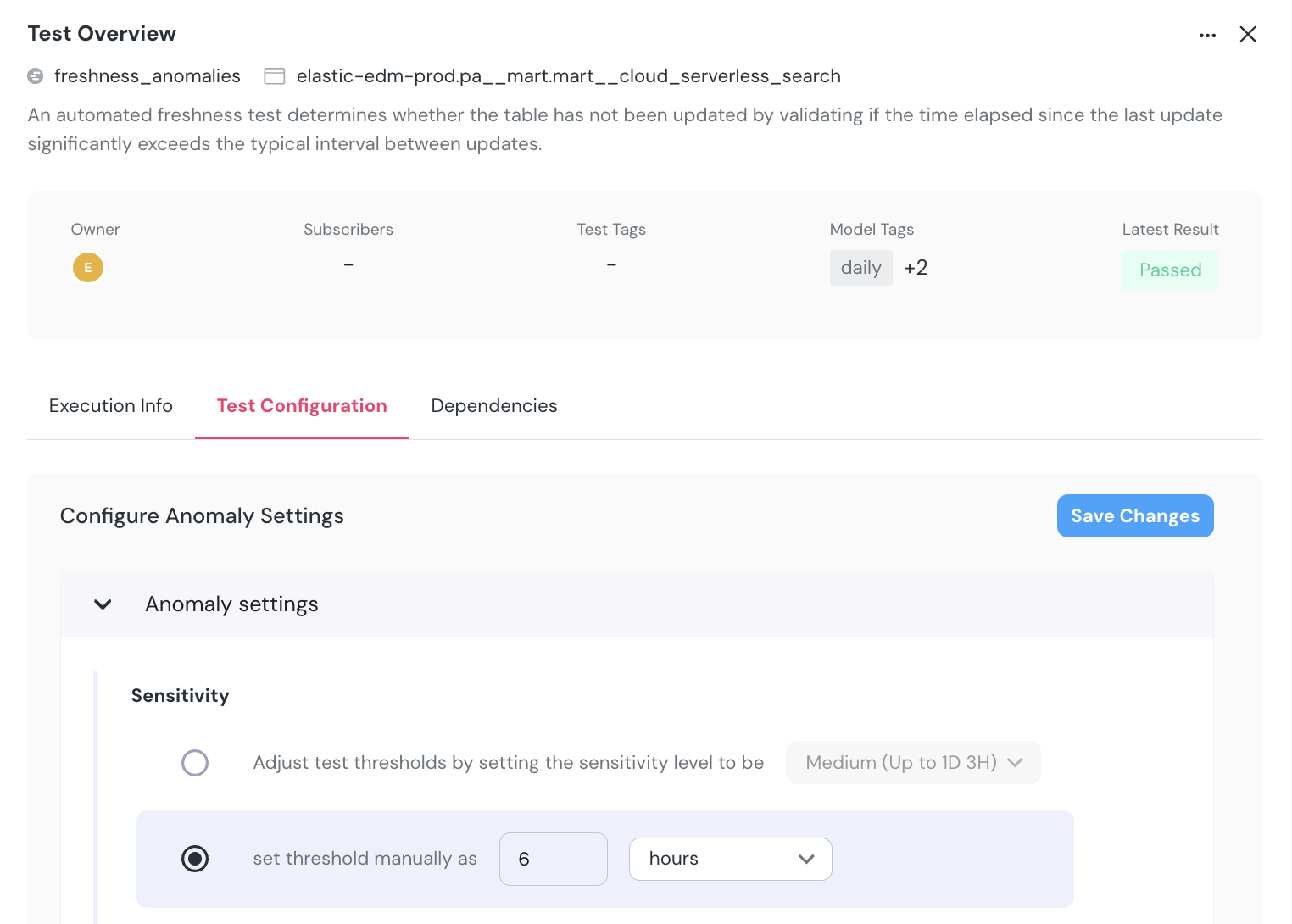
+## Remove anomaly detection monitors
+
+There are two ways to delete monitors from the UI.
+- Test configuration page - Choose one or more tests, and an option to delete them will be available at the bottom of the page.
+- Test results page - Press the `...` button on the top right of the test result and then `Delete test`.
+
+
+
+## Supported settings
+
+#### All monitors
+
+
+
+## Remove anomaly detection monitors
+
+There are two ways to delete monitors from the UI.
+- Test configuration page - Choose one or more tests, and an option to delete them will be available at the bottom of the page.
+- Test results page - Press the `...` button on the top right of the test result and then `Delete test`.
+
+
+
+## Supported settings
+
+#### All monitors
+
+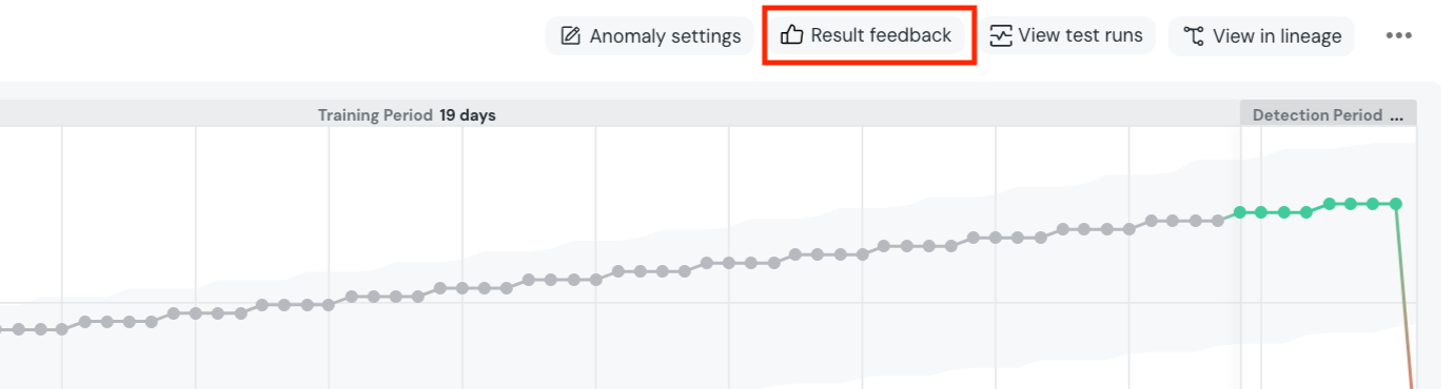 +
+  +
+  +
+  +
+  +
+  +
+### Editing Metadata
+You can edit metadata directly in the catalog. This includes updating model and column descriptions, assigning owners, and applying tags.
+To make updates more efficient, the catalog supports bulk editing. For example, you can assign an owner to multiple models at once or apply a shared tag to a group of assets.
+All metadata edits are synced back into your dbt project as a pull request, so documentation stays version-controlled and part of your workflow.
+
+Need to display additional metadata fields from your dbt `meta` config? Reach out to our team to customize the catalog with fields that best fit your data workflows.
+
+### Marking Critical Assets
+You can mark assets as critical directly in the catalog to highlight their importance. Critical assets are prioritized in monitoring and surfaced in governance views to help teams focus on what matters most. Read more [here](/cloud/features/data-governance/critical_assets).
+
+
+### Editing Metadata
+You can edit metadata directly in the catalog. This includes updating model and column descriptions, assigning owners, and applying tags.
+To make updates more efficient, the catalog supports bulk editing. For example, you can assign an owner to multiple models at once or apply a shared tag to a group of assets.
+All metadata edits are synced back into your dbt project as a pull request, so documentation stays version-controlled and part of your workflow.
+
+Need to display additional metadata fields from your dbt `meta` config? Reach out to our team to customize the catalog with fields that best fit your data workflows.
+
+### Marking Critical Assets
+You can mark assets as critical directly in the catalog to highlight their importance. Critical assets are prioritized in monitoring and surfaced in governance views to help teams focus on what matters most. Read more [here](/cloud/features/data-governance/critical_assets).
+ +
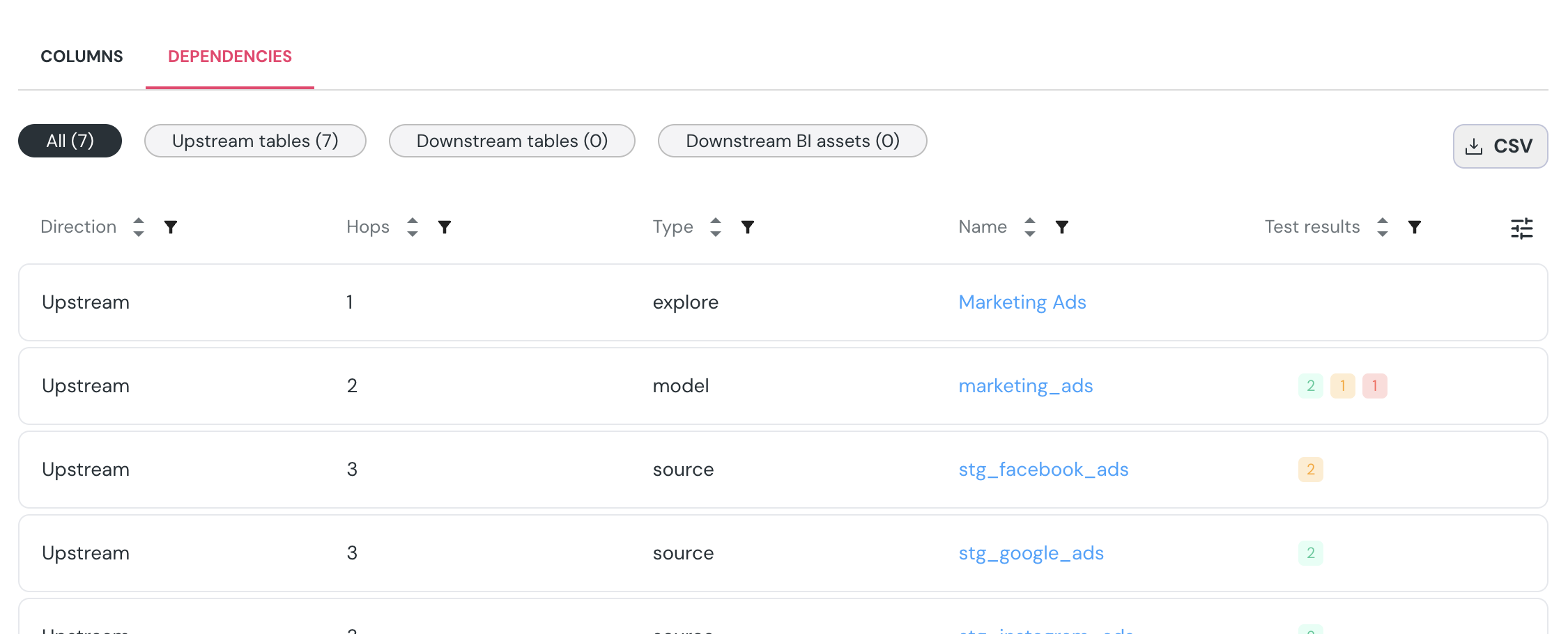
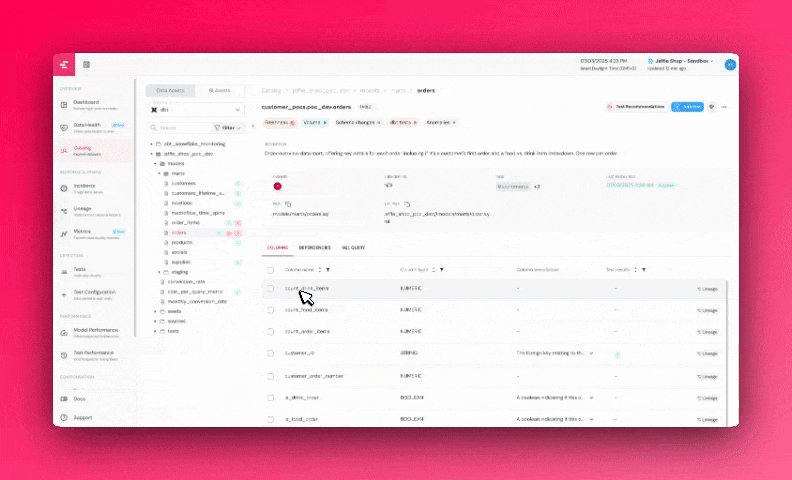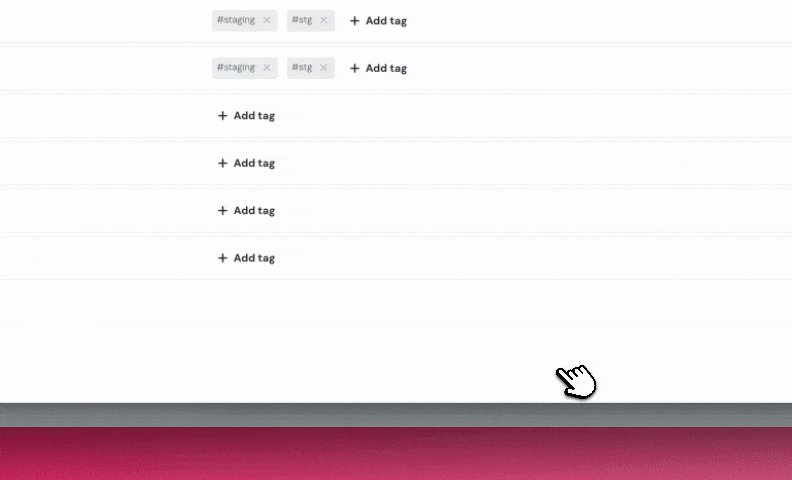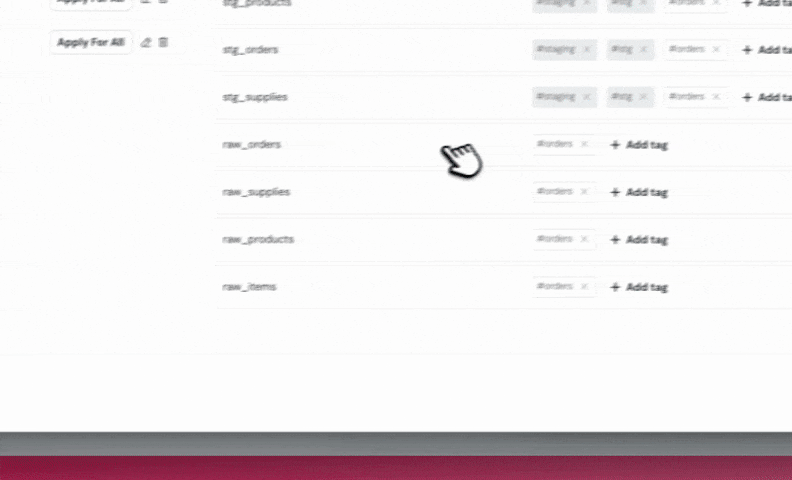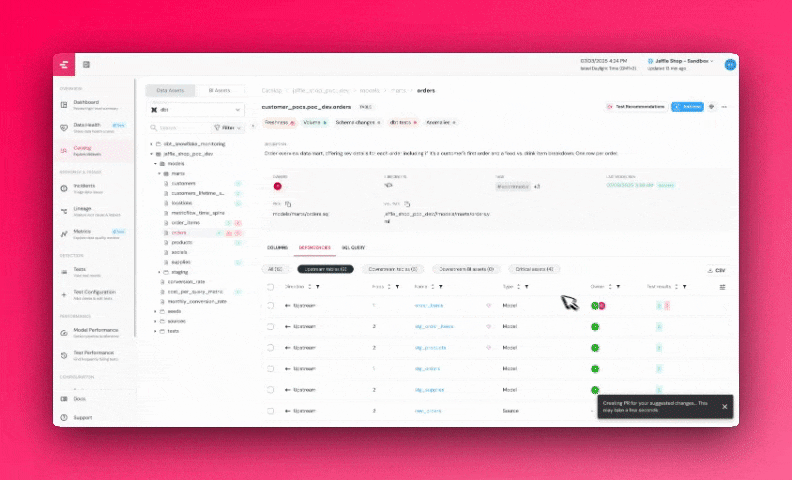
+### Lineage & Dependency Export
+View upstream and downstream dependencies for each dataset, and export the full dependency list as a CSV for further analysis or documentation.
+
+
+### Lineage & Dependency Export
+View upstream and downstream dependencies for each dataset, and export the full dependency list as a CSV for further analysis or documentation.
+ +
+### AI Agents for Discovery and Governance
+Elementary includes two agents that use the catalog to support your team:
+- The [Catalog agent](/cloud/ai-agents/catalog-agent) helps users find relevant models, columns, or metrics using natural language. This is especially helpful for new team members or business users who are less familiar with your dbt structure.
+- The [Governance agent](/cloud/ai-agents/governance-agent) identifies missing documentation, unowned assets, or inconsistent tags. It surfaces these issues automatically and can suggest actions to improve coverage.
+These agents run continuously and help keep the catalog useful and complete without requiring constant manual work.
diff --git a/docs/cloud/features/collaboration-and-communication/data-health.mdx b/docs/cloud/features/collaboration-and-communication/data-health.mdx
new file mode 100644
index 000000000..30b044304
--- /dev/null
+++ b/docs/cloud/features/collaboration-and-communication/data-health.mdx
@@ -0,0 +1,74 @@
+---
+title: Data Health Dashboard
+sidebarTitle: Data Health Dashboard
+---
+
+import DataHealthIntro from '/snippets/cloud/features/data-health/data-health-intro.mdx';
+import DataQualityDimensions from '/snippets/cloud/features/data-health/data-quality-dimensions.mdx';
+
+
+
+### AI Agents for Discovery and Governance
+Elementary includes two agents that use the catalog to support your team:
+- The [Catalog agent](/cloud/ai-agents/catalog-agent) helps users find relevant models, columns, or metrics using natural language. This is especially helpful for new team members or business users who are less familiar with your dbt structure.
+- The [Governance agent](/cloud/ai-agents/governance-agent) identifies missing documentation, unowned assets, or inconsistent tags. It surfaces these issues automatically and can suggest actions to improve coverage.
+These agents run continuously and help keep the catalog useful and complete without requiring constant manual work.
diff --git a/docs/cloud/features/collaboration-and-communication/data-health.mdx b/docs/cloud/features/collaboration-and-communication/data-health.mdx
new file mode 100644
index 000000000..30b044304
--- /dev/null
+++ b/docs/cloud/features/collaboration-and-communication/data-health.mdx
@@ -0,0 +1,74 @@
+---
+title: Data Health Dashboard
+sidebarTitle: Data Health Dashboard
+---
+
+import DataHealthIntro from '/snippets/cloud/features/data-health/data-health-intro.mdx';
+import DataQualityDimensions from '/snippets/cloud/features/data-health/data-quality-dimensions.mdx';
+
+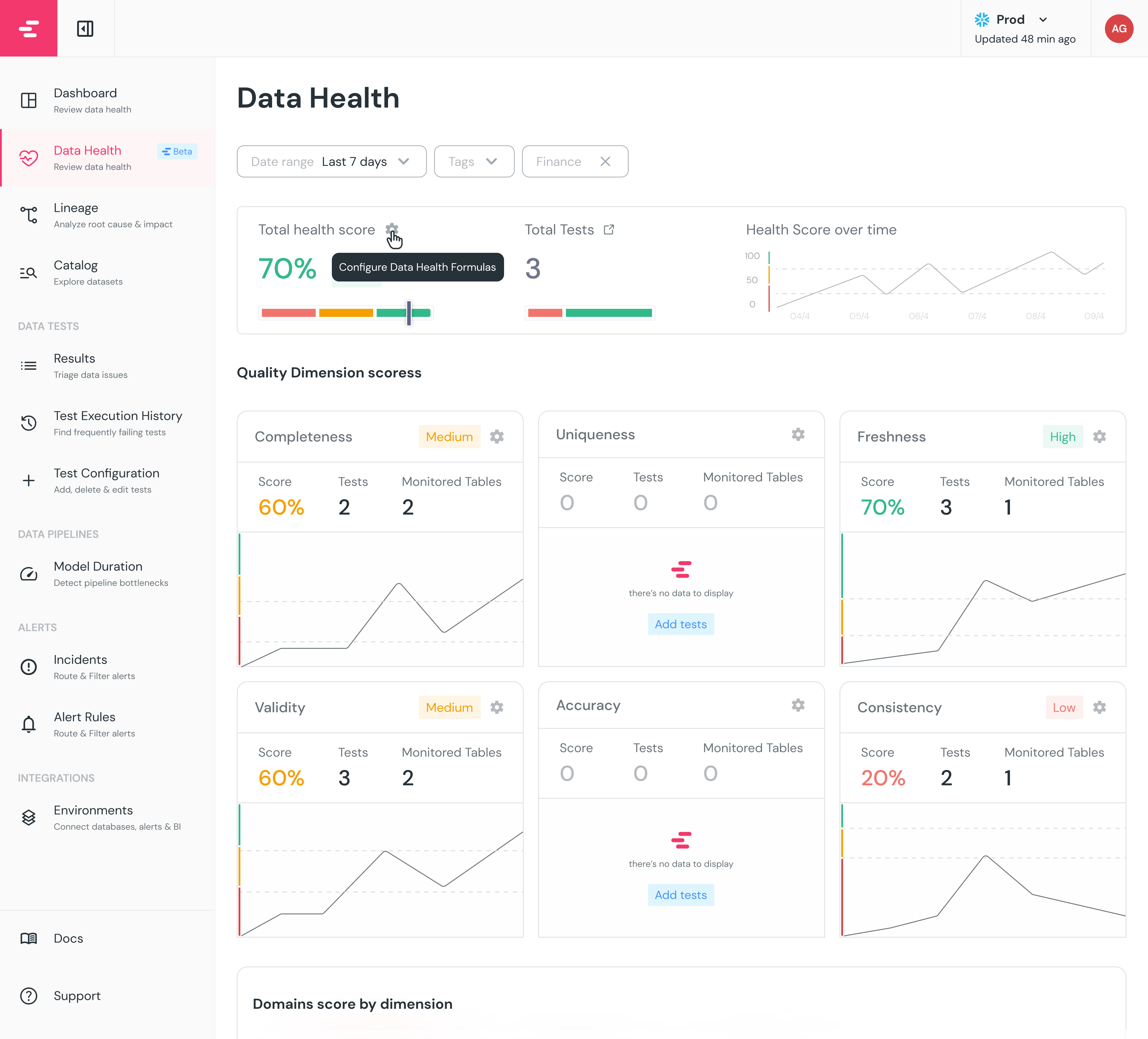 +
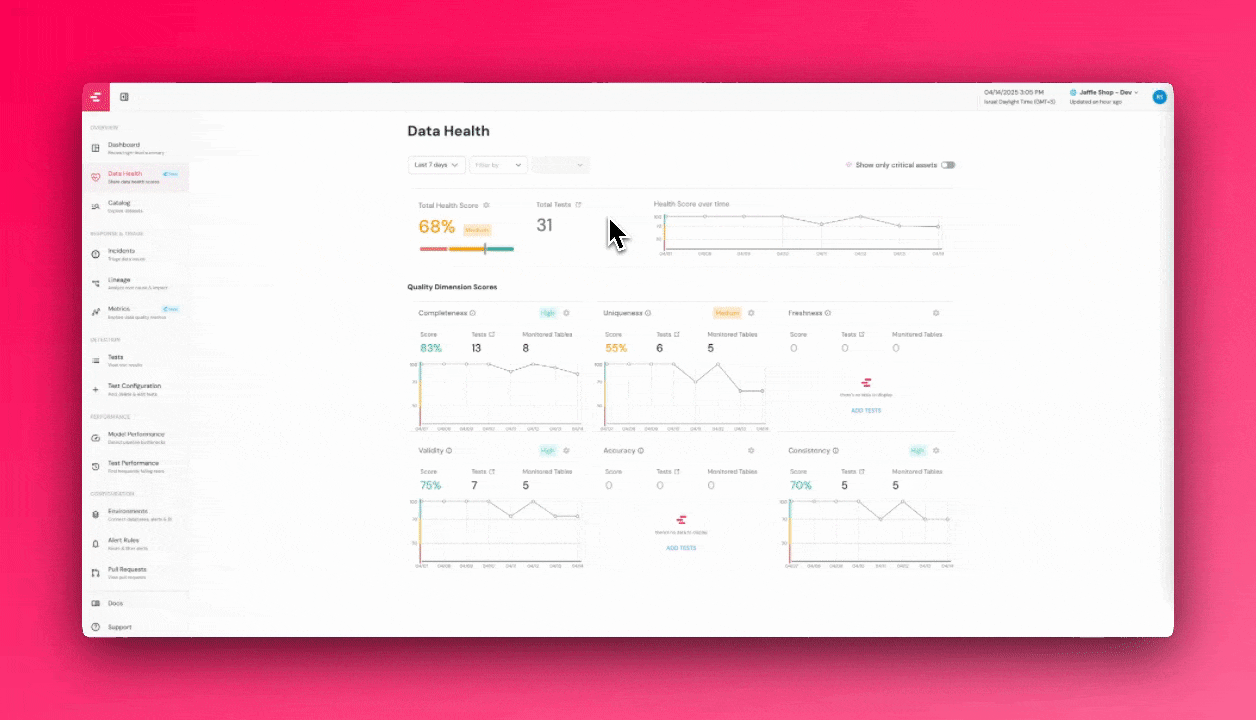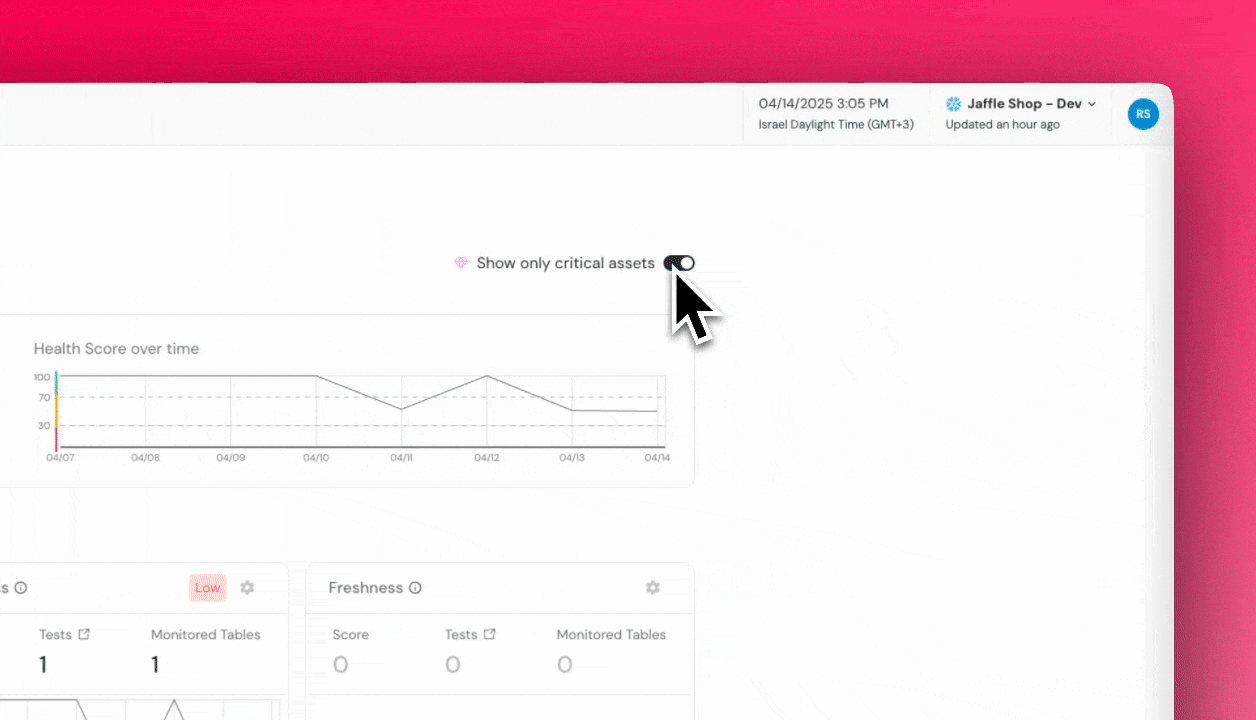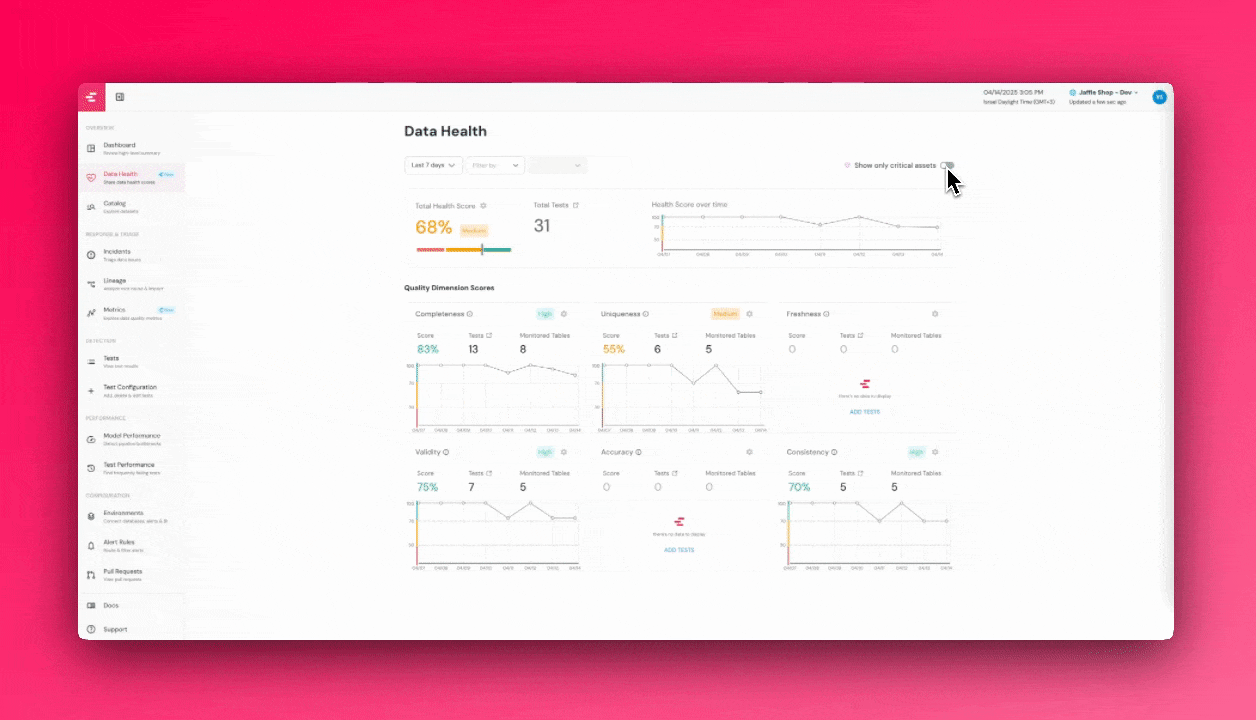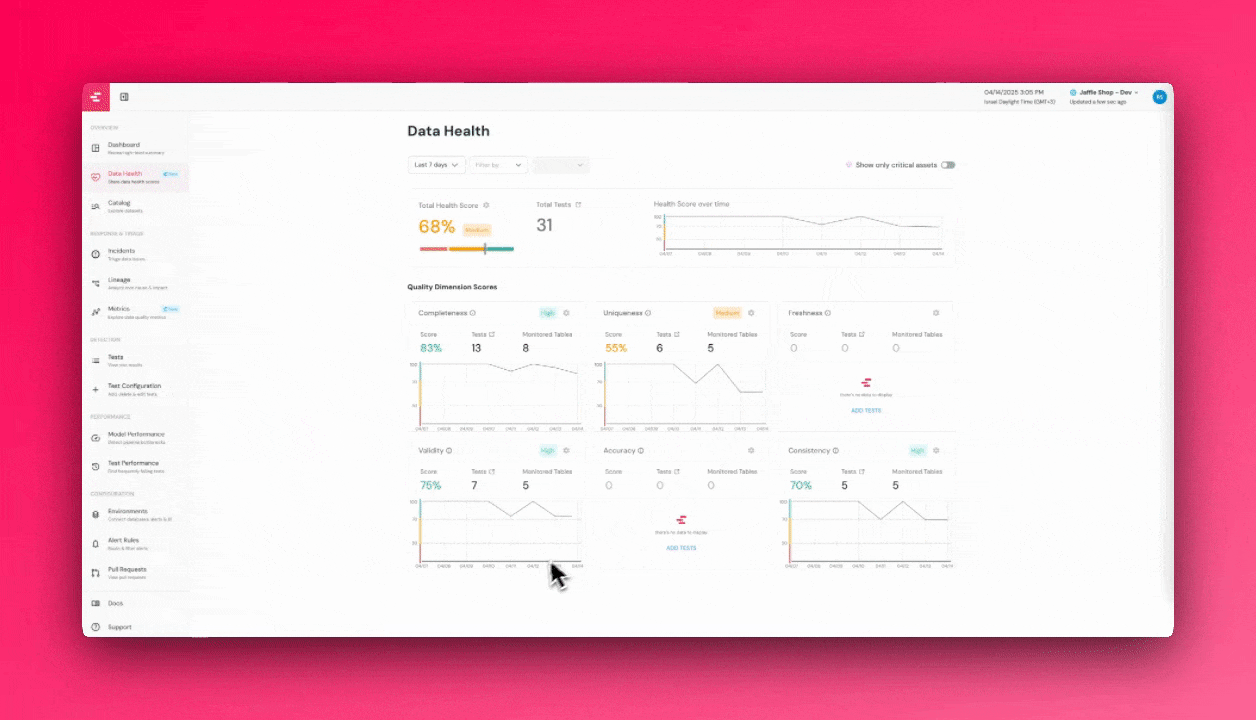
+The dashboard is based on the 6 [Data Quality Dimensions](/cloud/features/collaboration-and-communication/data-quality-dimensions#data-quality-dimensions):
+
+
+
+The dashboard is based on the 6 [Data Quality Dimensions](/cloud/features/collaboration-and-communication/data-quality-dimensions#data-quality-dimensions):
+
+ +
+### Critical assets alerts score
+
+To focus on what matters most, see the top right of the screen to filter on your [critical assets](/cloud/features/data-governance/critical_assets).
+
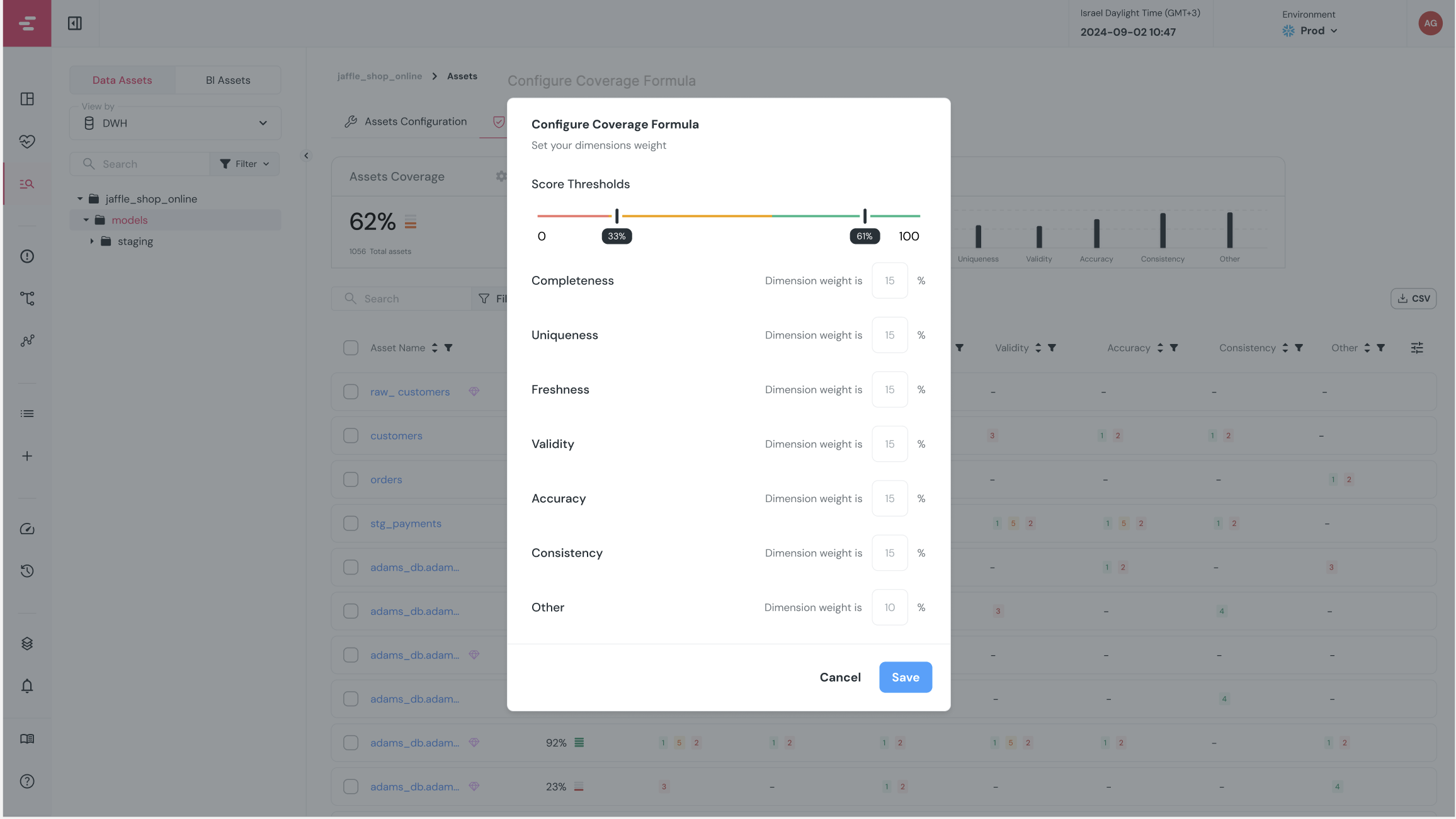
+### Can I customize the quality dimension mapping of my tests?
+
+Of course!
+Each test you run, whether it's a generic or a custom test, can be mapped to one of the 6 quality dimensions.
+The way to do so is to add `quality_dimension` to the test definition in your dbt project:
+
+
+
+### Critical assets alerts score
+
+To focus on what matters most, see the top right of the screen to filter on your [critical assets](/cloud/features/data-governance/critical_assets).
+
+### Can I customize the quality dimension mapping of my tests?
+
+Of course!
+Each test you run, whether it's a generic or a custom test, can be mapped to one of the 6 quality dimensions.
+The way to do so is to add `quality_dimension` to the test definition in your dbt project:
+
+ +
\ No newline at end of file
diff --git a/docs/cloud/features/collaboration-and-communication/data-quality-dimensions.mdx b/docs/cloud/features/collaboration-and-communication/data-quality-dimensions.mdx
new file mode 100644
index 000000000..c31a723cd
--- /dev/null
+++ b/docs/cloud/features/collaboration-and-communication/data-quality-dimensions.mdx
@@ -0,0 +1,70 @@
+---
+title: Data Quality Dimensions
+sidebarTitle: Data Quality Dimensions
+---
+
+import DataHealthIntro from '/snippets/cloud/features/data-health/data-health-intro.mdx';
+import DataQualityDimensions from '/snippets/cloud/features/data-health/data-quality-dimensions.mdx';
+
+
+
+## Measuring data quality
+
+
+
\ No newline at end of file
diff --git a/docs/cloud/features/collaboration-and-communication/data-quality-dimensions.mdx b/docs/cloud/features/collaboration-and-communication/data-quality-dimensions.mdx
new file mode 100644
index 000000000..c31a723cd
--- /dev/null
+++ b/docs/cloud/features/collaboration-and-communication/data-quality-dimensions.mdx
@@ -0,0 +1,70 @@
+---
+title: Data Quality Dimensions
+sidebarTitle: Data Quality Dimensions
+---
+
+import DataHealthIntro from '/snippets/cloud/features/data-health/data-health-intro.mdx';
+import DataQualityDimensions from '/snippets/cloud/features/data-health/data-quality-dimensions.mdx';
+
+
+
+## Measuring data quality
+
+ +
+
+
+## What Should Be Set as a Critical Asset?
+
+You should mark an asset as **critical** if:
+
+- It directly impacts key **business reports, dashboards, or decision-making tools**.
+- It serves as an essential **upstream dependency** for other important data models.
+- It is frequently used by **multiple teams or stakeholders**.
+- Its failure or inaccuracy could cause **significant business or operational risks**
+
+## Why Should I Define My Critical Assets?
+
+Defining your **critical assets** helps you:
+
+- **Quickly identify and respond to issues**– Get notified when upstream problems may impact your critical assets, ensuring faster resolution and minimal disruption.
+- **Prioritize issue resolution**– Focus on addressing incidents that have the greatest impact on business operations, dashboards, and decision-making.
+- **Improve data reliability**– Ensure key stakeholders have access to accurate and up-to-date data by monitoring critical assets more effectively.
+- **Enhance observability**– Gain better visibility into the health of your most important assets through prioritized monitoring and alerting.
+
+## How to Set a Critical Asset?
+
+You can mark an asset as **critical** directly in the UI:
+
+- **From the Catalog Page** – Navigate to the asset in the catalog and click the **diamond icon** to **"Set as Critical Asset."**
+- **From the Lineage View** – Right-click on the node representing the asset and select **"Set as Critical Asset"** from the list.
+
+Once an asset is marked as critical, **alerts will now highlight any issues that may impact this asset or its upstream dependencies, ensuring prioritization.**
+
+
+
+## Where Can You See Critical Assets?
+
+Once an asset is marked as **critical**, you will be able to:
+
+- **Identify it in the UI**, where it will be visually highlighted.
+- **Receive alerts** when upstream issues may impact the critical asset.
+- **Filter incidents** by their impact on critical assets.
+- **Track health scores of critical data assets** over time through dashboard monitoring.
+
+
+
+
+
+## What Should Be Set as a Critical Asset?
+
+You should mark an asset as **critical** if:
+
+- It directly impacts key **business reports, dashboards, or decision-making tools**.
+- It serves as an essential **upstream dependency** for other important data models.
+- It is frequently used by **multiple teams or stakeholders**.
+- Its failure or inaccuracy could cause **significant business or operational risks**
+
+## Why Should I Define My Critical Assets?
+
+Defining your **critical assets** helps you:
+
+- **Quickly identify and respond to issues**– Get notified when upstream problems may impact your critical assets, ensuring faster resolution and minimal disruption.
+- **Prioritize issue resolution**– Focus on addressing incidents that have the greatest impact on business operations, dashboards, and decision-making.
+- **Improve data reliability**– Ensure key stakeholders have access to accurate and up-to-date data by monitoring critical assets more effectively.
+- **Enhance observability**– Gain better visibility into the health of your most important assets through prioritized monitoring and alerting.
+
+## How to Set a Critical Asset?
+
+You can mark an asset as **critical** directly in the UI:
+
+- **From the Catalog Page** – Navigate to the asset in the catalog and click the **diamond icon** to **"Set as Critical Asset."**
+- **From the Lineage View** – Right-click on the node representing the asset and select **"Set as Critical Asset"** from the list.
+
+Once an asset is marked as critical, **alerts will now highlight any issues that may impact this asset or its upstream dependencies, ensuring prioritization.**
+
+
+
+## Where Can You See Critical Assets?
+
+Once an asset is marked as **critical**, you will be able to:
+
+- **Identify it in the UI**, where it will be visually highlighted.
+- **Receive alerts** when upstream issues may impact the critical asset.
+- **Filter incidents** by their impact on critical assets.
+- **Track health scores of critical data assets** over time through dashboard monitoring.
+
+ +
+By carefully selecting which assets to mark as critical, you can quickly detect and prioritize issues that impact your most important data, reducing disruptions, improving reliability, and keeping key stakeholders informed.
diff --git a/docs/cloud/features/data-governance/manage-metadata.mdx b/docs/cloud/features/data-governance/manage-metadata.mdx
new file mode 100644
index 000000000..e5160de80
--- /dev/null
+++ b/docs/cloud/features/data-governance/manage-metadata.mdx
@@ -0,0 +1,78 @@
+---
+title: "Manage metadata"
+---
+
+Manage your metadata directly from the [Elementary Catalog](/cloud/features/collaboration-and-communication/catalog), with no need to update code manually. This streamlines governance workflows, reduces manual effort, and improves visibility and consistency across your assets.
+
+From a single interface, you can view and filter assets, edit metadata fields individually or in bulk, edit metadata for related assets and even use [AI to generate high-quality descriptions](/cloud/features/data-governance/ai-descriptions)—saving time and enhancing data discoverability. All changes are version-controlled via pull requests to keep your dbt project in sync.
+
+To get the most out of this feature, check out our [Data Governance Best Practices](/cloud/best-practices/governance-for-observability) guide.
+
+
+
+## Overview
+
+Managing metadata such as owners, tags, descriptions, and critical asset status is essential for effective data governance. With Elementary you can:
+
+- View all your assets and their metadata in a centralized table
+- Identify governance gaps and inconsistencies
+- Edit metadata fields individually or in bulk
+- Generate high-quality asset descriptions using AI
+- Create pull requests for metadata changes directly from the UI
+- Track pending changes awaiting approval
+
+### Supported Metadata Fields
+
+Elementary supports editing the following metadata fields:
+
+- **Tags** - Categorize and organize assets
+- **Owners** - Assign responsibility for assets
+- **Descriptions** - Provide context about asset purpose and usage
+- **Critical Assets** - Mark high-priority assets
+
+Coming soon:
+
+- **Subscribers** - Add users who should be notified about changes
+- **Custom Metadata Fields** - Edit organization-specific metadata
+
+## Editing Metadata
+
+Elementary allows you to edit metadata for individual assets or in bulk, with changes reflected in your dbt project through pull requests.
+
+### How to Edit Metadata
+
+To edit metadata:
+
+1. In the Catalog page select any folder for getting into the assets Table
+2. Select the assets you want to modify
+3. Choose which metadata field to edit and click on the right field (Tags, Owners, Description, etc.)
+4. Make your changes in the editing wizard
+5. Review the changes summary
+6. Click "Submit Pull Request" to submit your changes
+
+
+### Editing Metadata for Related Assets
+From the Dependencies tab in the Catalog, you can efficiently apply metadata to all upstream and downstream assets of a selected asset in a single action.
+
+
+
+By carefully selecting which assets to mark as critical, you can quickly detect and prioritize issues that impact your most important data, reducing disruptions, improving reliability, and keeping key stakeholders informed.
diff --git a/docs/cloud/features/data-governance/manage-metadata.mdx b/docs/cloud/features/data-governance/manage-metadata.mdx
new file mode 100644
index 000000000..e5160de80
--- /dev/null
+++ b/docs/cloud/features/data-governance/manage-metadata.mdx
@@ -0,0 +1,78 @@
+---
+title: "Manage metadata"
+---
+
+Manage your metadata directly from the [Elementary Catalog](/cloud/features/collaboration-and-communication/catalog), with no need to update code manually. This streamlines governance workflows, reduces manual effort, and improves visibility and consistency across your assets.
+
+From a single interface, you can view and filter assets, edit metadata fields individually or in bulk, edit metadata for related assets and even use [AI to generate high-quality descriptions](/cloud/features/data-governance/ai-descriptions)—saving time and enhancing data discoverability. All changes are version-controlled via pull requests to keep your dbt project in sync.
+
+To get the most out of this feature, check out our [Data Governance Best Practices](/cloud/best-practices/governance-for-observability) guide.
+
+
+
+## Overview
+
+Managing metadata such as owners, tags, descriptions, and critical asset status is essential for effective data governance. With Elementary you can:
+
+- View all your assets and their metadata in a centralized table
+- Identify governance gaps and inconsistencies
+- Edit metadata fields individually or in bulk
+- Generate high-quality asset descriptions using AI
+- Create pull requests for metadata changes directly from the UI
+- Track pending changes awaiting approval
+
+### Supported Metadata Fields
+
+Elementary supports editing the following metadata fields:
+
+- **Tags** - Categorize and organize assets
+- **Owners** - Assign responsibility for assets
+- **Descriptions** - Provide context about asset purpose and usage
+- **Critical Assets** - Mark high-priority assets
+
+Coming soon:
+
+- **Subscribers** - Add users who should be notified about changes
+- **Custom Metadata Fields** - Edit organization-specific metadata
+
+## Editing Metadata
+
+Elementary allows you to edit metadata for individual assets or in bulk, with changes reflected in your dbt project through pull requests.
+
+### How to Edit Metadata
+
+To edit metadata:
+
+1. In the Catalog page select any folder for getting into the assets Table
+2. Select the assets you want to modify
+3. Choose which metadata field to edit and click on the right field (Tags, Owners, Description, etc.)
+4. Make your changes in the editing wizard
+5. Review the changes summary
+6. Click "Submit Pull Request" to submit your changes
+
+
+### Editing Metadata for Related Assets
+From the Dependencies tab in the Catalog, you can efficiently apply metadata to all upstream and downstream assets of a selected asset in a single action.
+
+ +
+## Governance Dashboard (Coming soon)
+
+The Governance Dashboard provides insights into your data governance structure, helping you identify gaps and inconsistencies at a glance.
+
+
+
+## Governance Dashboard (Coming soon)
+
+The Governance Dashboard provides insights into your data governance structure, helping you identify gaps and inconsistencies at a glance.
+
+ +
+### Dashboard Features
+
+- **Tag Distribution Analysis** - Visualize tag coverage across assets and identify areas needing better categorization
+- **Ownership Coverage** - Track asset ownership distribution and highlight resources requiring owner assignment
+- **Description Status** - Monitor assets with missing or incomplete descriptions to improve documentation
+- **Critical Asset Tracking** - Get an overview of your business-critical data assets and their governance status
+- **Dynamic Filtering** - Filter the Assets Table in real-time based on dashboard selections and metrics
diff --git a/docs/cloud/features/data-lineage/column-level-lineage.mdx b/docs/cloud/features/data-lineage/column-level-lineage.mdx
new file mode 100644
index 000000000..3b6479e6e
--- /dev/null
+++ b/docs/cloud/features/data-lineage/column-level-lineage.mdx
@@ -0,0 +1,46 @@
+---
+title: Column-Level Lineage
+sidebarTitle: Column level lineage
+---
+
+The table nodes in Elementary lineage can be expanded to show the columns. When you
+select a column, the lineage of that specific column will be highlighted.
+
+Column-level lineage is useful for answering questions such as:
+
+* Which downstream columns are actually impacted by a data quality issue?
+
+* Can we deprecate or rename a column?
+
+* Will changing this column impact a dashboard?
+
+### Filter and highlight columns path
+
+To help navigate graphs with large amount of columns per table, use the `...` menu to the right of the column:
+
+* **Filter**: Will show a graph of only the selected column and its dependencies.
+
+* **Highlight**: Will highlight only the selected column and its dependencies.
+
+
+
+### Column-level lineage generation
+
+Elementary parses SQL queries to determine the dependencies between columns.
+Note that the lineage is only of the columns that directly contribute data to the column.
+
+For example, for the query:
+
+```sql
+create or replace table db.schema.users as
+select
+ user_name,
+ count(distinct login_time) as total_logins
+from db.schema.login_events
+where user_type != 'test_user'
+```
+
+The direct dependency of `total_logins` is `login_events.login_time`.
+The column `login_events.user_type` filter the data of `total_logins`, but it is an indirect dependency and will not show in lineage.
+
+If you want a different approach in your Elementary Cloud instance - contact us.
\ No newline at end of file
diff --git a/docs/cloud/features/data-lineage/exposures-lineage.mdx b/docs/cloud/features/data-lineage/exposures-lineage.mdx
new file mode 100644
index 000000000..74c887b3a
--- /dev/null
+++ b/docs/cloud/features/data-lineage/exposures-lineage.mdx
@@ -0,0 +1,66 @@
+---
+title: Lineage to Downstream Dashboards and Tools
+sidebarTitle: Lineage to BI
+---
+
+import BiCards from '/snippets/cloud/integrations/cards-groups/bi-cards.mdx';
+
+
+
+Some of your data is used downstream in dashboards, applications, data science pipelines, reverse ETLs, etc.
+These downstream data consumers are called _exposures_.
+
+The Elementary lineage graph presents downstream exposures of two origins:
+
+1. Elementary automated BI integrations
+2. Exposures configured in your dbt project. Read about [how to configure exposures](https://docs.getdbt.com/docs/build/exposures) in code.
+
+
+
+### Dashboard Features
+
+- **Tag Distribution Analysis** - Visualize tag coverage across assets and identify areas needing better categorization
+- **Ownership Coverage** - Track asset ownership distribution and highlight resources requiring owner assignment
+- **Description Status** - Monitor assets with missing or incomplete descriptions to improve documentation
+- **Critical Asset Tracking** - Get an overview of your business-critical data assets and their governance status
+- **Dynamic Filtering** - Filter the Assets Table in real-time based on dashboard selections and metrics
diff --git a/docs/cloud/features/data-lineage/column-level-lineage.mdx b/docs/cloud/features/data-lineage/column-level-lineage.mdx
new file mode 100644
index 000000000..3b6479e6e
--- /dev/null
+++ b/docs/cloud/features/data-lineage/column-level-lineage.mdx
@@ -0,0 +1,46 @@
+---
+title: Column-Level Lineage
+sidebarTitle: Column level lineage
+---
+
+The table nodes in Elementary lineage can be expanded to show the columns. When you
+select a column, the lineage of that specific column will be highlighted.
+
+Column-level lineage is useful for answering questions such as:
+
+* Which downstream columns are actually impacted by a data quality issue?
+
+* Can we deprecate or rename a column?
+
+* Will changing this column impact a dashboard?
+
+### Filter and highlight columns path
+
+To help navigate graphs with large amount of columns per table, use the `...` menu to the right of the column:
+
+* **Filter**: Will show a graph of only the selected column and its dependencies.
+
+* **Highlight**: Will highlight only the selected column and its dependencies.
+
+
+
+### Column-level lineage generation
+
+Elementary parses SQL queries to determine the dependencies between columns.
+Note that the lineage is only of the columns that directly contribute data to the column.
+
+For example, for the query:
+
+```sql
+create or replace table db.schema.users as
+select
+ user_name,
+ count(distinct login_time) as total_logins
+from db.schema.login_events
+where user_type != 'test_user'
+```
+
+The direct dependency of `total_logins` is `login_events.login_time`.
+The column `login_events.user_type` filter the data of `total_logins`, but it is an indirect dependency and will not show in lineage.
+
+If you want a different approach in your Elementary Cloud instance - contact us.
\ No newline at end of file
diff --git a/docs/cloud/features/data-lineage/exposures-lineage.mdx b/docs/cloud/features/data-lineage/exposures-lineage.mdx
new file mode 100644
index 000000000..74c887b3a
--- /dev/null
+++ b/docs/cloud/features/data-lineage/exposures-lineage.mdx
@@ -0,0 +1,66 @@
+---
+title: Lineage to Downstream Dashboards and Tools
+sidebarTitle: Lineage to BI
+---
+
+import BiCards from '/snippets/cloud/integrations/cards-groups/bi-cards.mdx';
+
+
+
+Some of your data is used downstream in dashboards, applications, data science pipelines, reverse ETLs, etc.
+These downstream data consumers are called _exposures_.
+
+The Elementary lineage graph presents downstream exposures of two origins:
+
+1. Elementary automated BI integrations
+2. Exposures configured in your dbt project. Read about [how to configure exposures](https://docs.getdbt.com/docs/build/exposures) in code.
+
+ +
+  +
+  +
+ +
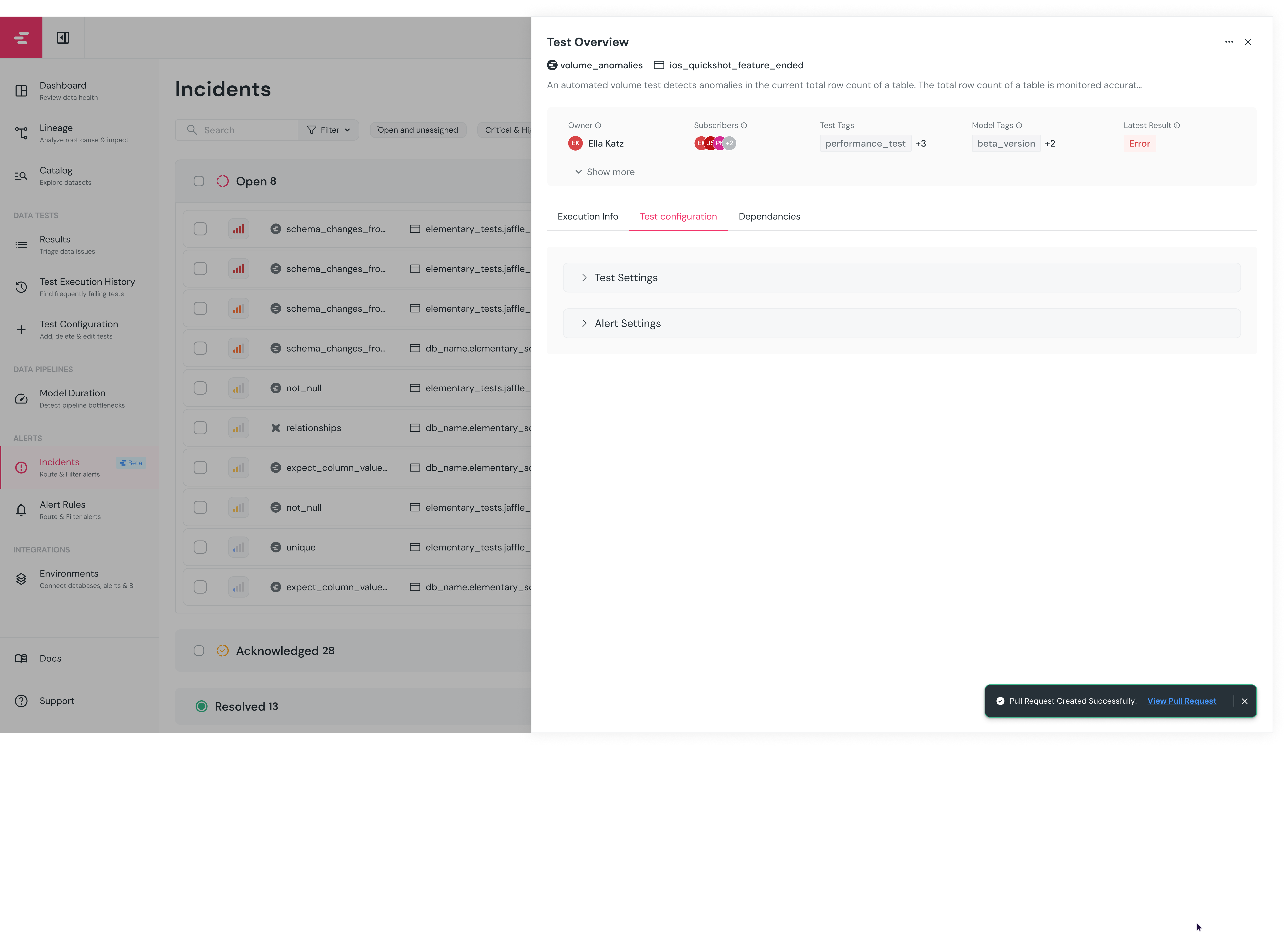
+A pull request will be opened in the code repository, and a link to the PR will be provided in the UI.
+
+
+A pull request will be opened in the code repository, and a link to the PR will be provided in the UI.
+ diff --git a/docs/cloud/features/data-tests/dbt-tests.mdx b/docs/cloud/features/data-tests/dbt-tests.mdx
new file mode 100644
index 000000000..00bcc258c
--- /dev/null
+++ b/docs/cloud/features/data-tests/dbt-tests.mdx
@@ -0,0 +1,36 @@
+---
+title: dbt, Packages and Elementary Tests
+sidebarTitle: dbt tests
+---
+
+import BenefitsDbtTests from '/snippets/cloud/features/data-tests/benefits-dbt-tests.mdx';
+import DbtTestHub from '/snippets/cloud/features/data-tests/dbt-test-hub.mdx';
+import TestsCards from '/snippets/data-tests/tests-cards.mdx';
+
+
+
+
diff --git a/docs/cloud/features/data-tests/dbt-tests.mdx b/docs/cloud/features/data-tests/dbt-tests.mdx
new file mode 100644
index 000000000..00bcc258c
--- /dev/null
+++ b/docs/cloud/features/data-tests/dbt-tests.mdx
@@ -0,0 +1,36 @@
+---
+title: dbt, Packages and Elementary Tests
+sidebarTitle: dbt tests
+---
+
+import BenefitsDbtTests from '/snippets/cloud/features/data-tests/benefits-dbt-tests.mdx';
+import DbtTestHub from '/snippets/cloud/features/data-tests/dbt-test-hub.mdx';
+import TestsCards from '/snippets/data-tests/tests-cards.mdx';
+
+
+
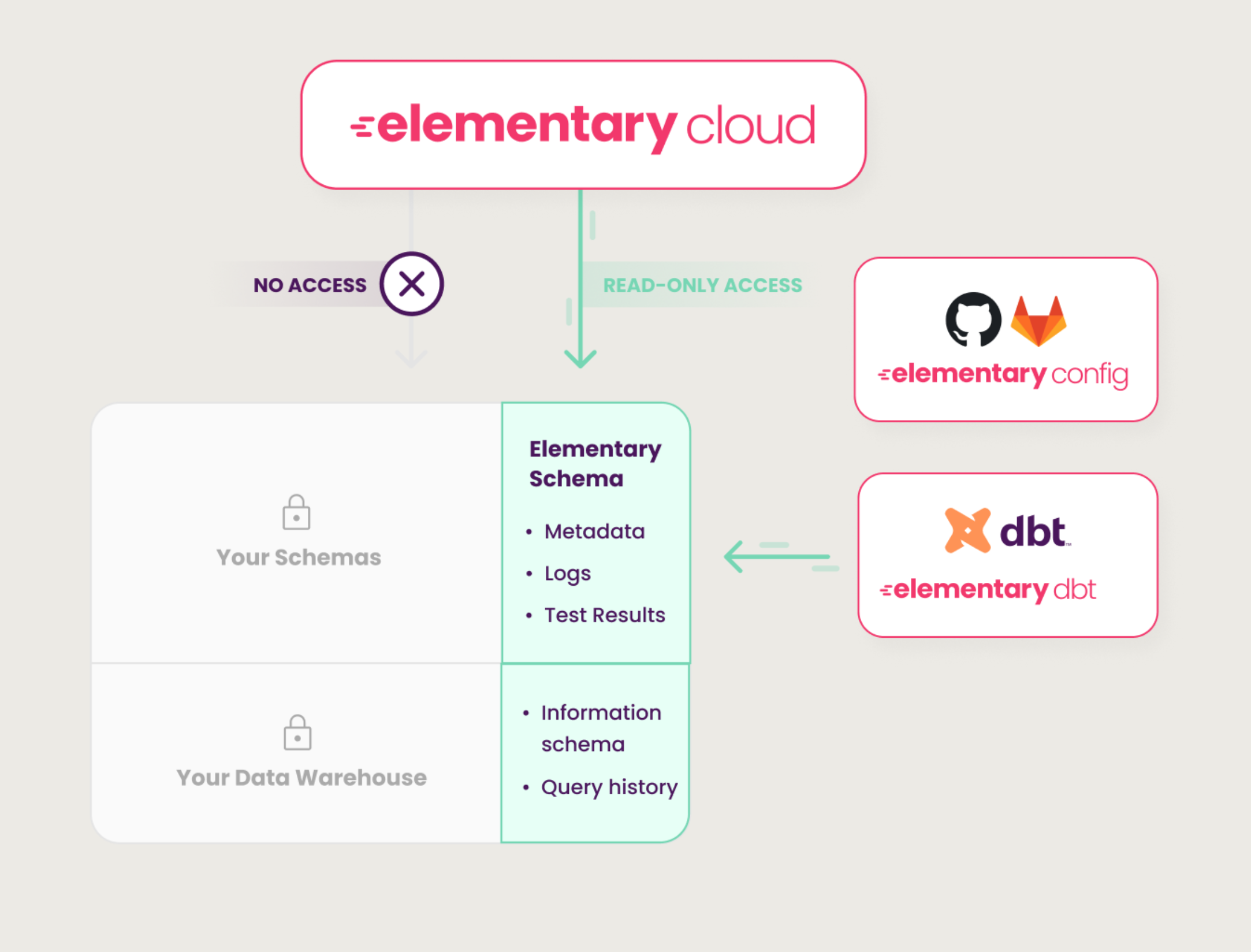
+ +
+  +
+  +
+  +
+ 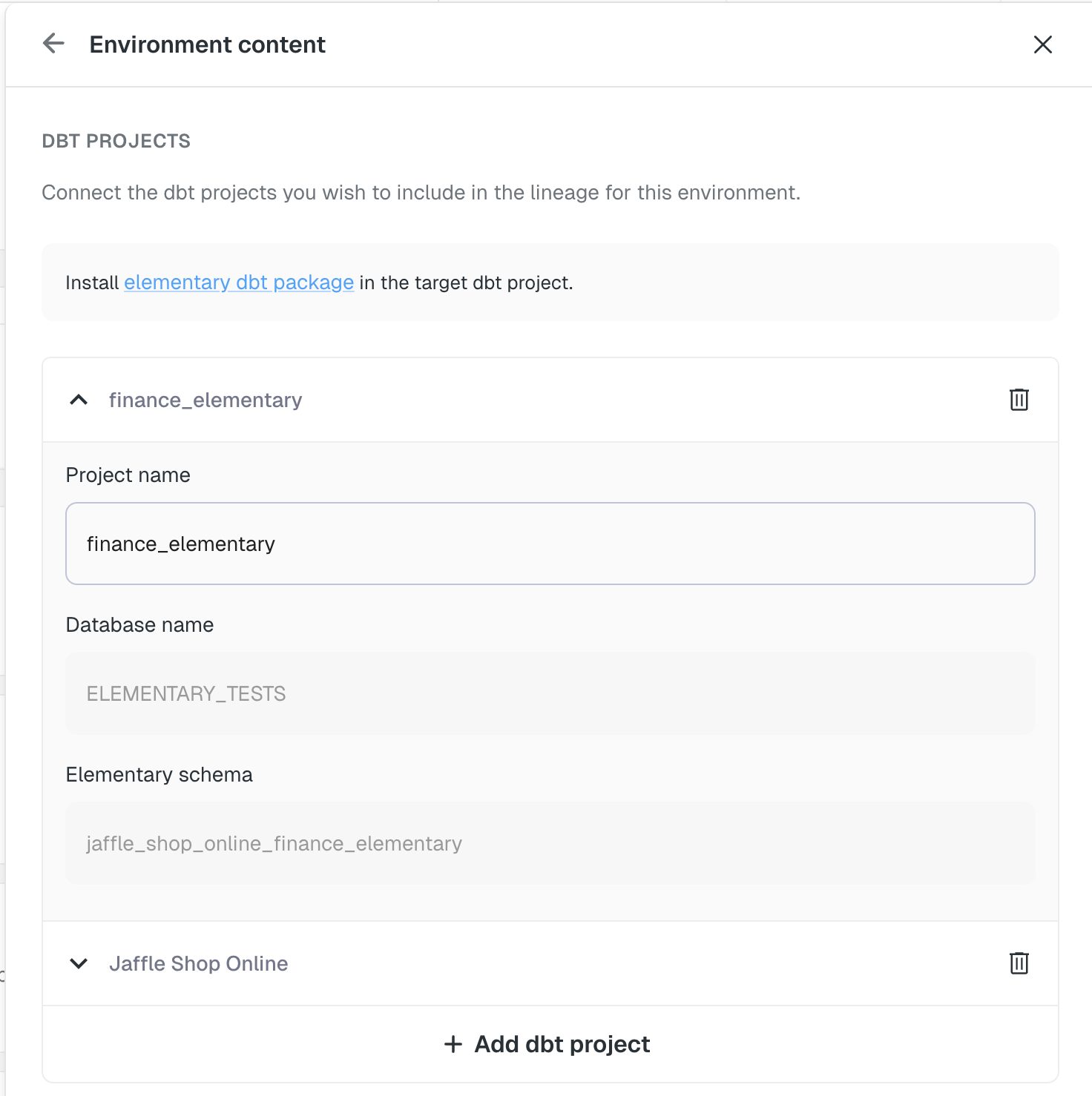 +
+  -
+
-
+ +
+  +
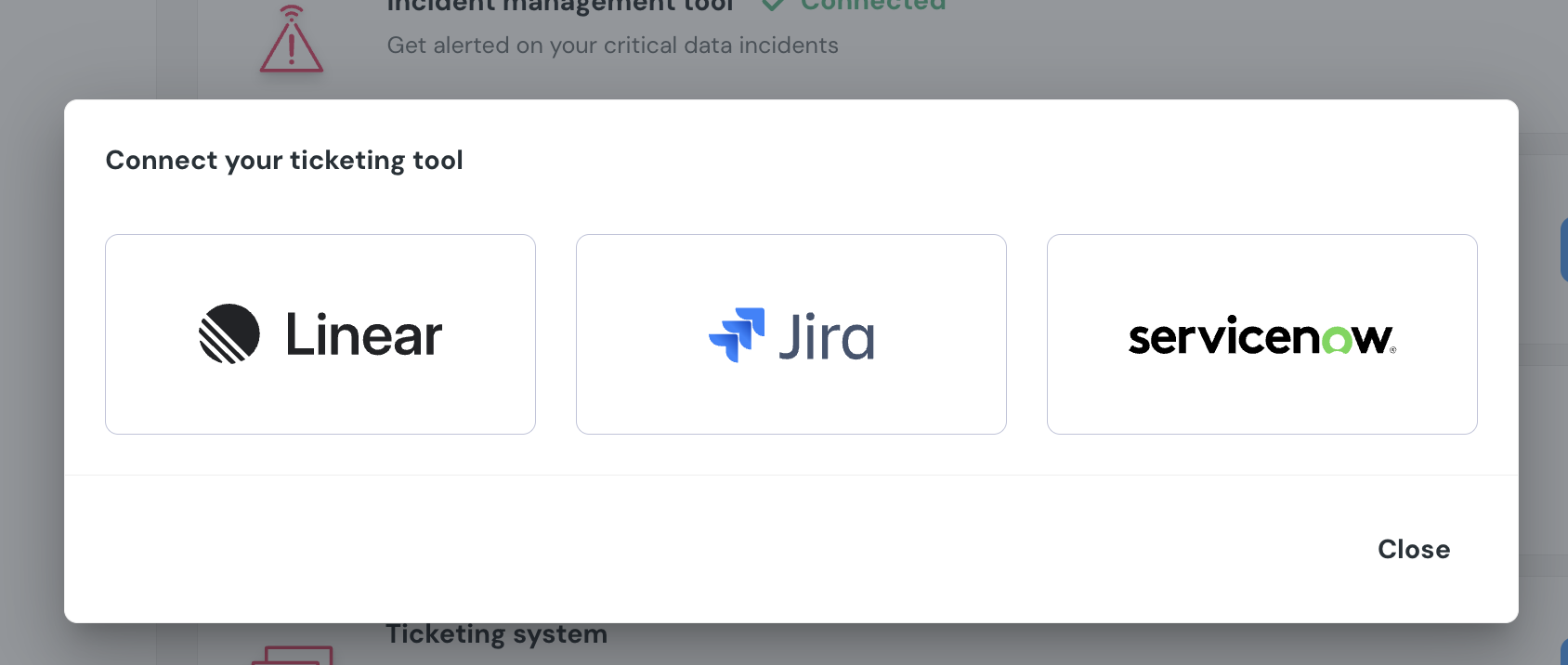
+## How to connect Jira
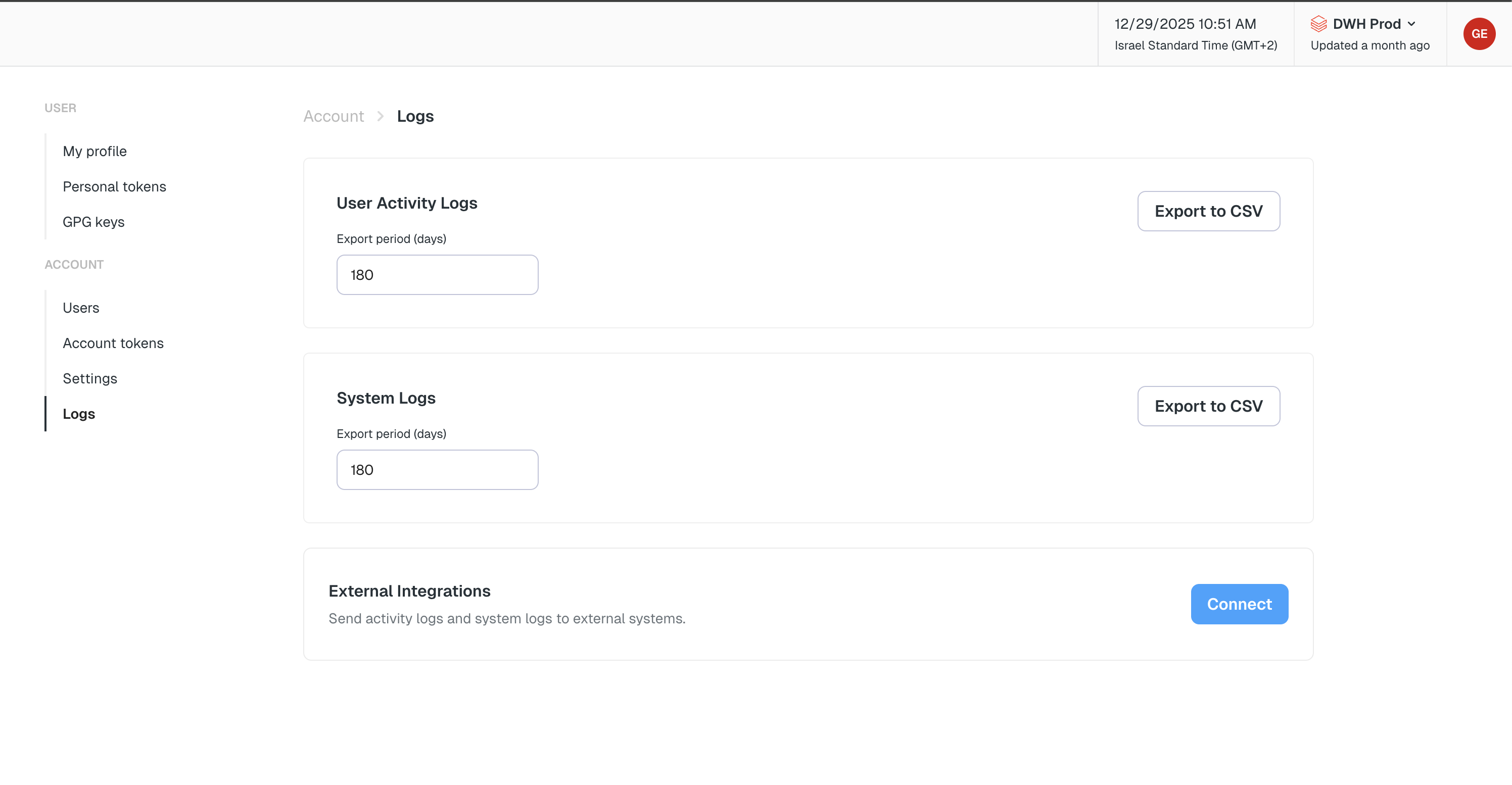
+1. Go to the `Environments` page on the sidebar.
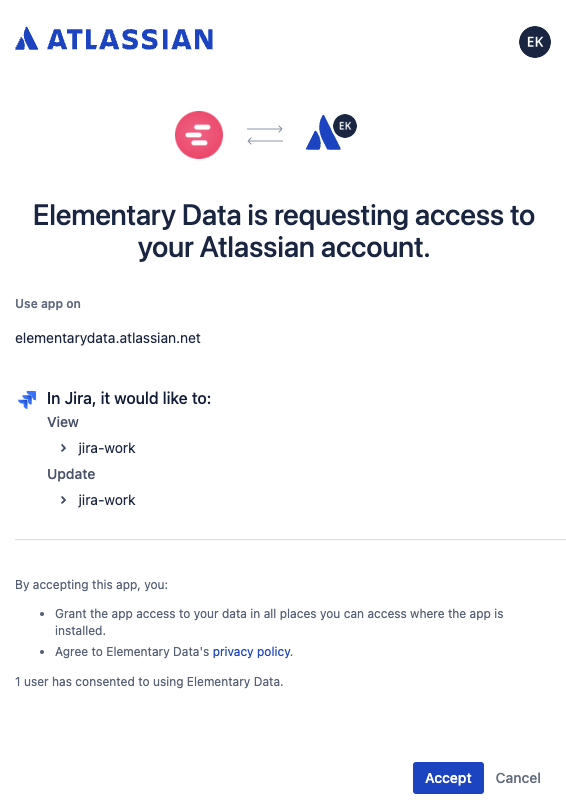
+2. Select an environment and click connect on the `Connect ticketing system` card, and select `Jira`.
+3. Authorize the Elementary app for your workspace. **This step may require a workspace admin approval.**
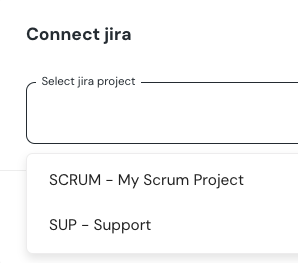
+4. Select a default project for tickets
+5. Click `Save` to finish the setup
+
+
+
+## How to connect Jira
+1. Go to the `Environments` page on the sidebar.
+2. Select an environment and click connect on the `Connect ticketing system` card, and select `Jira`.
+3. Authorize the Elementary app for your workspace. **This step may require a workspace admin approval.**
+4. Select a default project for tickets
+5. Click `Save` to finish the setup
+
+ +
+ +
+ +
+ +
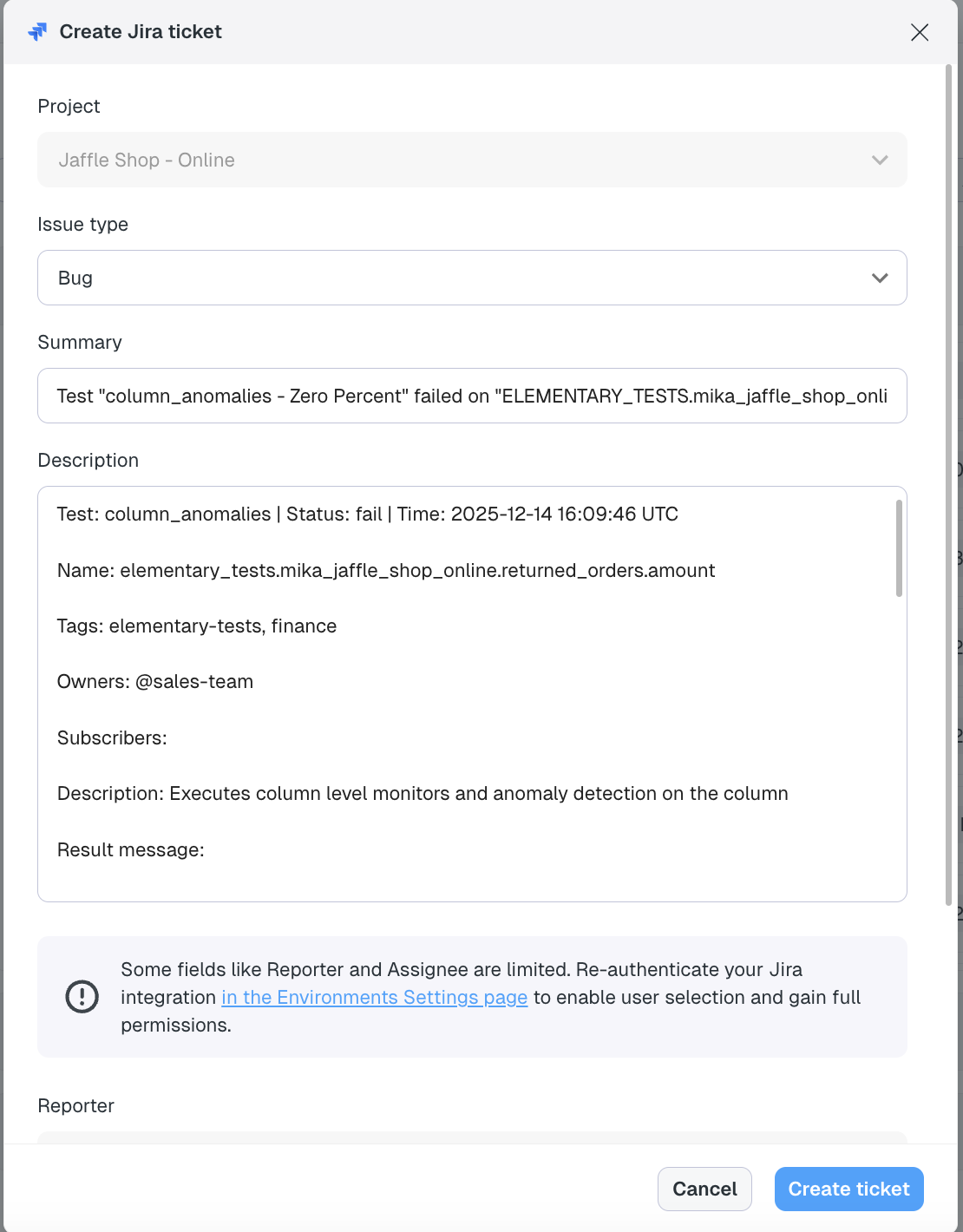
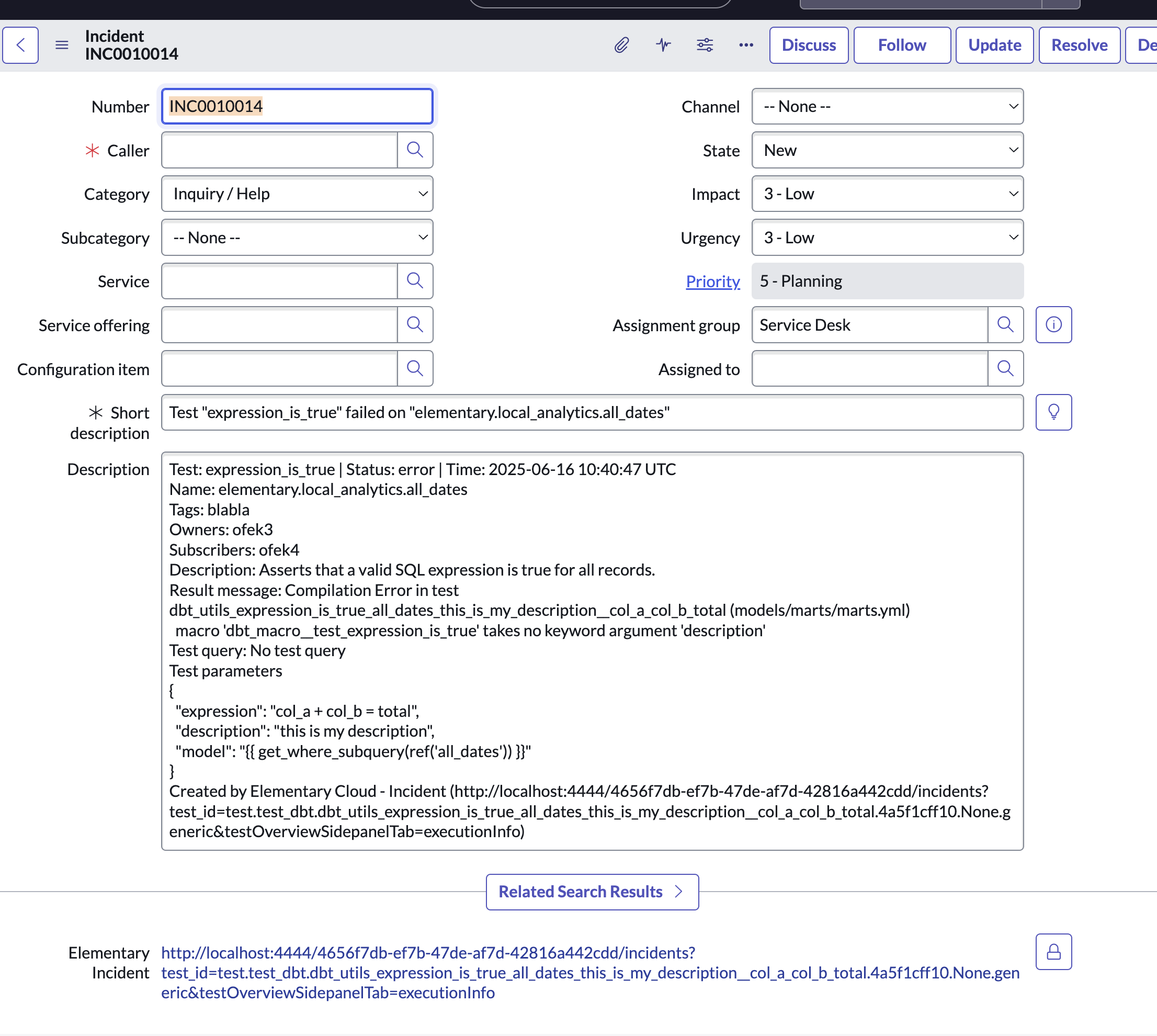
+## Creating Jira issues from incidents
+When an incident is created, you can generate a Jira issue directly from the incident page by clicking **Create Jira Ticket**. This opens a pre-filled form where you can review, update, or add additional fields before submitting. Once created, the issue is automatically added to the Jira team you selected when connecting Jira.
+
+After the ticket is created, a link to the Jira issue appears on the incident page. The Jira ticket itself also includes a link back to the incident in Elementary for easy cross-referencing.
+
+
+
+## Creating Jira issues from incidents
+When an incident is created, you can generate a Jira issue directly from the incident page by clicking **Create Jira Ticket**. This opens a pre-filled form where you can review, update, or add additional fields before submitting. Once created, the issue is automatically added to the Jira team you selected when connecting Jira.
+
+After the ticket is created, a link to the Jira issue appears on the incident page. The Jira ticket itself also includes a link back to the incident in Elementary for easy cross-referencing.
+
+ +
+
+
+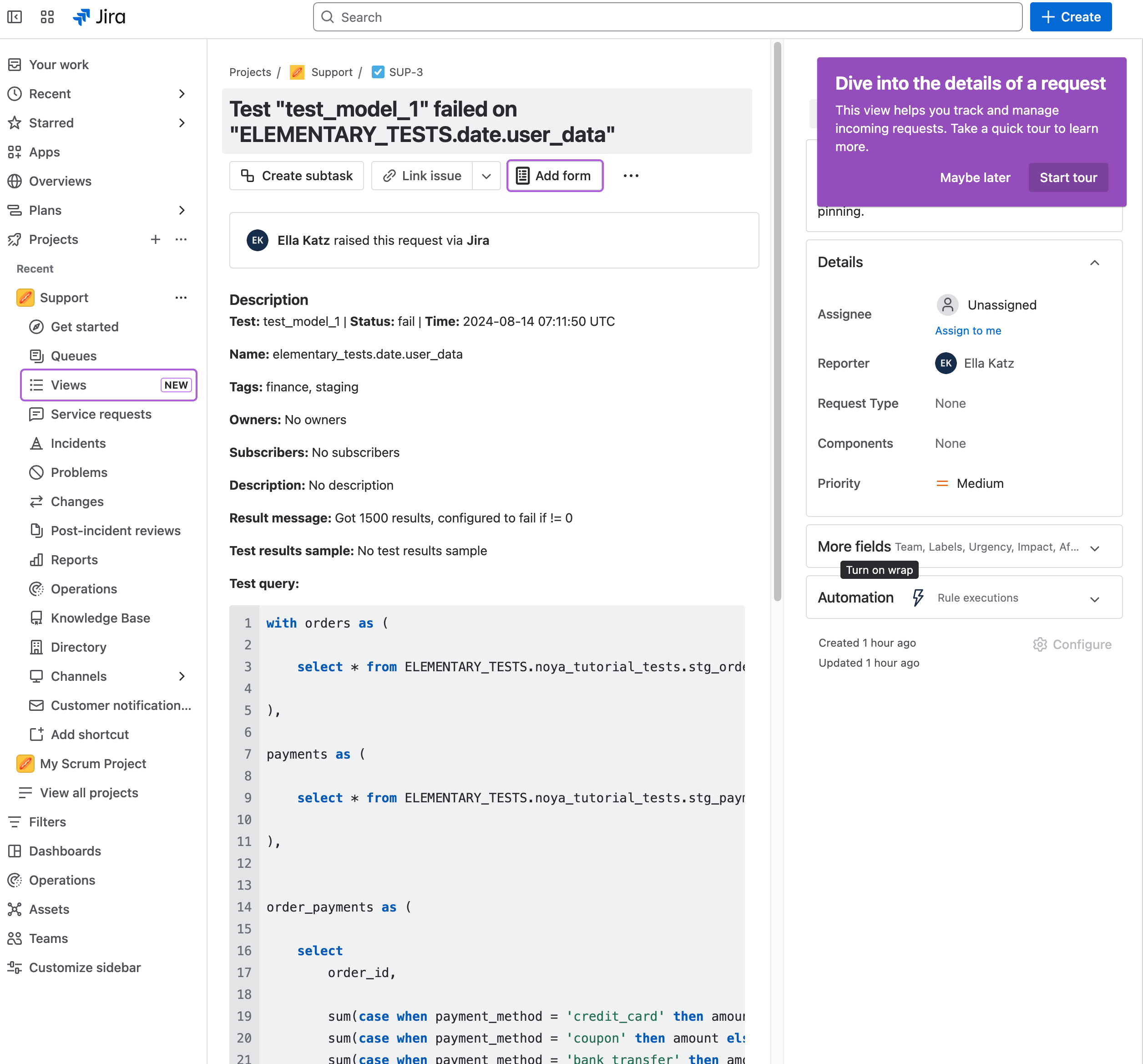 +
diff --git a/docs/cloud/integrations/alerts/linear.mdx b/docs/cloud/integrations/alerts/linear.mdx
index 5837a8c8a..35902c444 100644
--- a/docs/cloud/integrations/alerts/linear.mdx
+++ b/docs/cloud/integrations/alerts/linear.mdx
@@ -2,14 +2,30 @@
title: "Linear"
---
-
+
diff --git a/docs/cloud/integrations/alerts/linear.mdx b/docs/cloud/integrations/alerts/linear.mdx
index 5837a8c8a..35902c444 100644
--- a/docs/cloud/integrations/alerts/linear.mdx
+++ b/docs/cloud/integrations/alerts/linear.mdx
@@ -2,14 +2,30 @@
title: "Linear"
---
- +
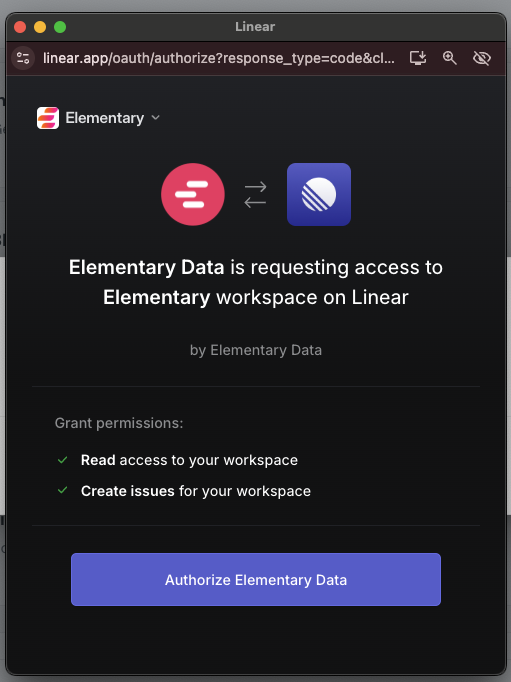
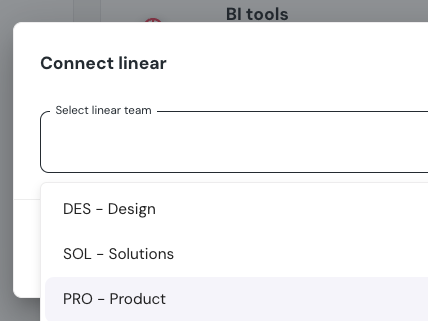
+## How to connect Linear
+1. Go to the `Environments` page on the sidebar.
+2. Select an environment and click connect on the `Connect ticketing system` card, and select `Linear`.
+3. Authorize the Elementary app for your workspace. **This step may require a workspace admin approval.**
+4. Select a default team for new tickets
+5. Click `Save` to finish the setup
+
+
+
+
+
+## How to connect Linear
+1. Go to the `Environments` page on the sidebar.
+2. Select an environment and click connect on the `Connect ticketing system` card, and select `Linear`.
+3. Authorize the Elementary app for your workspace. **This step may require a workspace admin approval.**
+4. Select a default team for new tickets
+5. Click `Save` to finish the setup
+
+
+
+ +
+ +
+## Creating Linear ticket from incidents
+When an incident is created, you can create a Linear ticket from the incident page by simply clicking on "Create Linear Ticket".
+The ticket will automatically be created in Linear, in the team you chose upon connecting Linear.
+
+After the ticket is created you can see the Linear ticket link in the incident page.
+The ticket will also contain a link to the incident in Elementary.
+
+
+## Creating Linear ticket from incidents
+When an incident is created, you can create a Linear ticket from the incident page by simply clicking on "Create Linear Ticket".
+The ticket will automatically be created in Linear, in the team you chose upon connecting Linear.
+
+After the ticket is created you can see the Linear ticket link in the incident page.
+The ticket will also contain a link to the incident in Elementary.
+ +
+
+
+ diff --git a/docs/cloud/integrations/alerts/ms-teams.mdx b/docs/cloud/integrations/alerts/ms-teams.mdx
index d7ea82311..387567b89 100644
--- a/docs/cloud/integrations/alerts/ms-teams.mdx
+++ b/docs/cloud/integrations/alerts/ms-teams.mdx
@@ -5,12 +5,12 @@ title: "Microsoft Teams"
Elementary's Microsoft Teams integration enables sending alerts when data issues happen.
The alerts are sent using Adaptive Cards format, which provides rich formatting and interactive capabilities.
-The alerts include rich context, and you can create [alert rules](/features/alerts-and-incidents/alert-rules) to distribute alerts to different channels and destinations.
+The alerts include rich context, and you can create [alert rules](cloud/features/alerts-and-incidents/alert-rules) to distribute alerts to different channels and destinations.
diff --git a/docs/cloud/integrations/alerts/ms-teams.mdx b/docs/cloud/integrations/alerts/ms-teams.mdx
index d7ea82311..387567b89 100644
--- a/docs/cloud/integrations/alerts/ms-teams.mdx
+++ b/docs/cloud/integrations/alerts/ms-teams.mdx
@@ -5,12 +5,12 @@ title: "Microsoft Teams"
Elementary's Microsoft Teams integration enables sending alerts when data issues happen.
The alerts are sent using Adaptive Cards format, which provides rich formatting and interactive capabilities.
-The alerts include rich context, and you can create [alert rules](/features/alerts-and-incidents/alert-rules) to distribute alerts to different channels and destinations.
+The alerts include rich context, and you can create [alert rules](cloud/features/alerts-and-incidents/alert-rules) to distribute alerts to different channels and destinations.

 +
+  +
+  +
+  +
+  +
+  +
+  +
+
+
+
+
+  +
+  +
+  +
+  +
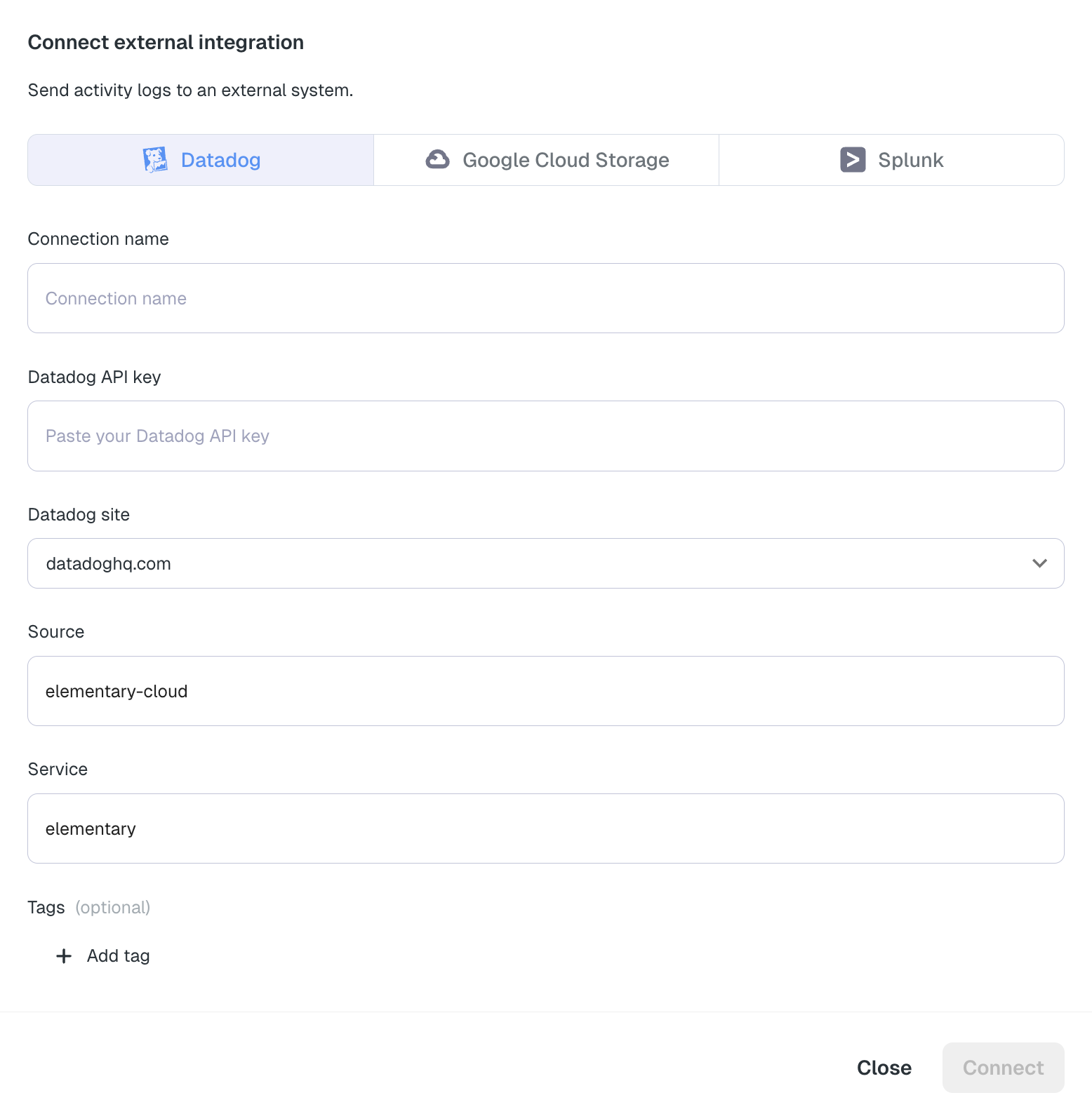
+ +To create one, please follow the [official Hex documentation](https://learn.hex.tech/docs/api/api-overview#workspace-tokens). +Make sure you create a Hex Workspace token with read access for all categories and "read project queried tables". + +### Connecting Hex to Elementary + +Navigate to the **Account settings > Environments** and choose the environment to which you would like to connect Hex. +Choose the Hex connection and provide the following details to validate and complete the integration. + +- **Base URL**: Your Hex workspace URL. For example: `https://app.hex.tech/my-workspace/` +- **Workspace Token**: The Hex workspace token you've created on the previous step. + + +### Limitations + +- **Hex assets will only be visible if their project has run within the last 14 days.** Elementary tracks Hex query history to determine asset visibility, and only projects with recent execution activity will appear in the lineage graph. diff --git a/docs/cloud/integrations/bi/lightdash.mdx b/docs/cloud/integrations/bi/lightdash.mdx new file mode 100644 index 000000000..e902055d4 --- /dev/null +++ b/docs/cloud/integrations/bi/lightdash.mdx @@ -0,0 +1,31 @@ +--- +title: "Lightdash" +--- + +After you connect Lightdash, Elementary will automatically and continuously extend the column-level-lineage to the dashboard and chart level. +This will provide you end-to-end data lineage to understand your downstream dependencies, called exposures. + +### Create a Personal Access Token + +Elementary needs a Personal Access Token (PAT) to access the Lightdash API on your behalf. + +1. In Lightdash, go to **Settings > Personal Access Tokens**. +2. Click **Generate Token**. +3. Give the token a descriptive name (e.g. "Elementary integration"). +4. Copy and save the generated token securely — you will need it when connecting Lightdash to Elementary. + +For more details, refer to the [official Lightdash documentation](https://docs.lightdash.com/references/workspace/personal-tokens). + +
+To create those, Please follow the [official Sigma documentation](https://help.sigmacomputing.com/reference/generate-client-credentials#generate-api-client-credentials). +Make sure you enable 'REST API' privileges for that client. + +### Connecting Sigma to Elementary + +Navigate to the **Account settings > Environments** and choose the environment to which you would like to connect Sigma. +Choose the Sigma connection and provide the following details to validate and complete the integration. + +- **Cloud Provider:** To determine your Sigma cloud provider, Navigate to **Account -> General Settings** under Sigma's **Administration** menu and look for **'Cloud: ...'**.
Should be one of the following: + - `AWS US` + - `AWS Canada` + - `AWS Europe` + - `AWS UK` + - `Azure US` + - `GCP` +- **Client ID**: The Sigma client ID you've created on the previous step. +- **Client Secret:** The new Sigma client secret you've created on the previous step. + + +### Limitations + +`Datasets` or `Data Models` are currently excluded from computed lineage graph - which will point from DWH directly to your Workbook Elements.
\ No newline at end of file diff --git a/docs/cloud/integrations/bi/thoughtspot.mdx b/docs/cloud/integrations/bi/thoughtspot.mdx index 52b31d8e9..160c8bf81 100644 --- a/docs/cloud/integrations/bi/thoughtspot.mdx +++ b/docs/cloud/integrations/bi/thoughtspot.mdx @@ -1,15 +1,32 @@ --- -title: "ThoughtSpot" +title: "Thoughtspot" --- -
+To enable Trusted Authentication on a user, please follow the [official Thoughtspot documentation](https://developers.thoughtspot.com/docs/trusted-auth-secret-key).
+Make sure you copy the generated token (`Secret Key`) as you will need it to connect Thoughtspot to Elementary. + +### User Privileges + +For an easy integration, it's recommended for the connected user to be an administrator (`ADMINISTRATION` privilege), this will ensure Elementary can access all of your Liveboards and Answers.
+It is also possible though to integrate with a regular user, just make sure it can download data (has `DATADOWNLOADING` privilege) for all the relvant ThoughtSpot entities you want Elementary to discover and show lineage for. + +### Connecting Thoughtspot to Elementary + +Navigate to the **Account settings > Environments** and choose the environment to which you would like to connect ThoughtSpot. +Choose the Thoughtspot connection and provide the following details to validate and complete the integration. + +- **User Name:** The username of the user you want to use to connect to Thoughtspot. +- **Secret Key:** The token generated for the user you want to use to connect to Thoughtspot (from the previous step). +- **Base URL:** The URL of your Thoughtspot instance. This would be `'https://
\ No newline at end of file diff --git a/docs/cloud/integrations/code-repo/azure-devops.mdx b/docs/cloud/integrations/code-repo/azure-devops.mdx new file mode 100644 index 000000000..0784986ac --- /dev/null +++ b/docs/cloud/integrations/code-repo/azure-devops.mdx @@ -0,0 +1,43 @@ +--- +title: "Azure DevOps Integration" +sidebarTitle: "Azure DevOps" +--- + +Elementary can integrate with Azure DevOps to connect to the code repository where your **dbt project code** is managed, and it opens pull requests with configuration changes. + +## Connecting Through the Azure DevOps App + +1. Navigate to **Environments** in Elementary Cloud, open your environment, then go to **Code repository**. +2. Click on **Connect** and select **Azure DevOps**. +3. Enter your Azure DevOps organization URL \ +(e.g., `https://dev.azure.com/your-organization`). +4. Click **Save**. +5. Connect through OAuth to authenticate between Azure DevOps and Elementary Cloud. During this process, a temporary token is issued, which can be used to make API calls. Along with the temporary token, a refresh token is also provided. The refresh token is used when Azure DevOps indicates that the temporary token has expired. For Microsoft services, OAuth is managed by Microsoft Entra ID (formerly known as Active Directory). + +## Updating tokens when they expire + +When your Azure DevOps token expires, update the connection with new tokens: + +1. Go to **Environments**, open your environment, and go to **Code repository**. +2. Click **Edit** on the code repository connection. +3. Paste the new generated tokens (from Azure DevOps) and save. + +--- + +## Required Permissions + +Elementary requires the following permissions in your Azure DevOps **dbt repository**: + +- **Read and write** access to the repository +- Access to **file contents** +- Permission to **open and read pull requests** + +--- + +## Troubleshooting + +If you encounter issues with the Azure DevOps integration, ensure the following: + +1. Your **organization URL** is correct. +2. You have **sufficient permissions** in Azure DevOps. +3. Elementary is properly **authorized** in your Azure DevOps organization. diff --git a/docs/cloud/integrations/code-repo/bitbucket.mdx b/docs/cloud/integrations/code-repo/bitbucket.mdx new file mode 100644 index 000000000..d44d7d0fa --- /dev/null +++ b/docs/cloud/integrations/code-repo/bitbucket.mdx @@ -0,0 +1,26 @@ +--- +title: "Bitbucket" +--- + +import RepoConnectionSettings from '/snippets/cloud/integrations/repo-connection-settings.mdx'; + + + +Elementary connects to the code repository where your dbt project code is managed, and opens PRs with configuration changes. + +## Recommended: Connect using Elementary Bitbucket App + +Navigate to the **Account settings > Environments** and choose the environment to which you would like to connect the dbt project code repository. + +Simply Click the blue button that says "Connect with Elementary Bitbucket App" and follow the instructions. +In the menu that opens up later on, select the repository where your dbt project is stored, and if needed the branch and path to the dbt project. + +
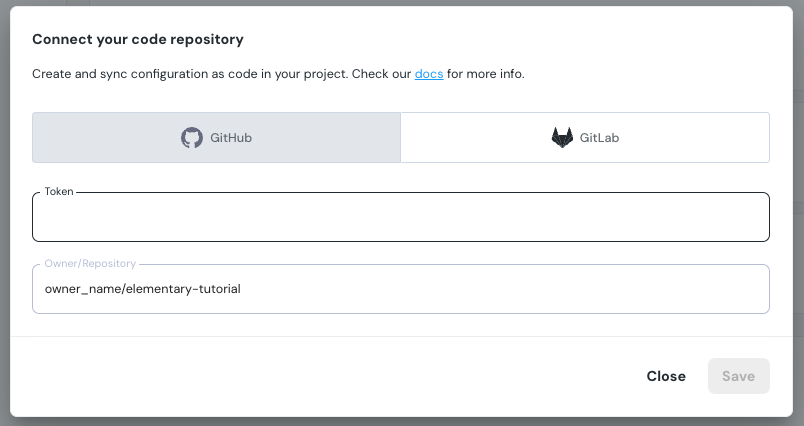 -
+
-
+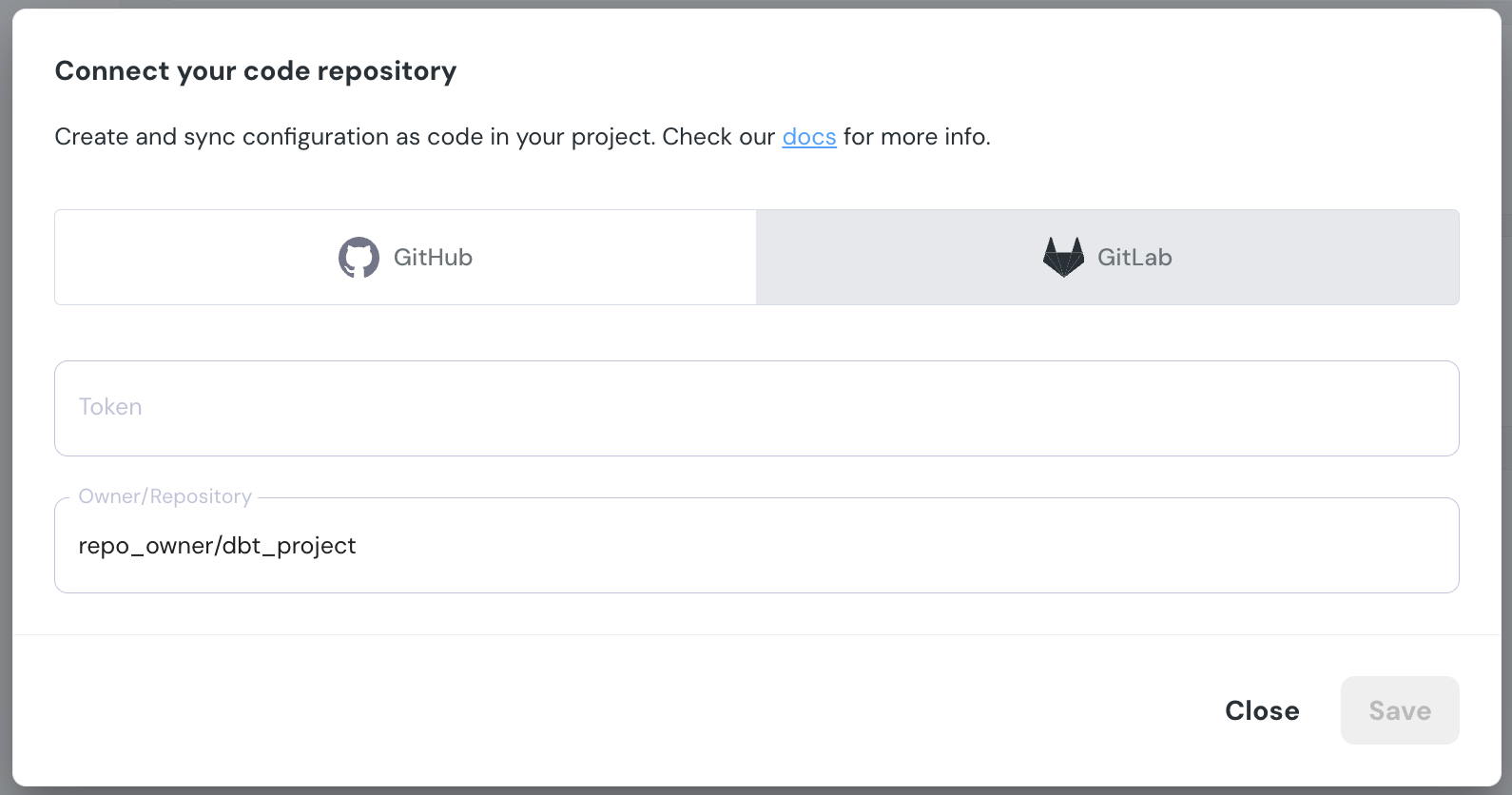 -
+## Repository connection settings
+
+
-
+## Repository connection settings
+
+ +
+  +
+
+
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ 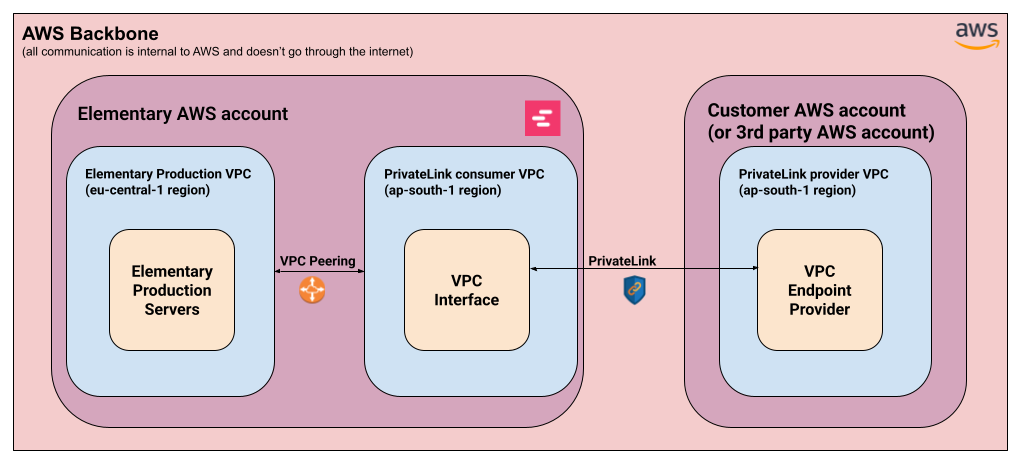 +
+Elementary’s PrivateLink setup consists generally from two parts:
+
+1. **AWS PrivateLink connection** -
+ 1. Provider side (Customer / 3rd party) - **A VPC endpoint service** is set up at the customer’s AWS account (or a 3rd party AWS account in the case of Snowflake). This provides access to a particular service in that account.
+ 2. Consumer side (Elementary) - Elementary sets up a dedicated VPC interface that will connect to the integrated service, in the same AWS region as the service.
+ This is done through a dedicated regional VPC created for this purpose.
+2. **AWS VPC Peering:**
+ 1. Elementary’s production servers are located in the **eu-central-1** (Frankfurt) region. For us to be able to access the service exposed through PrivateLink, we connect our main production VPC with the regional VPC mentioned above.
+
+## Supported integrations
+
+### Snowflake
+
+Snowflake has support for connecting to AWS-hosted Snowflake accounts via PrivateLink. This setup is entirely managed by Snowflake, so Elementary connects with an endpoint service hosted on Snowflake’s AWS account for this purpose.
+
+In order to set up a PrivateLink connection with Snowflake, please follow the steps below:
+
+1. **Open a support case to Snowflake Support**
+ 1. Ask to authorize Elementary’s AWS account for PrivateLink access.
+ 2. Provide Elementary’s account ID in the request - `743289191656`
+2. **Obtain the PrivateLink configuration**
+ 1. Once Snowflake’s support team approves the request, obtain the PrivateLink configuration by invoking the following commands (admin access is required):
+
+ ```sql
+ USE ROLE ACCOUNTADMIN;
+ SELECT SYSTEM$GET_PRIVATELINK_CONFIG();
+ ```
+
+3. **Provide Elementary with the configuration obtained in the previous step.**
+ 1. Elementary will then setup the required infrastructure to connect to Snowflake via PrivateLink.
+4. **Add a Snowflake environment in Elementary**
+ 1. Follow the instructions [here](/cloud/integrations/dwh/snowflake) to set up a Snowflake environment in Elementary.
+ 1. When supplying the account, use `
+
+Elementary’s PrivateLink setup consists generally from two parts:
+
+1. **AWS PrivateLink connection** -
+ 1. Provider side (Customer / 3rd party) - **A VPC endpoint service** is set up at the customer’s AWS account (or a 3rd party AWS account in the case of Snowflake). This provides access to a particular service in that account.
+ 2. Consumer side (Elementary) - Elementary sets up a dedicated VPC interface that will connect to the integrated service, in the same AWS region as the service.
+ This is done through a dedicated regional VPC created for this purpose.
+2. **AWS VPC Peering:**
+ 1. Elementary’s production servers are located in the **eu-central-1** (Frankfurt) region. For us to be able to access the service exposed through PrivateLink, we connect our main production VPC with the regional VPC mentioned above.
+
+## Supported integrations
+
+### Snowflake
+
+Snowflake has support for connecting to AWS-hosted Snowflake accounts via PrivateLink. This setup is entirely managed by Snowflake, so Elementary connects with an endpoint service hosted on Snowflake’s AWS account for this purpose.
+
+In order to set up a PrivateLink connection with Snowflake, please follow the steps below:
+
+1. **Open a support case to Snowflake Support**
+ 1. Ask to authorize Elementary’s AWS account for PrivateLink access.
+ 2. Provide Elementary’s account ID in the request - `743289191656`
+2. **Obtain the PrivateLink configuration**
+ 1. Once Snowflake’s support team approves the request, obtain the PrivateLink configuration by invoking the following commands (admin access is required):
+
+ ```sql
+ USE ROLE ACCOUNTADMIN;
+ SELECT SYSTEM$GET_PRIVATELINK_CONFIG();
+ ```
+
+3. **Provide Elementary with the configuration obtained in the previous step.**
+ 1. Elementary will then setup the required infrastructure to connect to Snowflake via PrivateLink.
+4. **Add a Snowflake environment in Elementary**
+ 1. Follow the instructions [here](/cloud/integrations/dwh/snowflake) to set up a Snowflake environment in Elementary.
+ 1. When supplying the account, use ` +
+3. **Configure a private access setting**
+
+ Go to Security -> Private Access Settings.
+
+ * If you've set up private link with your Databricks instance before, you should already have a private access setting configured.
+In that case, please ensure that the endpoint allows access to the VPC endpoint created in step (2).
+
+ * If this is the first time you are setting PrivateLink for your databricks workspace:
+ * Click on "Add private access config".
+ * Please fill in the following details:
+ * A name for your setting: e.g. "Privatelink settings"
+ * Your AWS region
+ * Whether or not to allow public access - only set this as False if all your systems and users access your Databricks workspace through privatelink.
+ * Private access level - either leave as "Account", or allow-list specific VPCs including the Elementary VPC created in the previous step.
+
+
+
+3. **Configure a private access setting**
+
+ Go to Security -> Private Access Settings.
+
+ * If you've set up private link with your Databricks instance before, you should already have a private access setting configured.
+In that case, please ensure that the endpoint allows access to the VPC endpoint created in step (2).
+
+ * If this is the first time you are setting PrivateLink for your databricks workspace:
+ * Click on "Add private access config".
+ * Please fill in the following details:
+ * A name for your setting: e.g. "Privatelink settings"
+ * Your AWS region
+ * Whether or not to allow public access - only set this as False if all your systems and users access your Databricks workspace through privatelink.
+ * Private access level - either leave as "Account", or allow-list specific VPCs including the Elementary VPC created in the previous step.
+
+ 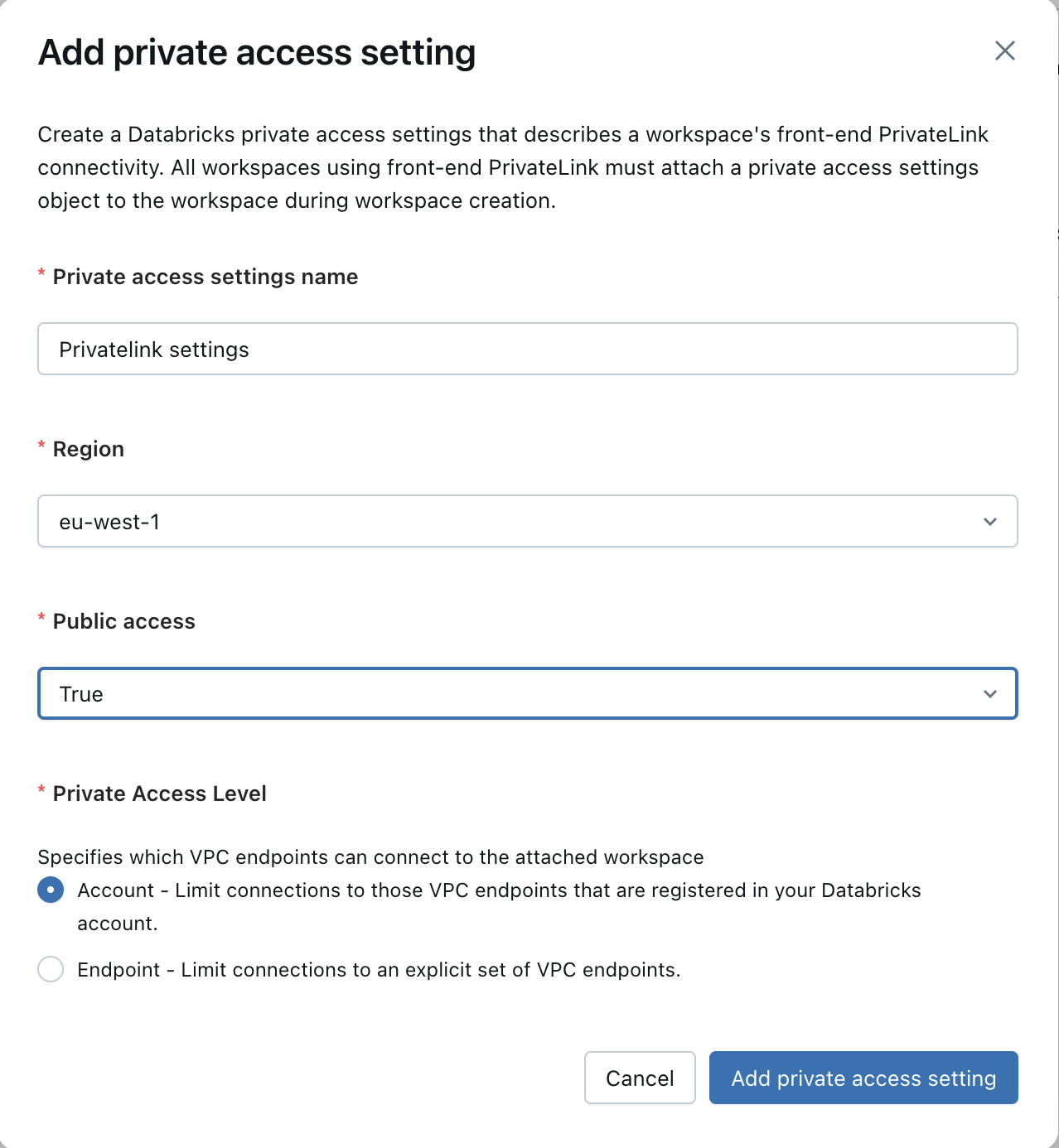 +
+4. **Add the private access setting to your Databricks workspace**
+
+ __Note__: If you have already set up Privatelink with Databricks in the past, you can skip this step.
+
+ Under the Databricks account management portal, go to Workspaces, click on your workspace and then on "Update Workspace".
+Then go to "Advanced Configurations", and under "Private Link", please attach the setting created in the previous step.
+
+5. **Add a Databricks environment in Elementary**
+
+ After all the previous steps are completed, please reach out to the Elementary team to verify that your Databricks cluster is accessible via PrivateLink.
+
+ Once verified, please add a Databricks environment to Elementary by following [this guide](/cloud/integrations/dwh/databricks).
+
+ Under the *Add the Elementary IP to allowlist* section, please add the following private subnets *instead* of the IP mentioned there:
+ * 10.0.1.x
+ * 10.0.2.x
+ * 10.0.3.x
+
+
+### Github Enterprise Server
+
+Github Enterprise Server can be connected to Elementary Cloud via AWS PrivateLink. This setup requires creating a VPC endpoint service in your AWS account that exposes your GitHub Enterprise Server instance.
+
+**Prerequisites:**
+- Your Github Enterprise Server instance must be accessible from within your AWS VPC
+- You must have administrative access to your AWS account
+- Ensure you are working in the correct AWS region where your Github Enterprise Server is deployed
+
+In order to set up a PrivateLink connection with Github Enterprise Server, please follow the steps below:
+
+1. **Create a VPC Endpoint Service**
+ - Follow the detailed instructions in the [Creating a VPC Endpoint Service](#creating-a-vpc-endpoint-service) section below to set up the endpoint service for your GitHub Enterprise Server instance.
+
+2. **Add a Github integration in Elementary** - Once the VPC endpoint service setup is completed, please proceed to adding a [GitHub integration](https://docs.elementary-data.com/cloud/integrations/code-repo/github). Note:
+ * OAuth is not currently supported for Github Enterprise Server, so you should generate a fine-grained token.
+ * You should use the same Github hostname as you would internally (Elementary will resolve that host to the privatelink endpoint)
+
+## Creating a VPC Endpoint Service
+
+
+
+4. **Add the private access setting to your Databricks workspace**
+
+ __Note__: If you have already set up Privatelink with Databricks in the past, you can skip this step.
+
+ Under the Databricks account management portal, go to Workspaces, click on your workspace and then on "Update Workspace".
+Then go to "Advanced Configurations", and under "Private Link", please attach the setting created in the previous step.
+
+5. **Add a Databricks environment in Elementary**
+
+ After all the previous steps are completed, please reach out to the Elementary team to verify that your Databricks cluster is accessible via PrivateLink.
+
+ Once verified, please add a Databricks environment to Elementary by following [this guide](/cloud/integrations/dwh/databricks).
+
+ Under the *Add the Elementary IP to allowlist* section, please add the following private subnets *instead* of the IP mentioned there:
+ * 10.0.1.x
+ * 10.0.2.x
+ * 10.0.3.x
+
+
+### Github Enterprise Server
+
+Github Enterprise Server can be connected to Elementary Cloud via AWS PrivateLink. This setup requires creating a VPC endpoint service in your AWS account that exposes your GitHub Enterprise Server instance.
+
+**Prerequisites:**
+- Your Github Enterprise Server instance must be accessible from within your AWS VPC
+- You must have administrative access to your AWS account
+- Ensure you are working in the correct AWS region where your Github Enterprise Server is deployed
+
+In order to set up a PrivateLink connection with Github Enterprise Server, please follow the steps below:
+
+1. **Create a VPC Endpoint Service**
+ - Follow the detailed instructions in the [Creating a VPC Endpoint Service](#creating-a-vpc-endpoint-service) section below to set up the endpoint service for your GitHub Enterprise Server instance.
+
+2. **Add a Github integration in Elementary** - Once the VPC endpoint service setup is completed, please proceed to adding a [GitHub integration](https://docs.elementary-data.com/cloud/integrations/code-repo/github). Note:
+ * OAuth is not currently supported for Github Enterprise Server, so you should generate a fine-grained token.
+ * You should use the same Github hostname as you would internally (Elementary will resolve that host to the privatelink endpoint)
+
+## Creating a VPC Endpoint Service
+
+ +
+ +
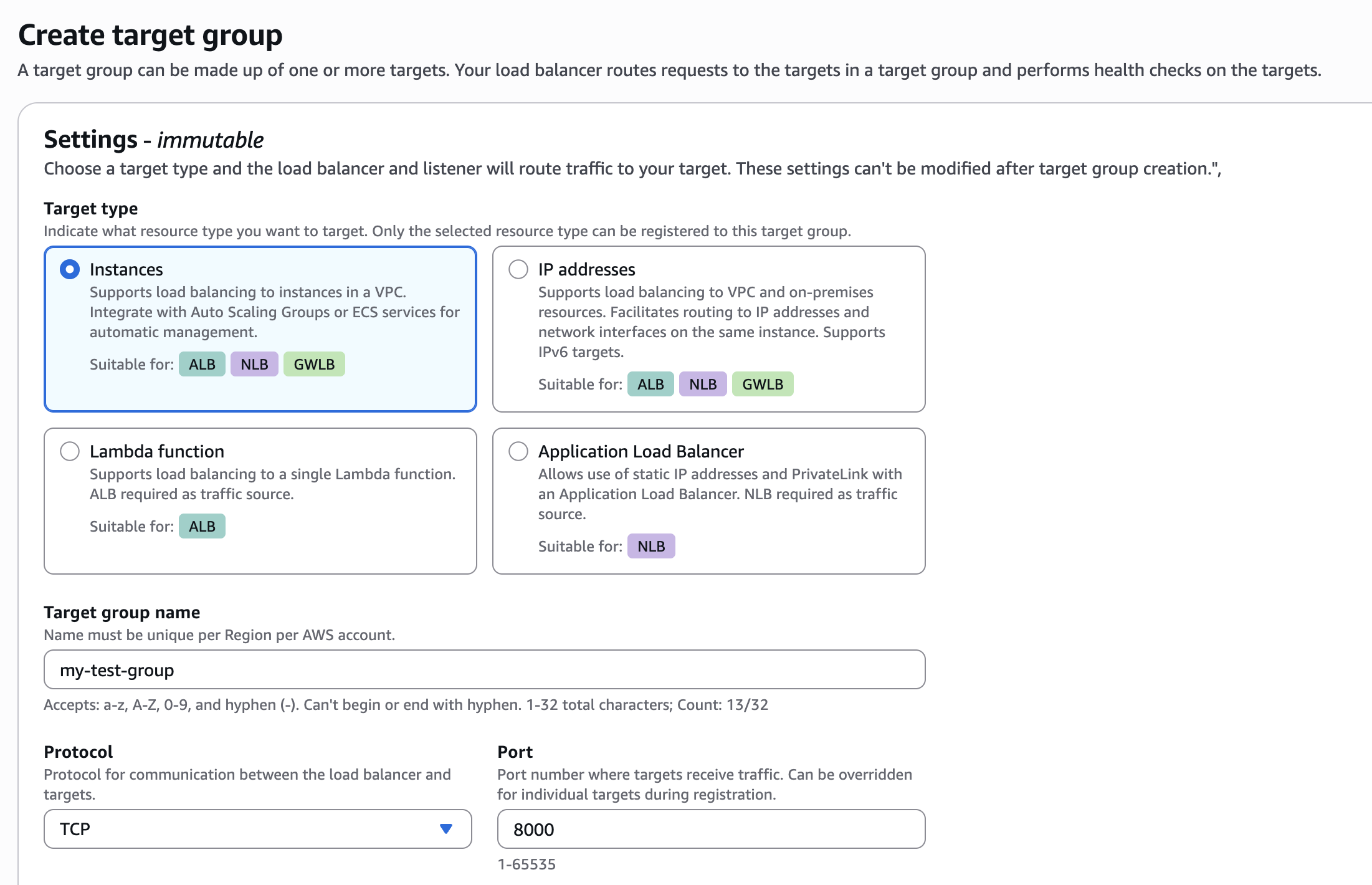
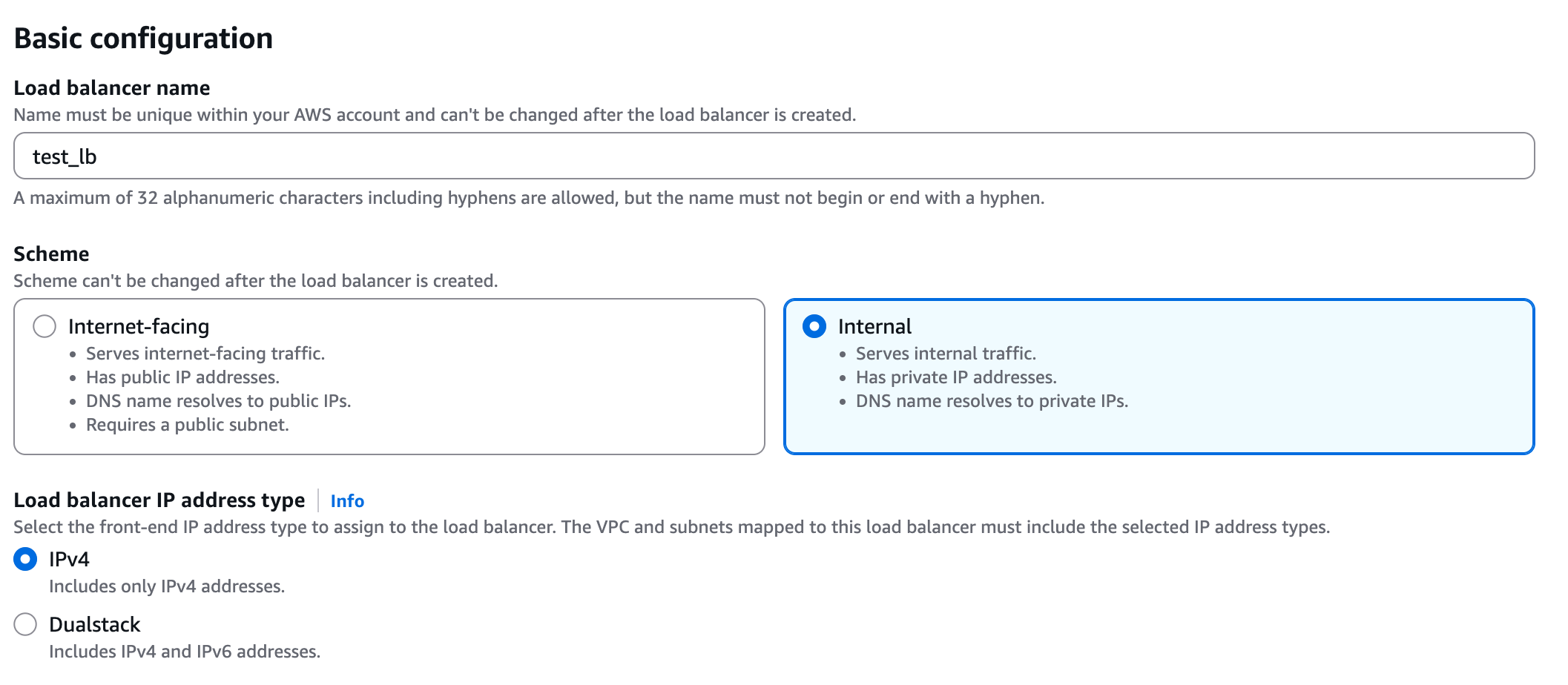
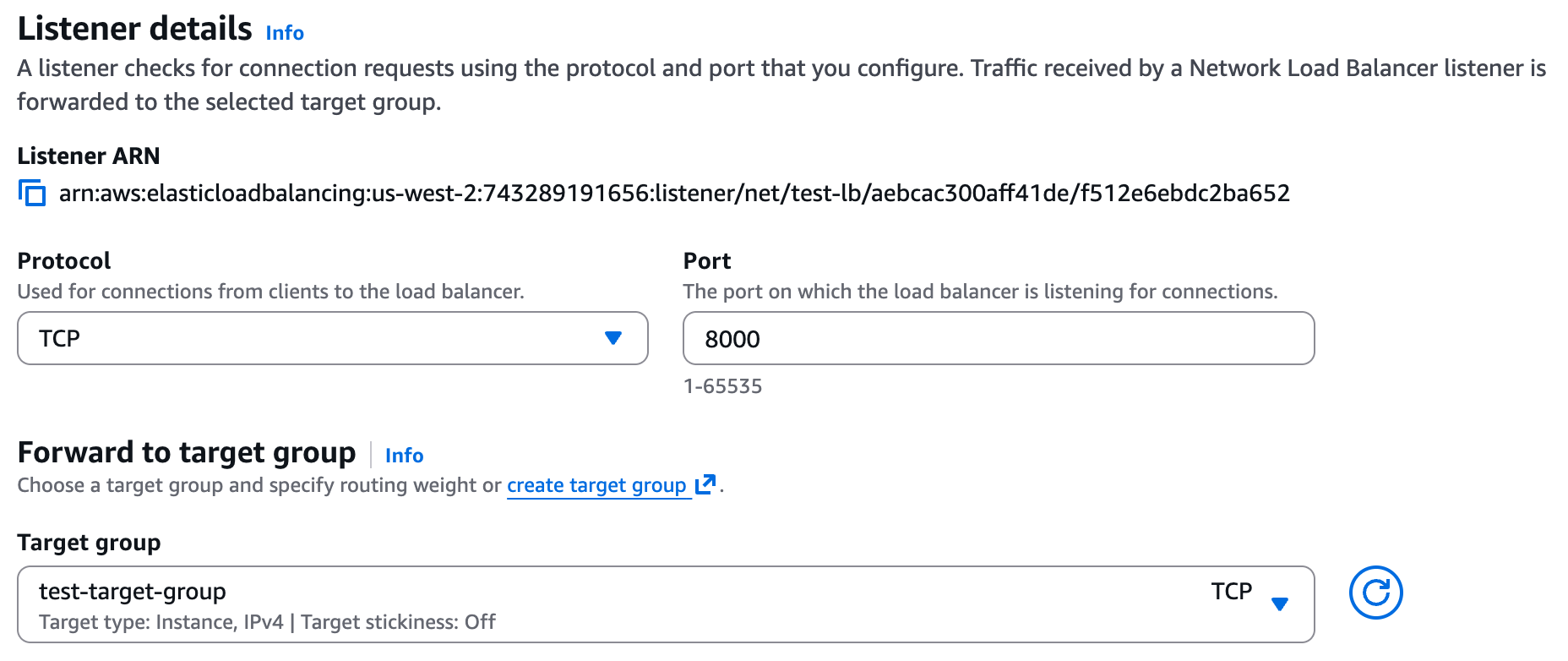
+**2. Create a Network Load Balancer (NLB)**
+
+Under the EC2 page in AWS, navigate to "Load Balancers" and click on "Create load balancer". Choose **Network Load Balancer** and proceed with the creation. Please follow the wizard and fill the following details:
+1. **Load balancer name** - Choose a name for the load balanver (e.g. "github-lb")
+2. **Scheme** - Internal.
+3. **Load balancer IP address type** - IPv4.
+4. **VPC** - Choose same VPC as the one you used for the target group above.
+5. **Mappings** - Select one or more private subnets.
+6. **Security groups** - Select a security group with access to your service. Please grant access to the relevant ports for your service, to the following IP ranges (these are the internal IPs Elementary may connect to your service from):
+ * 10.0.1.x
+ * 10.0.2.x
+ * 10.0.3.x
+7. **Listeners** - Select the target group, protocol, and port from Step 1.
+
+
+
+**2. Create a Network Load Balancer (NLB)**
+
+Under the EC2 page in AWS, navigate to "Load Balancers" and click on "Create load balancer". Choose **Network Load Balancer** and proceed with the creation. Please follow the wizard and fill the following details:
+1. **Load balancer name** - Choose a name for the load balanver (e.g. "github-lb")
+2. **Scheme** - Internal.
+3. **Load balancer IP address type** - IPv4.
+4. **VPC** - Choose same VPC as the one you used for the target group above.
+5. **Mappings** - Select one or more private subnets.
+6. **Security groups** - Select a security group with access to your service. Please grant access to the relevant ports for your service, to the following IP ranges (these are the internal IPs Elementary may connect to your service from):
+ * 10.0.1.x
+ * 10.0.2.x
+ * 10.0.3.x
+7. **Listeners** - Select the target group, protocol, and port from Step 1.
+
+ +
+ +
+ +
+**3. Verify the Target Group is Healthy**
+
+Once the load balancer from the previous step is ready, please navigate to the target group you created above. It should be listed as "Healthy".
+
+
+
+**3. Verify the Target Group is Healthy**
+
+Once the load balancer from the previous step is ready, please navigate to the target group you created above. It should be listed as "Healthy".
+
+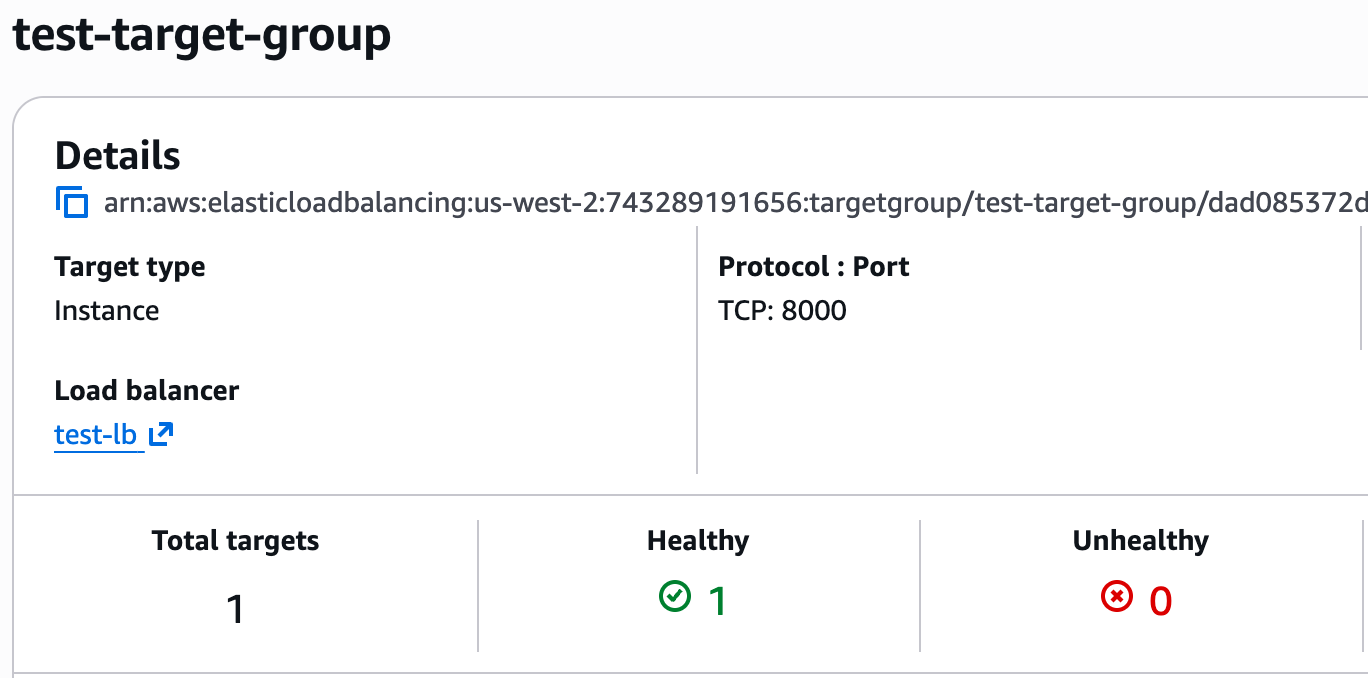 +
+If it appears as "Unhealthy" for some reason, please ensure the security group provides access to the service, that the health check is configured correctly, and of course that the service itself is available.
+
+**4. Enable Cross-Zone Load Balancing**
+
+If you selected more than one subnet for the load balancer above:
+* Navigate back to the "Load Balancer" screen
+* Choose the load balancer you created.
+* Click on Actions -> Edit load balancer attributes.
+* Enable the setting "Enable cross-zone load balancing".
+
+If you selected more than one subnet (availability zone) when creating the NLB in Step 2, navigate back to the Load Balancer, then select Actions → Edit load balancer attributes. From this page, select "Enable cross-zone load balancing" and save your changes.
+
+### Create a VPC Endpoint Service and approve access for Elementary
+
+**1. Create a VPC Endpoint Service**
+
+Navigate to the VPC page in AWS, go to "Endpoint services," and select "Create endpoint service." Please follow the wizard and fill in the following details:
+
+1. **Name** - Choose a name for your VPC endpoint service.
+2. **Load balancer type** - Network.
+3. **Available load balancers** - Select the network load balancer (NLB) created above.
+4. **Require acceptance for endpoint** - Yes (so new connections will require approval, see below)
+5. **Enable private DNS name** - No.
+6. **Supported IP address types** - IPv4.
+
+
+
+If it appears as "Unhealthy" for some reason, please ensure the security group provides access to the service, that the health check is configured correctly, and of course that the service itself is available.
+
+**4. Enable Cross-Zone Load Balancing**
+
+If you selected more than one subnet for the load balancer above:
+* Navigate back to the "Load Balancer" screen
+* Choose the load balancer you created.
+* Click on Actions -> Edit load balancer attributes.
+* Enable the setting "Enable cross-zone load balancing".
+
+If you selected more than one subnet (availability zone) when creating the NLB in Step 2, navigate back to the Load Balancer, then select Actions → Edit load balancer attributes. From this page, select "Enable cross-zone load balancing" and save your changes.
+
+### Create a VPC Endpoint Service and approve access for Elementary
+
+**1. Create a VPC Endpoint Service**
+
+Navigate to the VPC page in AWS, go to "Endpoint services," and select "Create endpoint service." Please follow the wizard and fill in the following details:
+
+1. **Name** - Choose a name for your VPC endpoint service.
+2. **Load balancer type** - Network.
+3. **Available load balancers** - Select the network load balancer (NLB) created above.
+4. **Require acceptance for endpoint** - Yes (so new connections will require approval, see below)
+5. **Enable private DNS name** - No.
+6. **Supported IP address types** - IPv4.
+
+ +
+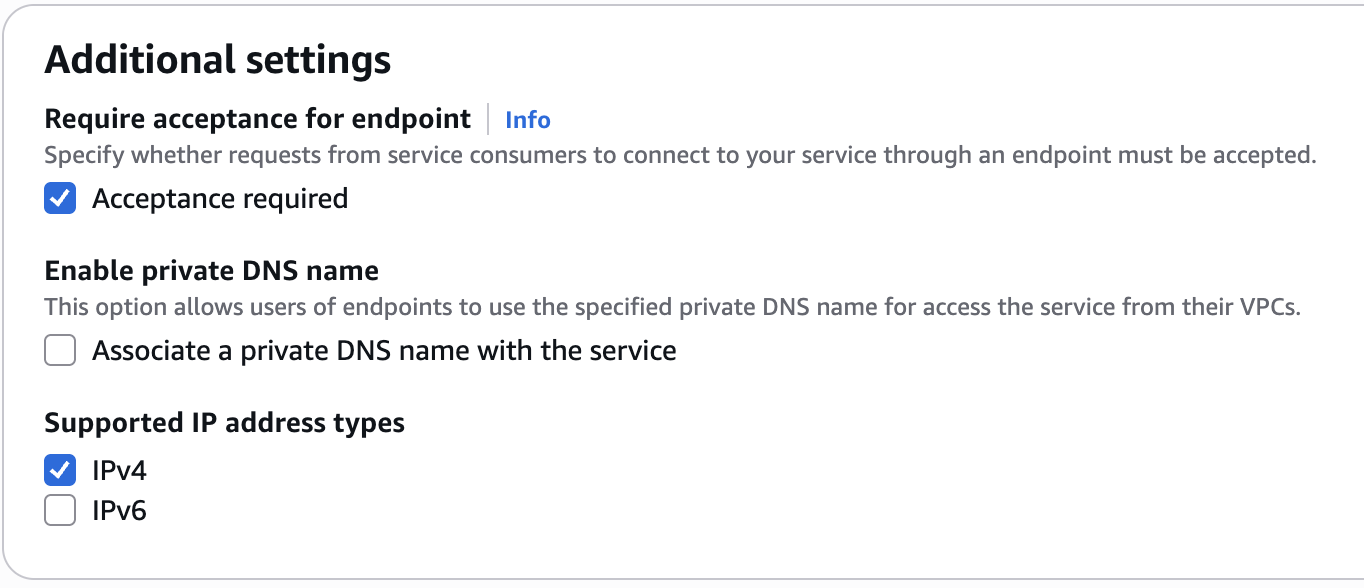 +
+Once the service is created, please go to the "Details" tab and save the "Service name" attribute, you will need later to provide it to the Elementary team.
+
+**2. Allow the Elementary Principal**
+
+Once the VPC endpoint service is successfully created, navigate to the "Allow principals tab" and click on "Allow Principals". Then add the following principal:
+```
+arn:aws:iam::743289191656:root
+```
+
+After the endpoint service finishes creating, navigate to the "Allow principals" section and select "Allow principals." Add Elementary's AWS account ID: `743289191656`.
+
+
+
+Once the service is created, please go to the "Details" tab and save the "Service name" attribute, you will need later to provide it to the Elementary team.
+
+**2. Allow the Elementary Principal**
+
+Once the VPC endpoint service is successfully created, navigate to the "Allow principals tab" and click on "Allow Principals". Then add the following principal:
+```
+arn:aws:iam::743289191656:root
+```
+
+After the endpoint service finishes creating, navigate to the "Allow principals" section and select "Allow principals." Add Elementary's AWS account ID: `743289191656`.
+
+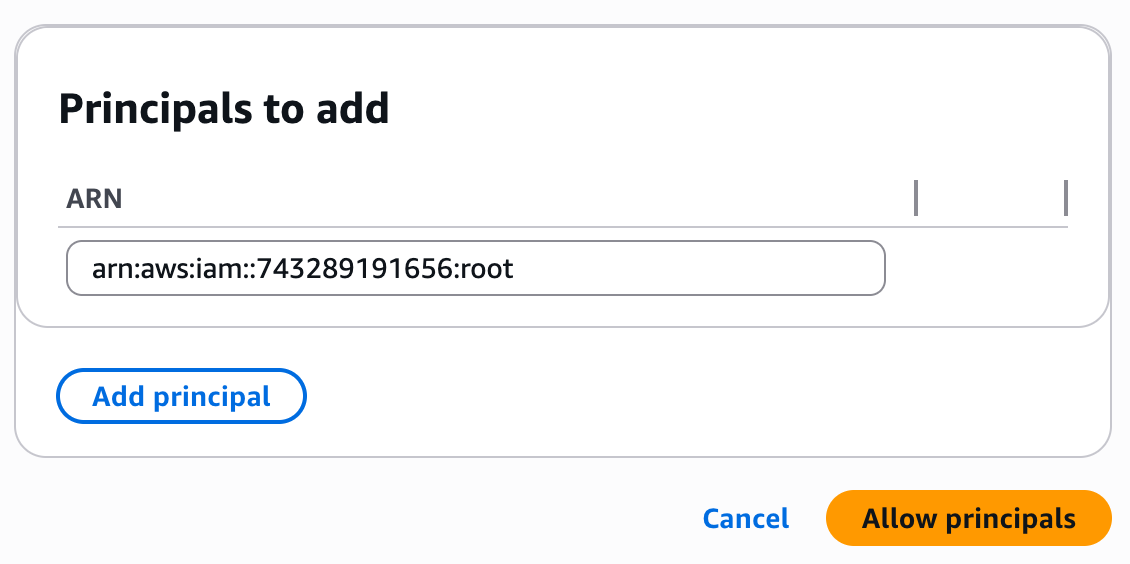 +
+**3. Contact the Elementary team to configure the PrivateLink connection**
+
+Please provide the Elementary team with the following details:
+1. Your AWS account ID.
+2. Your AWS region.
+3. The VPC endpoint service name (from step 1).
+4. The relevant service / integration (e.g. Github).
+5. The hostname you use internally to connect to your service.
+
+**4. Accept the endpoint connection request**
+
+Once you got confirmation from the Elementary team that the private link connection is set up, you need to approve
+the VPC endpoint connection from Elementary. You can do so with the following steps:
+* In the VPC page in your AWS console, go to "Endpoint Services", and then choose the endpoint service that you created in step 1.
+* Under the "Endpoint Connections" tab, you should see a pending connection, select it.
+* Click on Actions->Accept endpoint connection request to accept the connection.
+
+After a couple of minutes the connection should change from "Pending" to "Available".
+
+
+
+**3. Contact the Elementary team to configure the PrivateLink connection**
+
+Please provide the Elementary team with the following details:
+1. Your AWS account ID.
+2. Your AWS region.
+3. The VPC endpoint service name (from step 1).
+4. The relevant service / integration (e.g. Github).
+5. The hostname you use internally to connect to your service.
+
+**4. Accept the endpoint connection request**
+
+Once you got confirmation from the Elementary team that the private link connection is set up, you need to approve
+the VPC endpoint connection from Elementary. You can do so with the following steps:
+* In the VPC page in your AWS console, go to "Endpoint Services", and then choose the endpoint service that you created in step 1.
+* Under the "Endpoint Connections" tab, you should see a pending connection, select it.
+* Click on Actions->Accept endpoint connection request to accept the connection.
+
+After a couple of minutes the connection should change from "Pending" to "Available".
+
+ +
+**5. Notify the elementary team**
+
+Once the endpoint connection is approved and shows as "Available", please reach out to the Elementary team, so we will ensure the connection is ready and working.
diff --git a/docs/cloud/integrations/security-and-connectivity/ms-entra.mdx b/docs/cloud/integrations/security-and-connectivity/ms-entra.mdx
new file mode 100644
index 000000000..121631cf4
--- /dev/null
+++ b/docs/cloud/integrations/security-and-connectivity/ms-entra.mdx
@@ -0,0 +1,82 @@
+---
+title: "Microsoft Entra ID"
+sidebarTitle: "Microsoft Entra ID"
+---
+
+## Enabling SAML
+
+In order to enable SAML using Microsoft Entra ID (Previously Azure AD SSO), we need the following steps to be taken:
+
+
+
+**5. Notify the elementary team**
+
+Once the endpoint connection is approved and shows as "Available", please reach out to the Elementary team, so we will ensure the connection is ready and working.
diff --git a/docs/cloud/integrations/security-and-connectivity/ms-entra.mdx b/docs/cloud/integrations/security-and-connectivity/ms-entra.mdx
new file mode 100644
index 000000000..121631cf4
--- /dev/null
+++ b/docs/cloud/integrations/security-and-connectivity/ms-entra.mdx
@@ -0,0 +1,82 @@
+---
+title: "Microsoft Entra ID"
+sidebarTitle: "Microsoft Entra ID"
+---
+
+## Enabling SAML
+
+In order to enable SAML using Microsoft Entra ID (Previously Azure AD SSO), we need the following steps to be taken:
+
+ +
+ - Click on “New Application”
+
+
+
+ - Click on “New Application”
+
+ 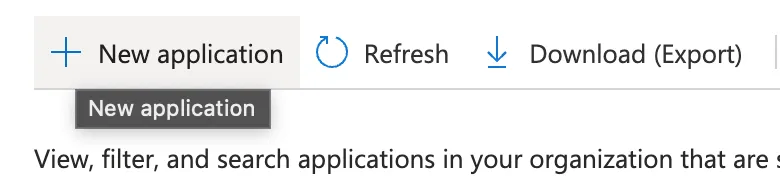 +
+ - Click on “Create your own application”
+
+
+
+ - Click on “Create your own application”
+
+ 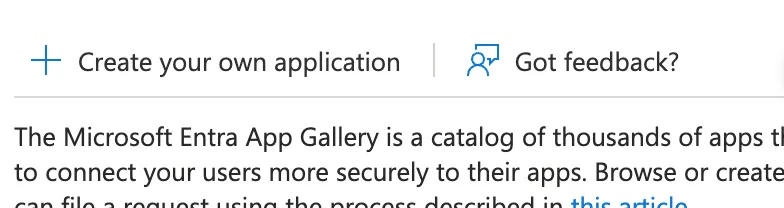 +
+ - Choose the last option in the side-window that opens and click “Create”
+
+
+
+ - Choose the last option in the side-window that opens and click “Create”
+
+ 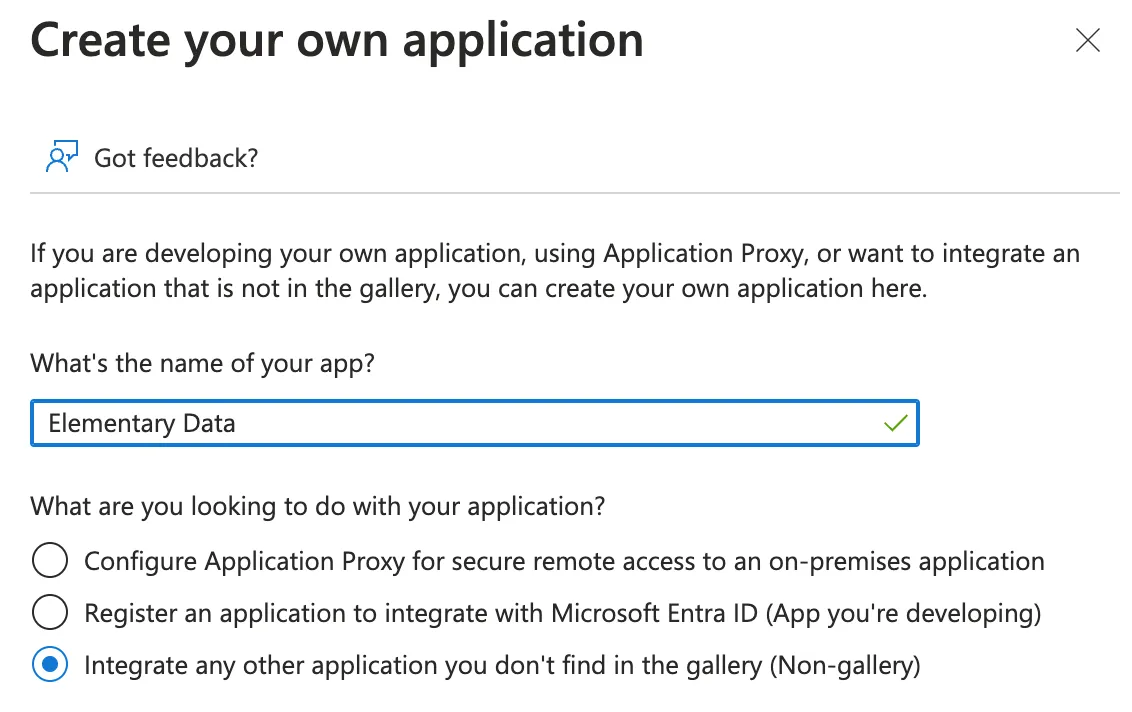 +
+ - In the App window that opens, click on “Single Sign-On”
+
+
+
+ - In the App window that opens, click on “Single Sign-On”
+
+ 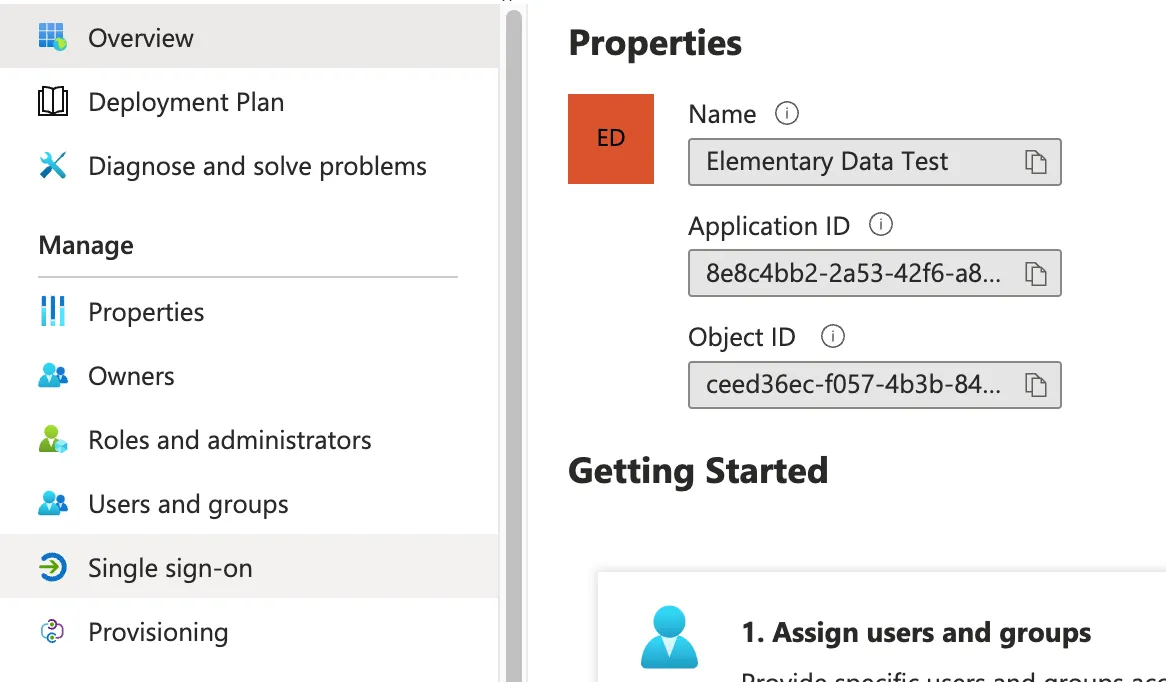 +
+ - Choose SAML
+
+
+
+ - Choose SAML
+
+ 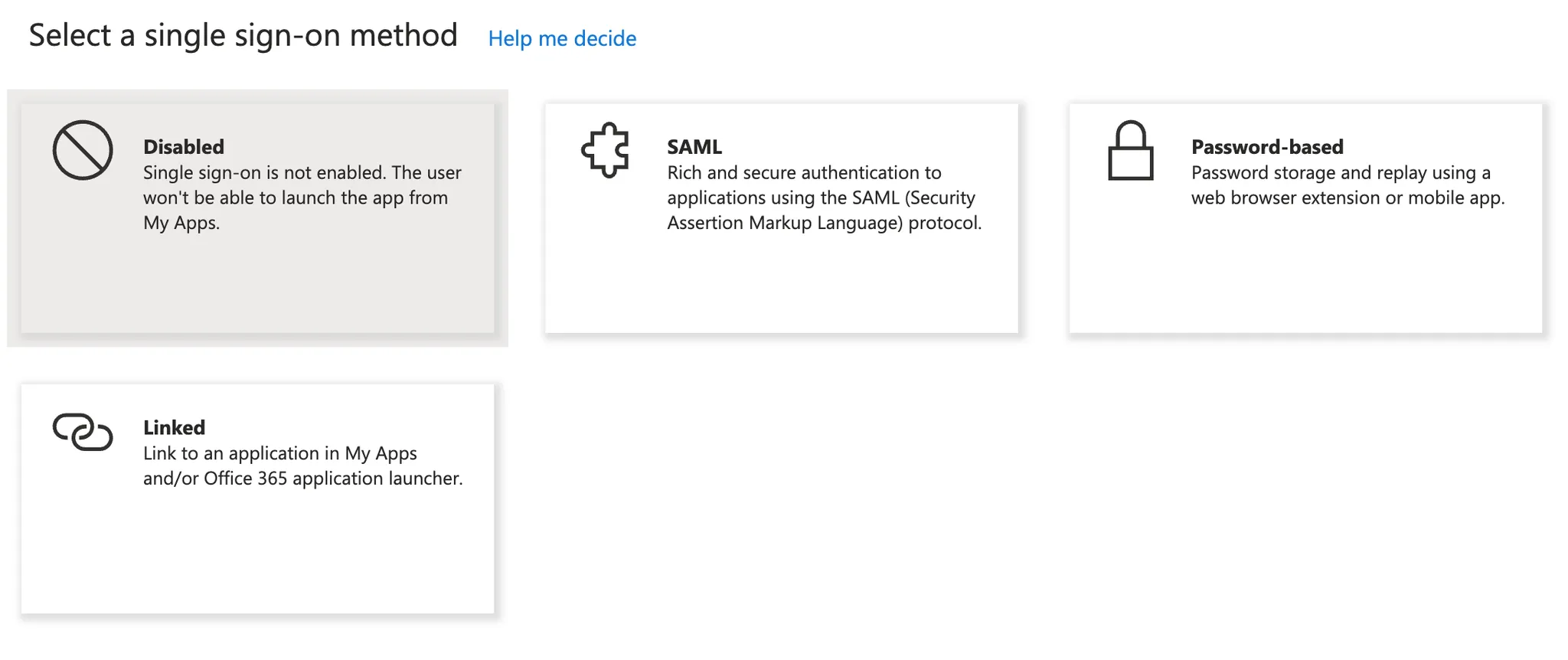 +
+ - Click on Edit on the “Basic SAML Configuration” section
+
+
+
+ - Click on Edit on the “Basic SAML Configuration” section
+
+ 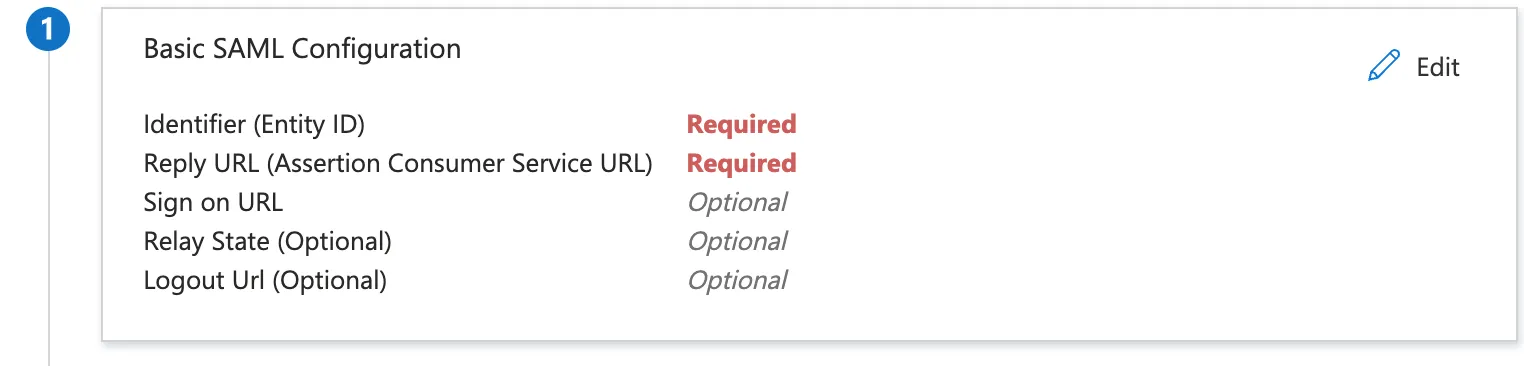 +
+ - Fill the following entries:
+ - Identifier (Entity ID) - `elementary`
+ - Reply URL - [`https://elementary-data.frontegg.com/auth/saml/callback`](https://elementary-data.frontegg.com/auth/saml/callback)
+ - Download the Federation Metadata XML.
+
+
+
+ - Fill the following entries:
+ - Identifier (Entity ID) - `elementary`
+ - Reply URL - [`https://elementary-data.frontegg.com/auth/saml/callback`](https://elementary-data.frontegg.com/auth/saml/callback)
+ - Download the Federation Metadata XML.
+
+ 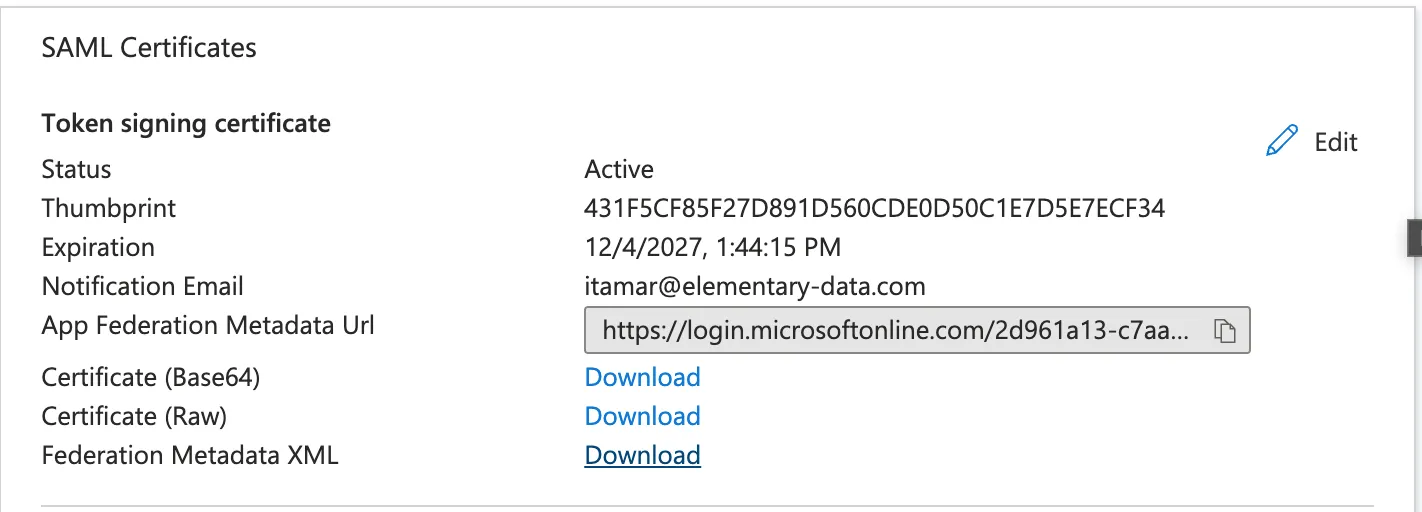 +
+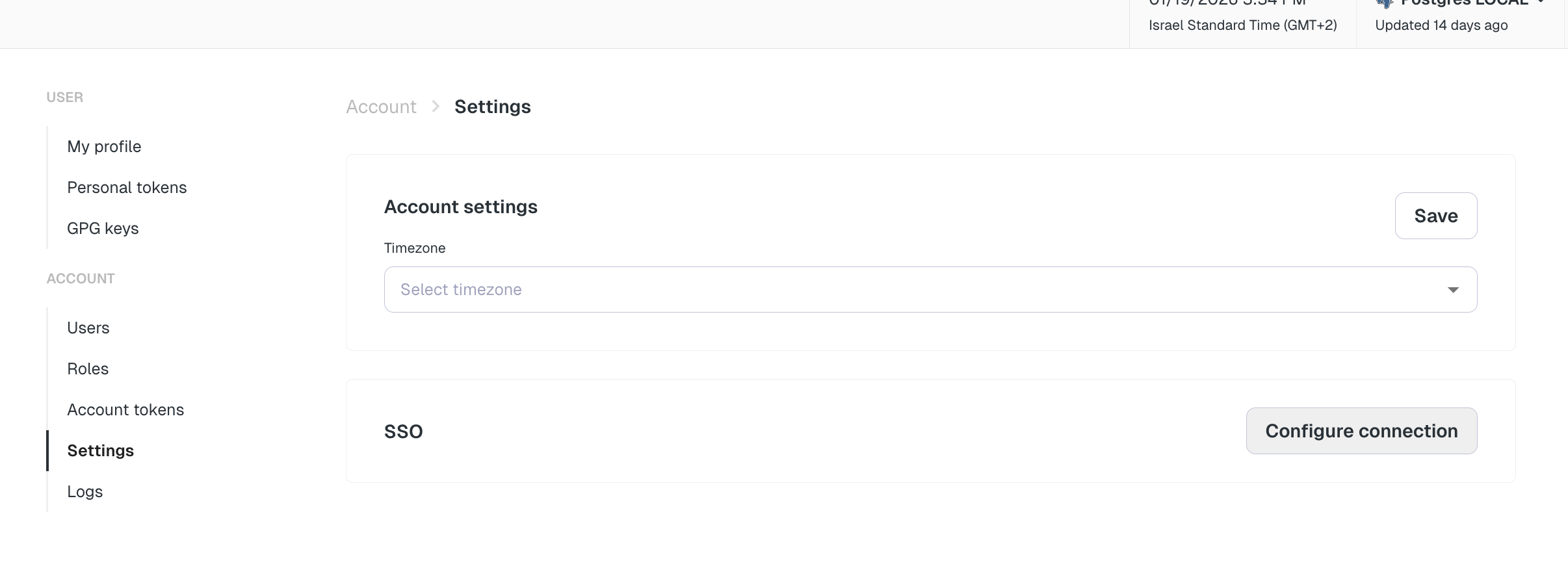 + - Fill in the form with the following details:
+ - SAML Metadata: Choose "Upload file", upload the Federation Metadata XML you downloaded.
+ - Domains: Add the domains you want to allow access to Elementary.
+ - Click on "Save" to save the configuration.
+
+ - Fill in the form with the following details:
+ - SAML Metadata: Choose "Upload file", upload the Federation Metadata XML you downloaded.
+ - Domains: Add the domains you want to allow access to Elementary.
+ - Click on "Save" to save the configuration.
+ 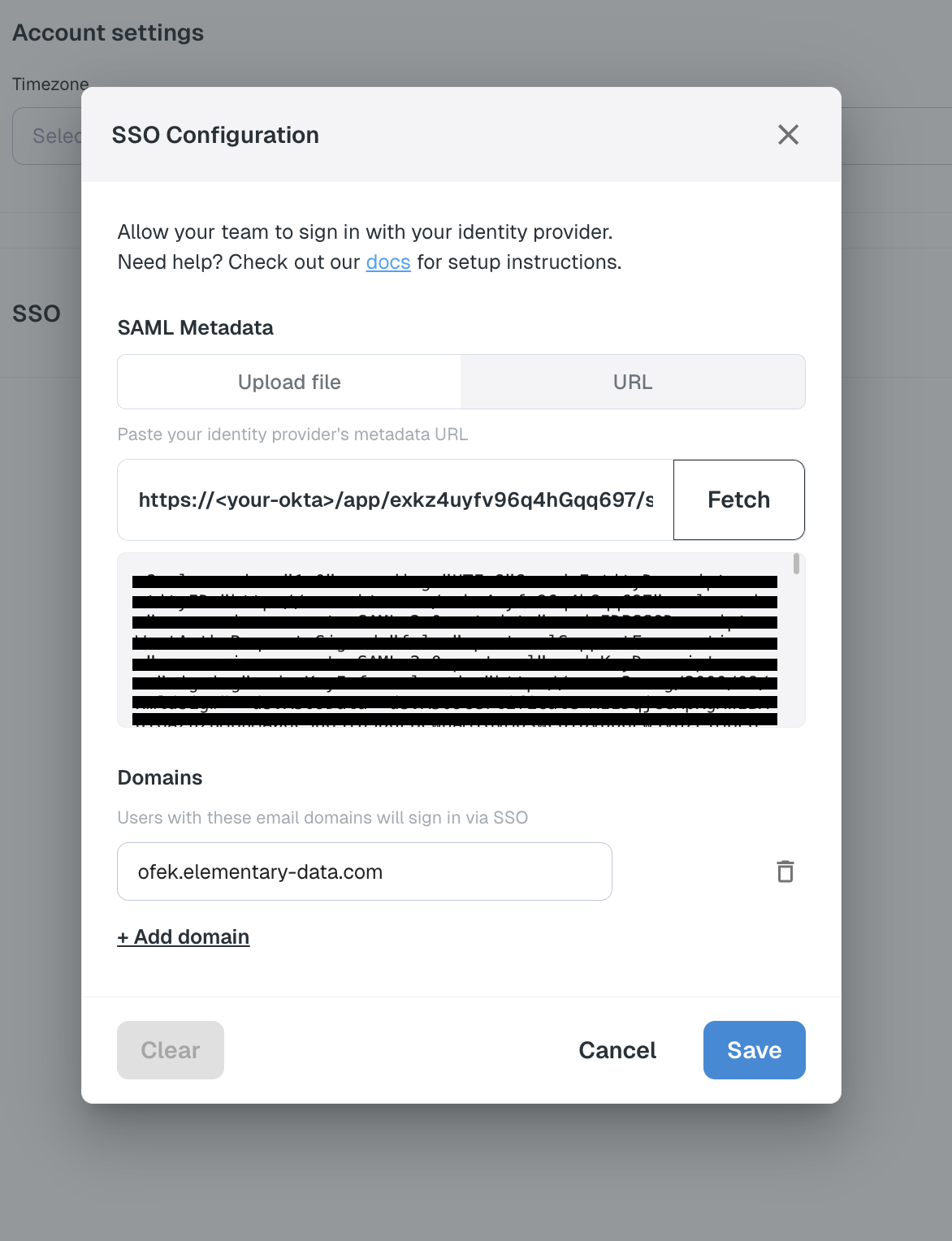 +
+  + Choose SAML 2.0 as the sign-in method:
+
+ Choose SAML 2.0 as the sign-in method:
+ 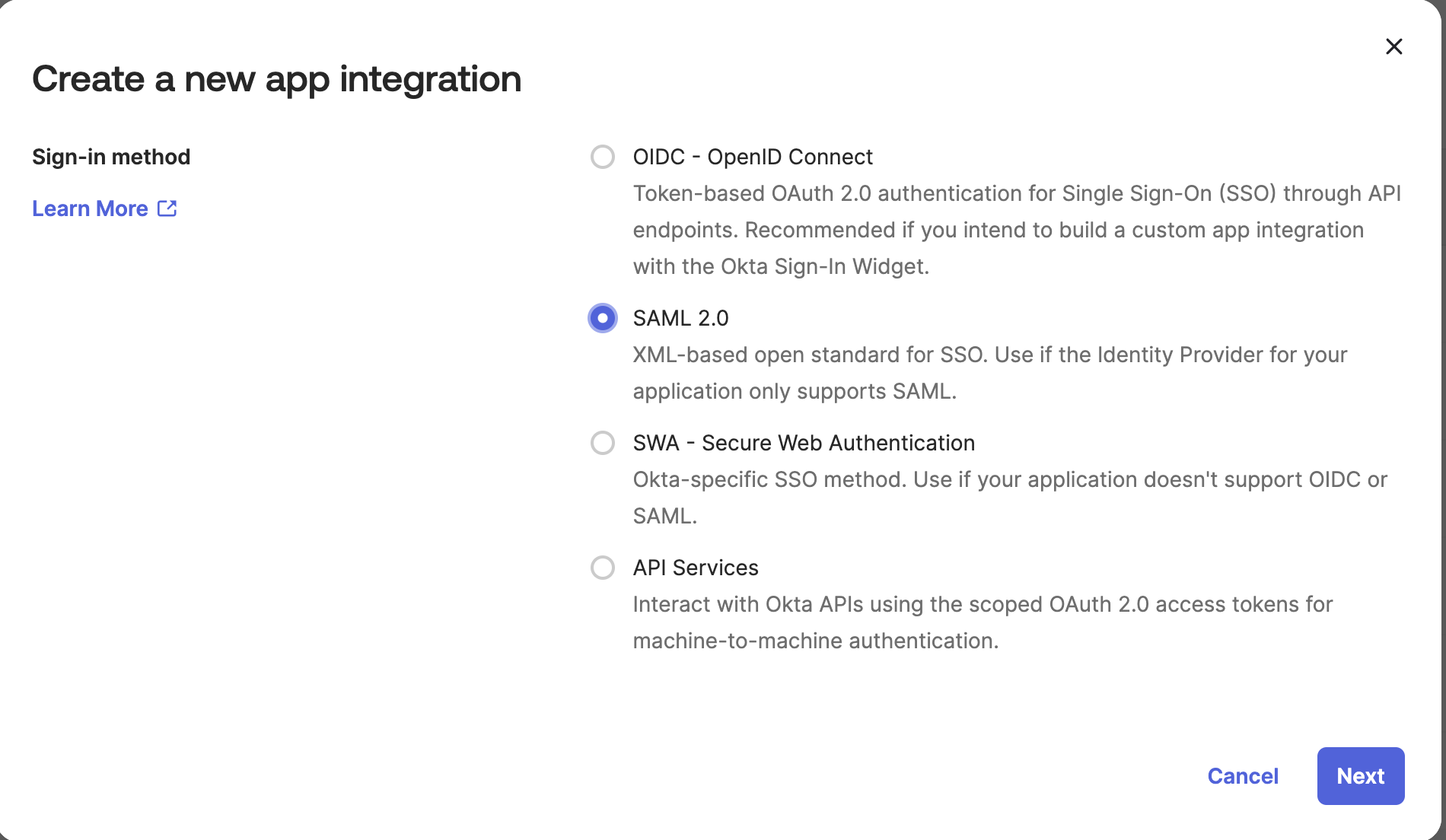 + - Name the app “Elementary Data” and click “Next”
+
+ - Name the app “Elementary Data” and click “Next”
+ 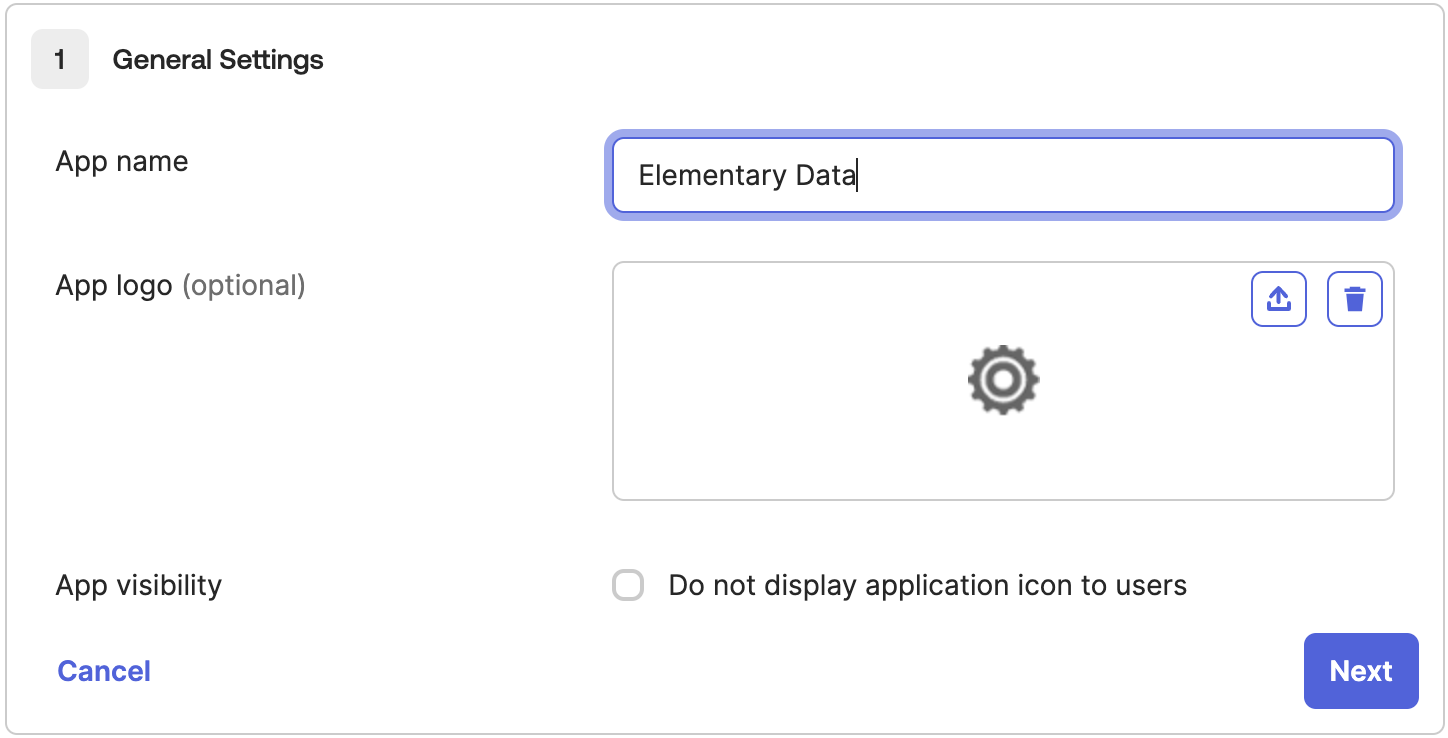 + - Under **SAML Settings**, please enter the following details:
+ - Single sign-on URL: **https://elementary-data.frontegg.com/auth/saml/callback**
+ - Audience URI (SP Entity ID): elementary
+ - Name ID Format: EmailAddress
+ - Application Username: Email
+ - Update application username on: Create and update
+
+ - Under **SAML Settings**, please enter the following details:
+ - Single sign-on URL: **https://elementary-data.frontegg.com/auth/saml/callback**
+ - Audience URI (SP Entity ID): elementary
+ - Name ID Format: EmailAddress
+ - Application Username: Email
+ - Update application username on: Create and update
+ 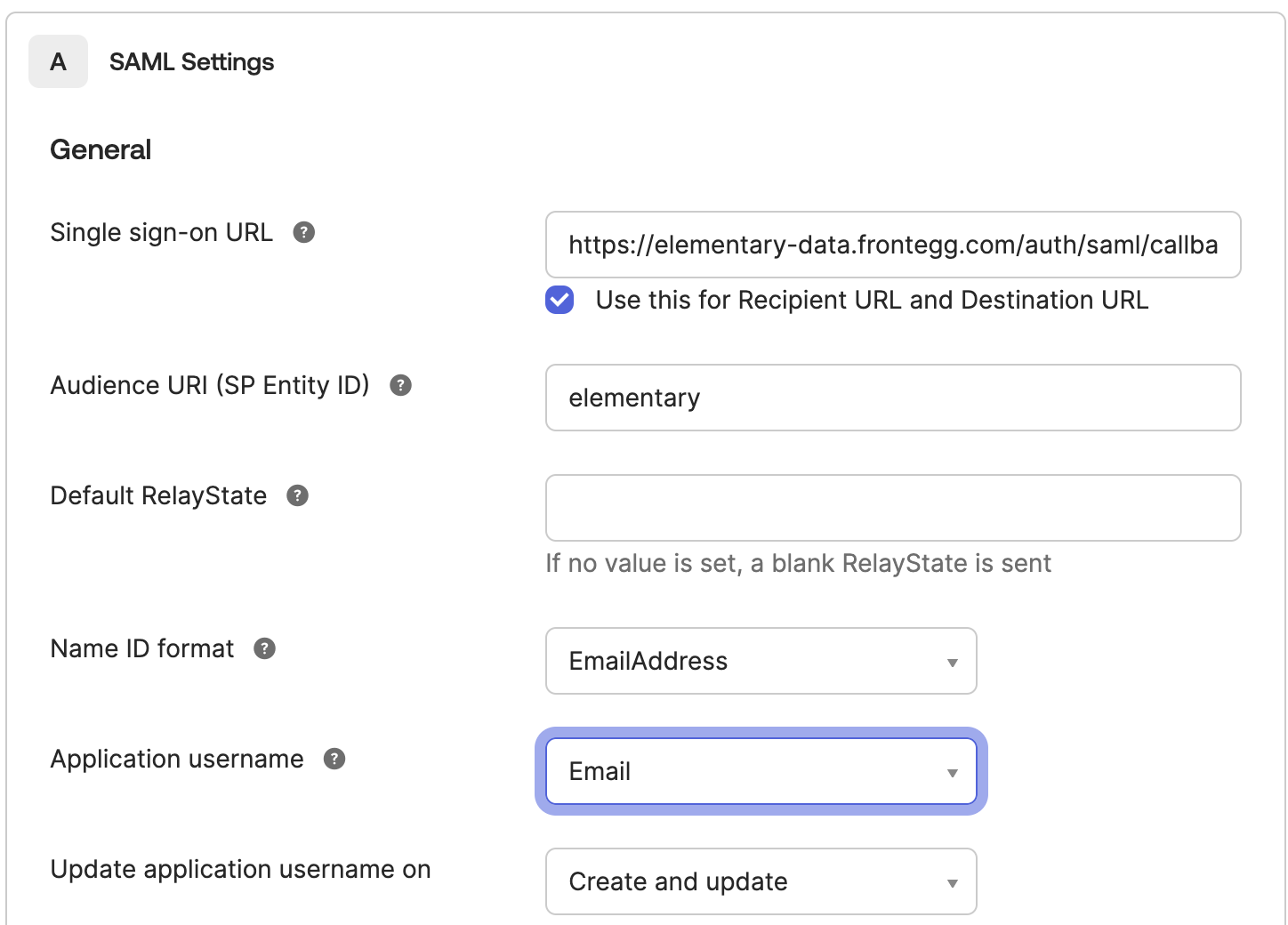 + - Click “Finish” on the next screen, and the app will be created!
+ - Now, let’s configure users / groups that have access to the app. To do so, please go to the “Assignments” tab and add relevant groups / users.
+ - Note -
+ - It is recommended to set up an “Elementary Users” group dedicated for this purpose, though you can also add access for individual users.
+ - The setting below is for **assignment** of users to your app, e.g. users that are permitted to login to Elementary via Okta. This does not cover actually provisioning the user in Elementary (this is covered in the next section).
+
+ - Click “Finish” on the next screen, and the app will be created!
+ - Now, let’s configure users / groups that have access to the app. To do so, please go to the “Assignments” tab and add relevant groups / users.
+ - Note -
+ - It is recommended to set up an “Elementary Users” group dedicated for this purpose, though you can also add access for individual users.
+ - The setting below is for **assignment** of users to your app, e.g. users that are permitted to login to Elementary via Okta. This does not cover actually provisioning the user in Elementary (this is covered in the next section).
+ 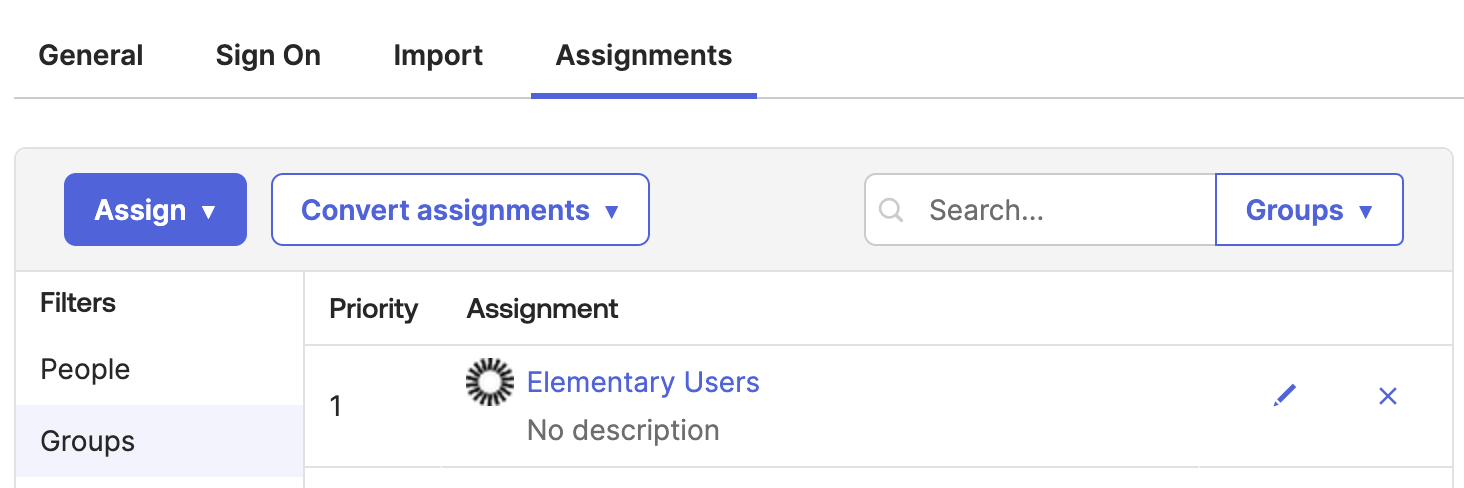 + - Go to the “Sign On” tab, and copy the link under Metadata URL:
+
+ - Go to the “Sign On” tab, and copy the link under Metadata URL:
+ 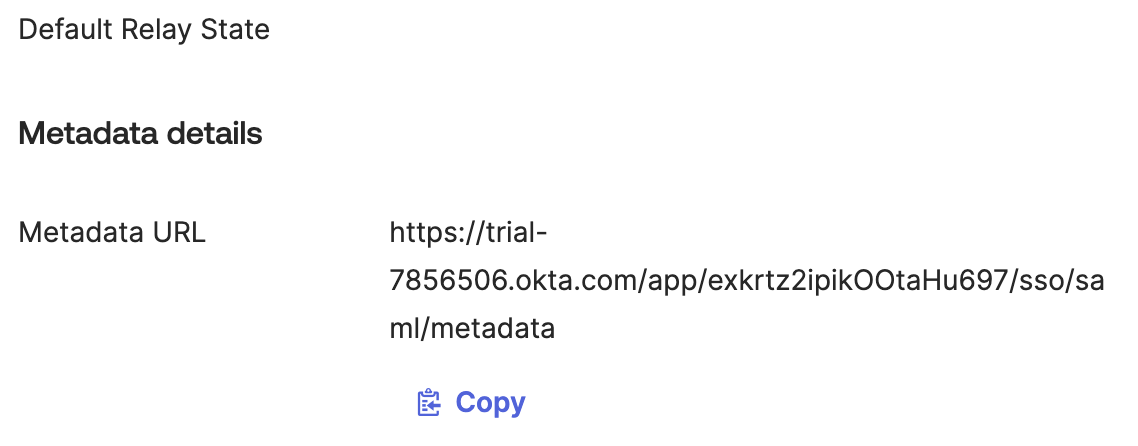 +
+ - Fill in the form with the following details:
+ - SAML Metadata: Choose "URL", paste the link you copied from Okta into the URL field, and click "Fetch".
+ - Domains: Add the domains you want to allow access to Elementary.
+ - Click on "Save" to save the configuration.
+
+
+
+ - Fill in the form with the following details:
+ - SAML Metadata: Choose "URL", paste the link you copied from Okta into the URL field, and click "Fetch".
+ - Domains: Add the domains you want to allow access to Elementary.
+ - Click on "Save" to save the configuration.
+
+  + A new Provisioning tab should appear, click it and then click Edit.
+
+ A new Provisioning tab should appear, click it and then click Edit.
+  + - Please fill the following details:
+ - **SCIM connector base URL** - _value from Elementary Provisioning section_
+ - **Unique identifier field for users** - email
+ - **Supported provisioning actions** - mark all the “Push” settings (New users, Profile updates and Groups).
+ - **Authentication Mode -** HTTP Header
+ - **Authorization** - _access token from Elementary Provisioning section_
+
+ When you are done, click on **Test Connector Configuration**
+
+ - Please fill the following details:
+ - **SCIM connector base URL** - _value from Elementary Provisioning section_
+ - **Unique identifier field for users** - email
+ - **Supported provisioning actions** - mark all the “Push” settings (New users, Profile updates and Groups).
+ - **Authentication Mode -** HTTP Header
+ - **Authorization** - _access token from Elementary Provisioning section_
+
+ When you are done, click on **Test Connector Configuration**
+ 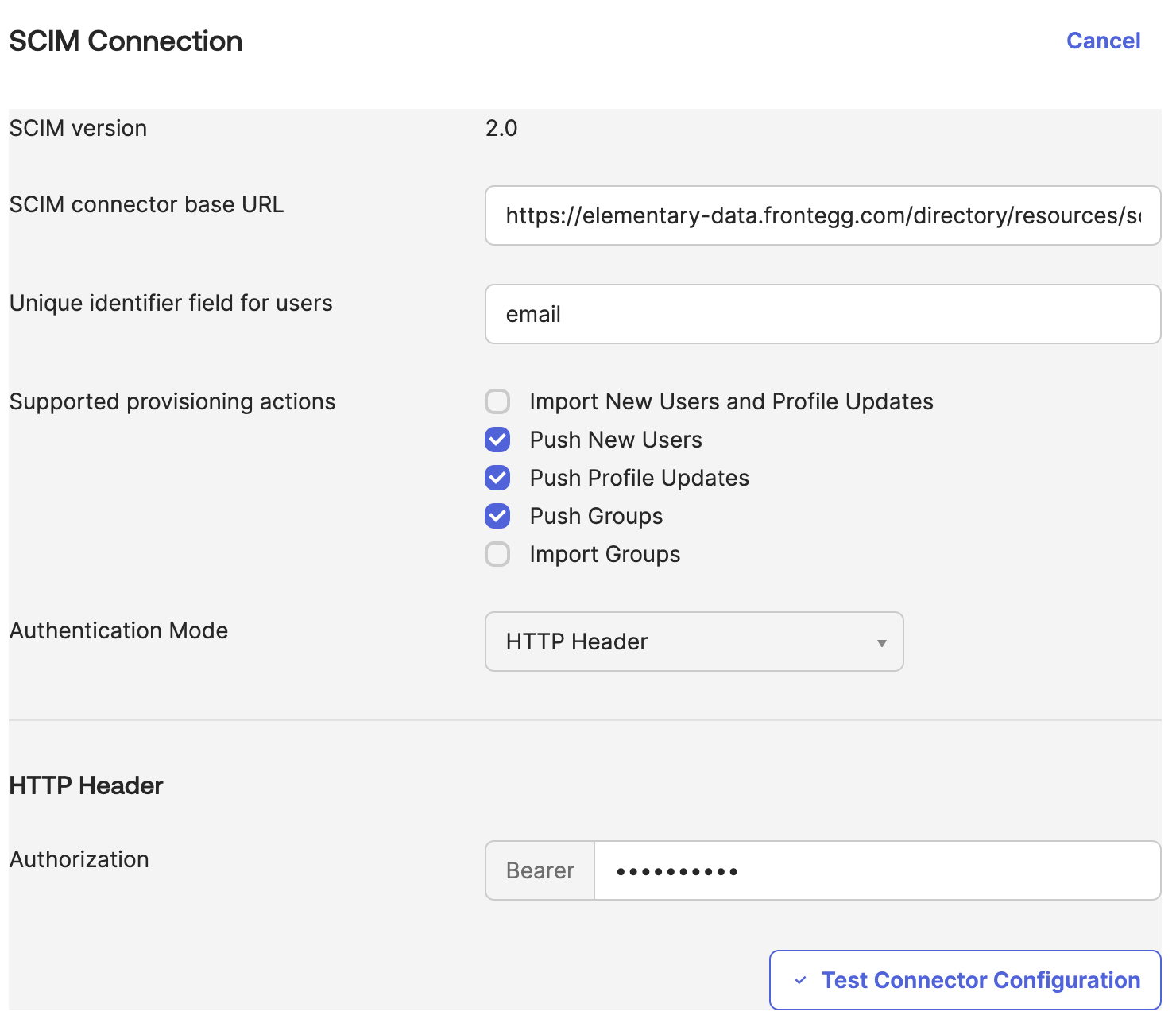 + Ensure that all the marked provisioning actions were successful:
+
+ Ensure that all the marked provisioning actions were successful:
+ 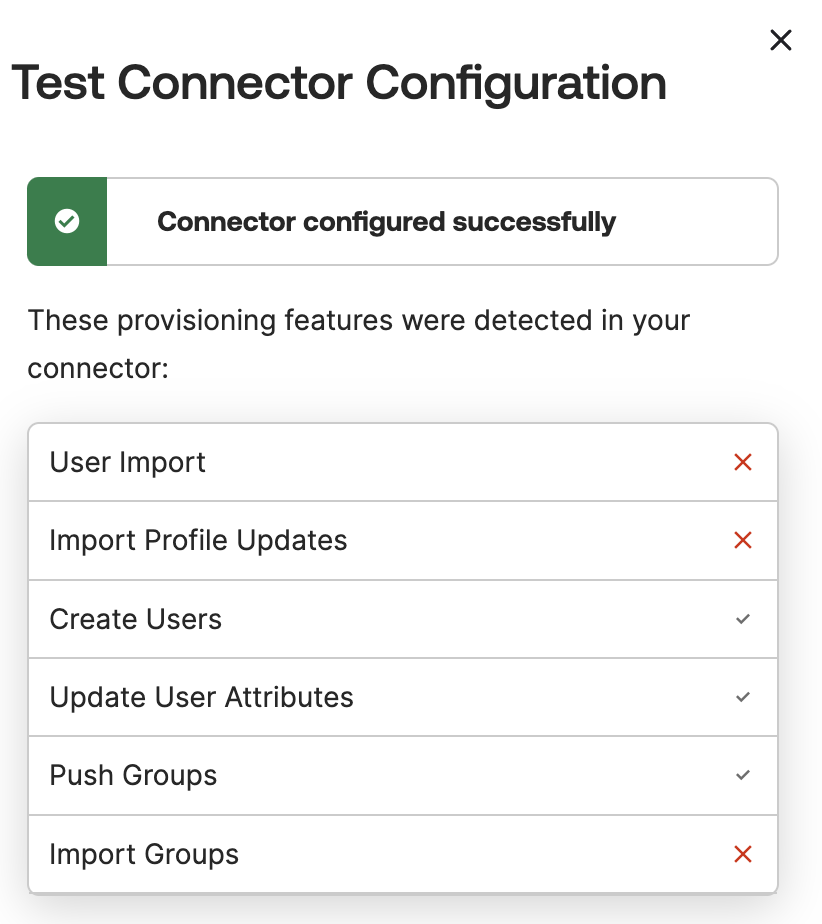 + - Click **Save** to update the provisioning configuration.
+ - Click the **To App** section on the left and click **Edit**:
+
+ - Click **Save** to update the provisioning configuration.
+ - Click the **To App** section on the left and click **Edit**:
+ 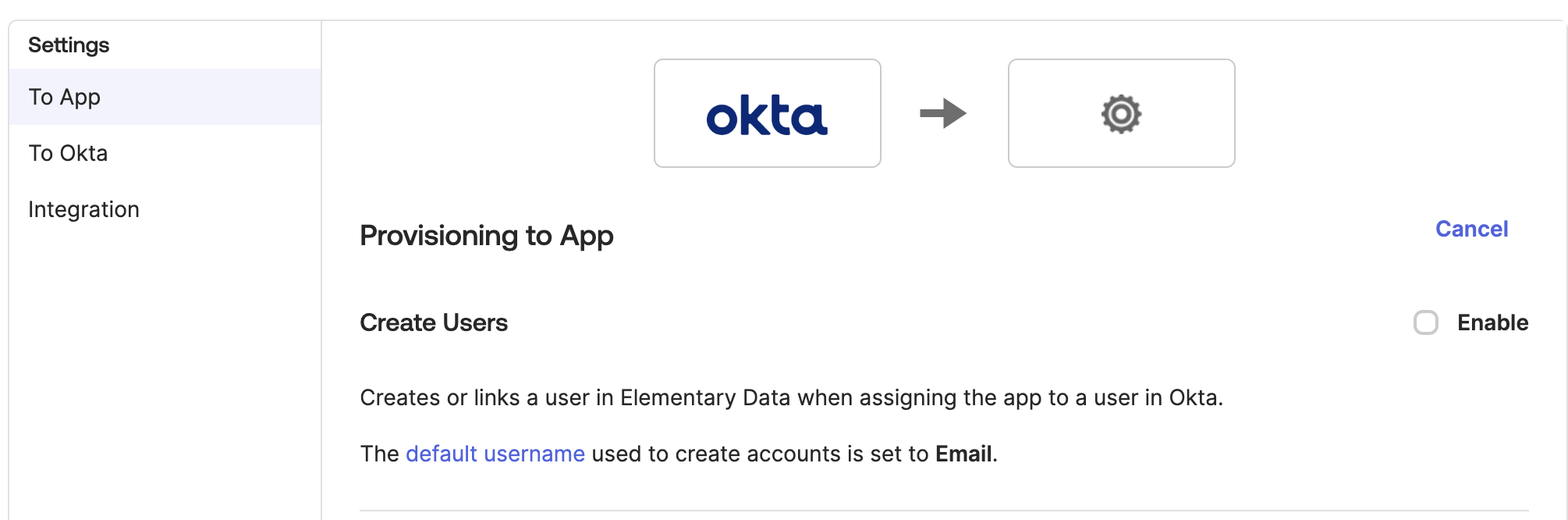 + - Please enable the settings:
+ - Create Users
+ - Update User Attributes
+ - Deactivate Users
+
+ And click **Save.**
+
+
+ - Please enable the settings:
+ - Create Users
+ - Update User Attributes
+ - Deactivate Users
+
+ And click **Save.**
+
+ 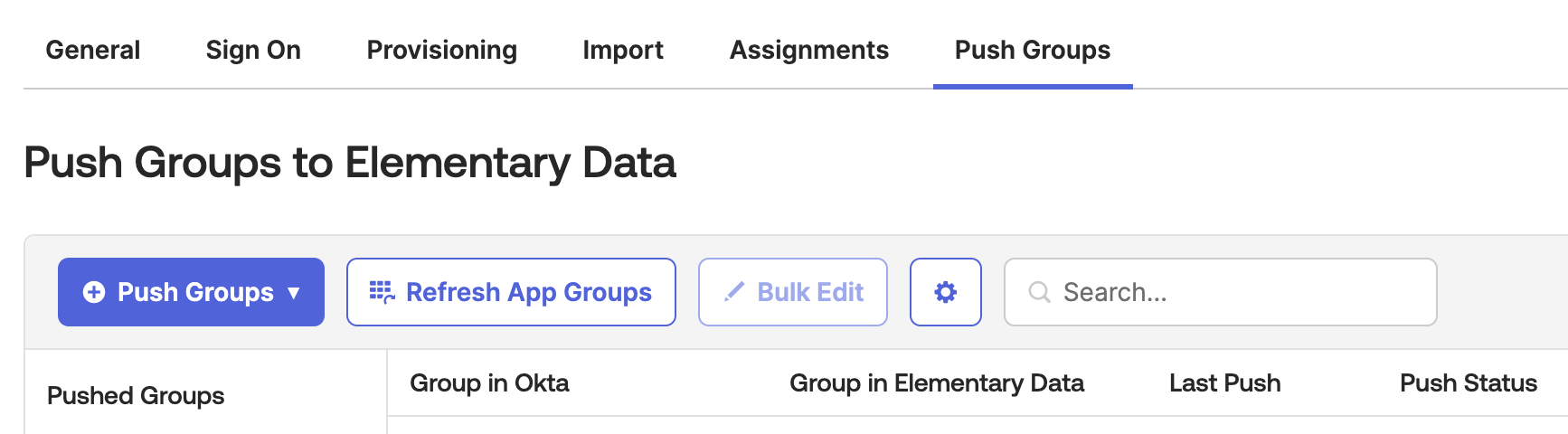 +- Add the groups you would like to push:
+
+- Add the groups you would like to push:
+ +- If the **Push Status** appears as **Active** - it means the groups were successfully pushed to Elementary.
+- Please ask the Elementary team to map the groups you pushed to roles within Elementary. In this case the mapping is clear:
+ - **Elementary Admins** - Admin.
+ - **Elementary Editors** - Can Edit.
+- Once this is done, you should be able to see in the **Team** page in Elementary all the users and their correct roles.
+
+- If the **Push Status** appears as **Active** - it means the groups were successfully pushed to Elementary.
+- Please ask the Elementary team to map the groups you pushed to roles within Elementary. In this case the mapping is clear:
+ - **Elementary Admins** - Admin.
+ - **Elementary Editors** - Can Edit.
+- Once this is done, you should be able to see in the **Team** page in Elementary all the users and their correct roles.
+ diff --git a/docs/cloud/integrations/transformation-and-orchestration/dbt-fusion.mdx b/docs/cloud/integrations/transformation-and-orchestration/dbt-fusion.mdx
new file mode 100644
index 000000000..b1ec55e68
--- /dev/null
+++ b/docs/cloud/integrations/transformation-and-orchestration/dbt-fusion.mdx
@@ -0,0 +1,7 @@
+---
+title: "dbt Fusion (Beta)"
+---
+
+import DbtFusion from '/snippets/integrations/dbt-fusion.mdx';
+
+
diff --git a/docs/cloud/integrations/transformation-and-orchestration/dbt-fusion.mdx b/docs/cloud/integrations/transformation-and-orchestration/dbt-fusion.mdx
new file mode 100644
index 000000000..b1ec55e68
--- /dev/null
+++ b/docs/cloud/integrations/transformation-and-orchestration/dbt-fusion.mdx
@@ -0,0 +1,7 @@
+---
+title: "dbt Fusion (Beta)"
+---
+
+import DbtFusion from '/snippets/integrations/dbt-fusion.mdx';
+
+ +
+ +
+### 🔥 **Welcome Blaze Fixer – Incident Triage & Resolution**
+
+> Let’s give a warm welcome (pun intended) to Blaze Fixer (pronouns: fix/fixes).
+>
+>
+>**Career highlight**: Resolved a critical pipeline outage 6 minutes before it happened.
+>
+>**Specialty**: Incident triage, root cause tracing, and putting out fires before they hit Slack.
+>
+>**Outside of work**: Volunteers as a chaos engineer in simulated war rooms.
+>
+> Welcome, Blaze. We feel safer already.
+>
+
+### ✅ **Welcome Val E. Dator – Test Coverage & Recommendations**
+
+> Say hello to Val E. Dator, joining as our AI-powered test strategist (pronouns: test/tests).
+>
+>
+>**Career highlight**: Once added 142 missing tests during a lunch break.
+>
+>**Specialty**: Auto-generating test coverage plans, recommending the right tests for every edge case, and proving you forgot something—politely.
+>
+>**Outside of work**: Writes dbt tests for her Netflix queue. Flags genre drift, inconsistent ratings, and suspicious rewatch patterns.
+>
+> We’re thrilled to have you, Val. Our models are already sleeping better at night.
+>
+
+### 🗂 **Welcome Cat A. Logue – Metadata Governance & Discovery**
+
+> Please welcome Cat A. Logue to the team (pronouns: tag/tags)
+>
+>
+>**Career highlight**: Tagged and documented 18,492 data assets across 7 environments before her morning coffee.
+>
+>**Specialty**: Organizing chaos. Tags, owners, descriptions, policies—if it exists, she governs it.
+>
+>**Outside of work**: Adds metadata tags to everything she owns. The toaster is now “device_type: appliance, heat_source: electric, owner: Cat.”
+>
+> Welcome aboard, Cat. Our catalog already looks cleaner.
+>
+
+
+### 🪓 **Welcome Bill Cutter - Performance & Cost**
+
+> Please welcome Bill Cutter to the team! (pronouns: cost/cuts)
+>
+>
+> **Career highlight**: Saved $73K/month by killing off nightly model runs that hadn’t been queried in 6 months.
+>
+> **Specialty**: Finds the jobs no one remembers, the models no one needs, and the compute they’re silently burning. Then cuts them.
+>
+> **Outside of work**: Writes a performance blog called *Drop Table Everything*. Posts are short. Just like your idle query lifespan.
+>
+> Welcome, Bill. We’re already feeling...lighter.
+>
+>
diff --git a/docs/cloud/resources/business-case-data-observability-platform.mdx b/docs/cloud/resources/business-case-data-observability-platform.mdx
new file mode 100644
index 000000000..a78f11580
--- /dev/null
+++ b/docs/cloud/resources/business-case-data-observability-platform.mdx
@@ -0,0 +1,25 @@
+---
+title: "When do I need a data observability platform?"
+sidebarTitle: "When to add data observability"
+---
+
+
+### If the consequences of data issues are high
+If you are running performance marketing budgets of $millions, a data issue can result in a loss of hundreds of thousands of dollars.
+In these cases, the ability to detect and resolve issues fast is business-critical. It typically involves multiple teams and the ability to measure, track, and report on data quality.
+
+### If data is scaling faster than the data team
+The scale and complexity of modern data environments make it impossible for teams to manually manage quality without expanding the team. A data observability platform enables automation and collaboration, ensuring data quality is maintained as data continues to grow, without impacting team efficiency.
+
+### Common use cases
+If your data is being used in one of the following use cases, you should consider adding a data observability platform:
+- Self-service analytics
+- Data activation
+- Powering AI & ML products
+- Embedded analytics
+- Performance marketing
+- Regulatory reporting
+- A/B testing and experiments
+
+## Why isn't the open-source package enough?
+The open-source package was designed for engineers that want to monitor their dbt project. The Cloud Platform was designed to support the complex, multifaceted requirements of larger teams and organizations, providing a holistic observability solution.
\ No newline at end of file
diff --git a/docs/cloud/resources/community.mdx b/docs/cloud/resources/community.mdx
new file mode 100644
index 000000000..fc79fac9a
--- /dev/null
+++ b/docs/cloud/resources/community.mdx
@@ -0,0 +1,9 @@
+---
+title: "Community"
+url: "https://www.elementary-data.com/community"
+---
+
+
+
+### 🔥 **Welcome Blaze Fixer – Incident Triage & Resolution**
+
+> Let’s give a warm welcome (pun intended) to Blaze Fixer (pronouns: fix/fixes).
+>
+>
+>**Career highlight**: Resolved a critical pipeline outage 6 minutes before it happened.
+>
+>**Specialty**: Incident triage, root cause tracing, and putting out fires before they hit Slack.
+>
+>**Outside of work**: Volunteers as a chaos engineer in simulated war rooms.
+>
+> Welcome, Blaze. We feel safer already.
+>
+
+### ✅ **Welcome Val E. Dator – Test Coverage & Recommendations**
+
+> Say hello to Val E. Dator, joining as our AI-powered test strategist (pronouns: test/tests).
+>
+>
+>**Career highlight**: Once added 142 missing tests during a lunch break.
+>
+>**Specialty**: Auto-generating test coverage plans, recommending the right tests for every edge case, and proving you forgot something—politely.
+>
+>**Outside of work**: Writes dbt tests for her Netflix queue. Flags genre drift, inconsistent ratings, and suspicious rewatch patterns.
+>
+> We’re thrilled to have you, Val. Our models are already sleeping better at night.
+>
+
+### 🗂 **Welcome Cat A. Logue – Metadata Governance & Discovery**
+
+> Please welcome Cat A. Logue to the team (pronouns: tag/tags)
+>
+>
+>**Career highlight**: Tagged and documented 18,492 data assets across 7 environments before her morning coffee.
+>
+>**Specialty**: Organizing chaos. Tags, owners, descriptions, policies—if it exists, she governs it.
+>
+>**Outside of work**: Adds metadata tags to everything she owns. The toaster is now “device_type: appliance, heat_source: electric, owner: Cat.”
+>
+> Welcome aboard, Cat. Our catalog already looks cleaner.
+>
+
+
+### 🪓 **Welcome Bill Cutter - Performance & Cost**
+
+> Please welcome Bill Cutter to the team! (pronouns: cost/cuts)
+>
+>
+> **Career highlight**: Saved $73K/month by killing off nightly model runs that hadn’t been queried in 6 months.
+>
+> **Specialty**: Finds the jobs no one remembers, the models no one needs, and the compute they’re silently burning. Then cuts them.
+>
+> **Outside of work**: Writes a performance blog called *Drop Table Everything*. Posts are short. Just like your idle query lifespan.
+>
+> Welcome, Bill. We’re already feeling...lighter.
+>
+>
diff --git a/docs/cloud/resources/business-case-data-observability-platform.mdx b/docs/cloud/resources/business-case-data-observability-platform.mdx
new file mode 100644
index 000000000..a78f11580
--- /dev/null
+++ b/docs/cloud/resources/business-case-data-observability-platform.mdx
@@ -0,0 +1,25 @@
+---
+title: "When do I need a data observability platform?"
+sidebarTitle: "When to add data observability"
+---
+
+
+### If the consequences of data issues are high
+If you are running performance marketing budgets of $millions, a data issue can result in a loss of hundreds of thousands of dollars.
+In these cases, the ability to detect and resolve issues fast is business-critical. It typically involves multiple teams and the ability to measure, track, and report on data quality.
+
+### If data is scaling faster than the data team
+The scale and complexity of modern data environments make it impossible for teams to manually manage quality without expanding the team. A data observability platform enables automation and collaboration, ensuring data quality is maintained as data continues to grow, without impacting team efficiency.
+
+### Common use cases
+If your data is being used in one of the following use cases, you should consider adding a data observability platform:
+- Self-service analytics
+- Data activation
+- Powering AI & ML products
+- Embedded analytics
+- Performance marketing
+- Regulatory reporting
+- A/B testing and experiments
+
+## Why isn't the open-source package enough?
+The open-source package was designed for engineers that want to monitor their dbt project. The Cloud Platform was designed to support the complex, multifaceted requirements of larger teams and organizations, providing a holistic observability solution.
\ No newline at end of file
diff --git a/docs/cloud/resources/community.mdx b/docs/cloud/resources/community.mdx
new file mode 100644
index 000000000..fc79fac9a
--- /dev/null
+++ b/docs/cloud/resources/community.mdx
@@ -0,0 +1,9 @@
+---
+title: "Community"
+url: "https://www.elementary-data.com/community"
+---
+
+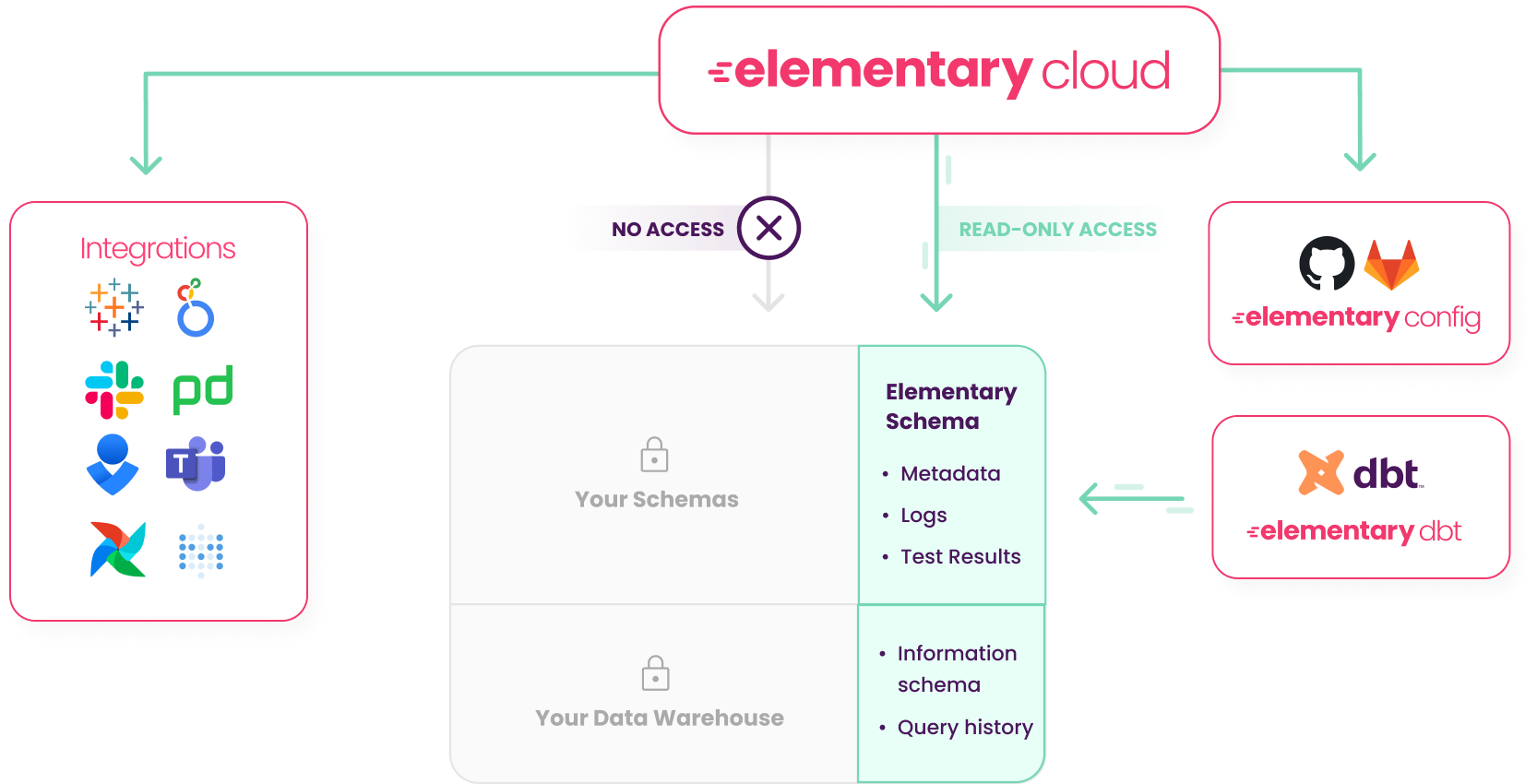 +
+
+
+## How it works?
+1. You install the Elementary dbt package in your dbt project and configure it to write to it's own schema, the Elementary schema.
+2. The package writes test results, run results, logs and metadata to the Elementary schema.
+3. The cloud service only requires `read access` to the Elementary schema, not to schemas where your sensitive data is stored.
+4. The cloud service connects to sync the Elementary schema using an **encrypted connection** and a **static IP address** that you will need to add to your allowlist.
+
+
+##
+
+
+[Read about Security and Privacy](/cloud/general/security-and-privacy)
diff --git a/docs/cloud/resources/pricing.mdx b/docs/cloud/resources/pricing.mdx
new file mode 100644
index 000000000..197ecc538
--- /dev/null
+++ b/docs/cloud/resources/pricing.mdx
@@ -0,0 +1,9 @@
+---
+title: "Pricing"
+url: "https://www.elementary-data.com/pricing"
+---
+
+
+
+
+
+## How it works?
+1. You install the Elementary dbt package in your dbt project and configure it to write to it's own schema, the Elementary schema.
+2. The package writes test results, run results, logs and metadata to the Elementary schema.
+3. The cloud service only requires `read access` to the Elementary schema, not to schemas where your sensitive data is stored.
+4. The cloud service connects to sync the Elementary schema using an **encrypted connection** and a **static IP address** that you will need to add to your allowlist.
+
+
+##
+
+
+[Read about Security and Privacy](/cloud/general/security-and-privacy)
diff --git a/docs/cloud/resources/pricing.mdx b/docs/cloud/resources/pricing.mdx
new file mode 100644
index 000000000..197ecc538
--- /dev/null
+++ b/docs/cloud/resources/pricing.mdx
@@ -0,0 +1,9 @@
+---
+title: "Pricing"
+url: "https://www.elementary-data.com/pricing"
+---
+
+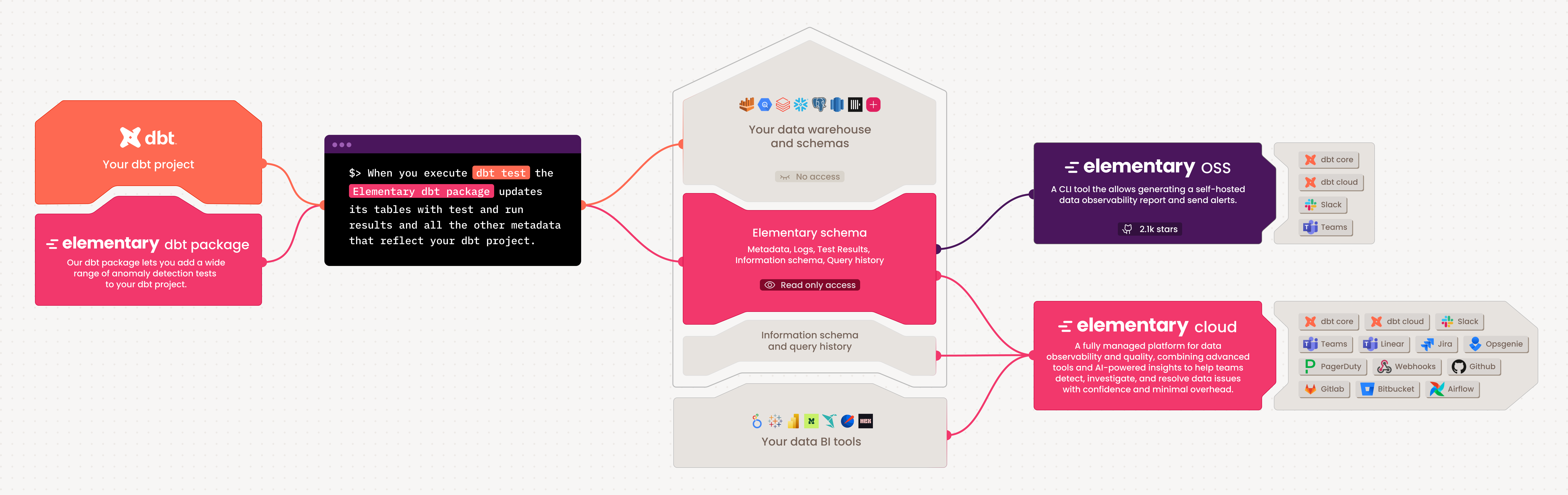 +
+Elementary offers a modular observability stack built for dbt-based data workflows. At the foundation is an open-source dbt package that captures key metadata and test results from your dbt project. This package powers both the self-hosted CLI and the fully managed Cloud Platform, which is built on top of it to provide wider visibility, automations, scale and advanced reports.
+
+## Products
+
+Whether you're starting small or scaling observability across your organization, you can choose the setup that fits your team—while unlocking more value as your needs evolve.
+
+### [**Elementary dbt package (OSS)**](/data-tests/dbt/dbt-package)
+
+The Elementary dbt package is open source and runs in your existing dbt workflows. It collects metadata, test results, and lineage from your dbt runs, and also enables Elementary’s anomaly detection tests.
+
+Use it to:
+- Save dbt artifacts, test and run results in your data warehouse
+- Run pre-built anomaly detection and schema changes tests
+
+### [Elementary CLI (OSS)](/oss/oss-introduction)
+
+###
+
+Elementary CLI help teams adopt foundational data observability within dbt. It centralizes metadata and test results to a self-hosted report, and provides a starting point for alerts and monitoring. It’s a great way to introduce reliability into engineering workflows.
+
+Use it to:
+
+- Present test results and metadata from your dbt project in a visual report
+- Send basic alerts over test and schema failures
+
+Setup Elementary OSS [here](https://docs.elementary-data.com/oss/quickstart/quickstart-cli-package).
+
+### [**Elementary Cloud Platform**](/cloud/introduction)
+
+Elementary Cloud builds on the dbt package by adding a fully managed, AI-powered platform for organization-wide reliability. It includes smart alerting, incident management, column-level lineage, anomaly detection, AI agents, and enterprise features like RBAC and audit logs. It’s designed for teams that want to scale trust, automation, and collaboration across engineering and business.
+
+Use it to:
+
+- Integrate with your entire stack - from DWH to BI, AI tools and ticketing systems
+- Give engineers, analysts, and stakeholders shared visibility into data health
+- Scale reliability efforts across large teams and complex environments
+- Reduce alert fatigue - group and route alerts based on criticality, ownership, and impact
+- Automate test recommendations, metadata coverage, and root cause analysis with AI agents
+- Track progress over time, enforce governance, and support AI readiness
+
+Learn more about Elementary Cloud’s features and integrations [here](https://docs.elementary-data.com/cloud/introduction), and get started with a 30-day free trial [here](https://docs.elementary-data.com/quickstart).
+
+To further understand the differences, check out the full [**OSS vs. Cloud comparison**](/cloud/cloud-vs-oss).
+
+## **Security and Privacy**
+
+Elementary is designed with security and privacy in mind.
+
+- Elementary Cloud does not have read access to raw data in your data warehouse.
+- Elementary Cloud only extracts and stores metadata, logs and aggregated metrics.
+- All data is encrypted at rest and in transit using industry standard protocols.
+- Elementary uses service accounts or authentication tokens with granular and minimal permissions.
+- Elementary offers deployment options with no direct access from Elementary Cloud to your data warehouse and third-party tools.
+- Advanced authentication such as MFA, Okta SSO, Microsoft AD are available upon request.
+
+
+
+Elementary offers a modular observability stack built for dbt-based data workflows. At the foundation is an open-source dbt package that captures key metadata and test results from your dbt project. This package powers both the self-hosted CLI and the fully managed Cloud Platform, which is built on top of it to provide wider visibility, automations, scale and advanced reports.
+
+## Products
+
+Whether you're starting small or scaling observability across your organization, you can choose the setup that fits your team—while unlocking more value as your needs evolve.
+
+### [**Elementary dbt package (OSS)**](/data-tests/dbt/dbt-package)
+
+The Elementary dbt package is open source and runs in your existing dbt workflows. It collects metadata, test results, and lineage from your dbt runs, and also enables Elementary’s anomaly detection tests.
+
+Use it to:
+- Save dbt artifacts, test and run results in your data warehouse
+- Run pre-built anomaly detection and schema changes tests
+
+### [Elementary CLI (OSS)](/oss/oss-introduction)
+
+###
+
+Elementary CLI help teams adopt foundational data observability within dbt. It centralizes metadata and test results to a self-hosted report, and provides a starting point for alerts and monitoring. It’s a great way to introduce reliability into engineering workflows.
+
+Use it to:
+
+- Present test results and metadata from your dbt project in a visual report
+- Send basic alerts over test and schema failures
+
+Setup Elementary OSS [here](https://docs.elementary-data.com/oss/quickstart/quickstart-cli-package).
+
+### [**Elementary Cloud Platform**](/cloud/introduction)
+
+Elementary Cloud builds on the dbt package by adding a fully managed, AI-powered platform for organization-wide reliability. It includes smart alerting, incident management, column-level lineage, anomaly detection, AI agents, and enterprise features like RBAC and audit logs. It’s designed for teams that want to scale trust, automation, and collaboration across engineering and business.
+
+Use it to:
+
+- Integrate with your entire stack - from DWH to BI, AI tools and ticketing systems
+- Give engineers, analysts, and stakeholders shared visibility into data health
+- Scale reliability efforts across large teams and complex environments
+- Reduce alert fatigue - group and route alerts based on criticality, ownership, and impact
+- Automate test recommendations, metadata coverage, and root cause analysis with AI agents
+- Track progress over time, enforce governance, and support AI readiness
+
+Learn more about Elementary Cloud’s features and integrations [here](https://docs.elementary-data.com/cloud/introduction), and get started with a 30-day free trial [here](https://docs.elementary-data.com/quickstart).
+
+To further understand the differences, check out the full [**OSS vs. Cloud comparison**](/cloud/cloud-vs-oss).
+
+## **Security and Privacy**
+
+Elementary is designed with security and privacy in mind.
+
+- Elementary Cloud does not have read access to raw data in your data warehouse.
+- Elementary Cloud only extracts and stores metadata, logs and aggregated metrics.
+- All data is encrypted at rest and in transit using industry standard protocols.
+- Elementary uses service accounts or authentication tokens with granular and minimal permissions.
+- Elementary offers deployment options with no direct access from Elementary Cloud to your data warehouse and third-party tools.
+- Advanced authentication such as MFA, Okta SSO, Microsoft AD are available upon request.
+
+
- tests:
+ data_tests:
-- elementary.all_columns_anomalies:
- timestamp_column: column name
- column_anomalies: column monitors list
- dimensions: sql expression
- exclude_prefix: string
- exclude_regexp: regex
- where_expression: sql expression
- anomaly_sensitivity: int
- anomaly_direction: [both | spike | drop]
- detection_period:
- period: [hour | day | week | month]
- count: int
- training_period:
- period: [hour | day | week | month]
- count: int
- time_bucket:
- period: [hour | day | week | month]
- count: int
- seasonality: day_of_week
- detection_delay:
- period: [hour | day | week | month]
- count: int
- ignore_small_changes:
- spike_failure_percent_threshold: int
- drop_failure_percent_threshold: int
- anomaly_exclude_metrics: [SQL expression]
+ arguments:
+ timestamp_column: column name
+ column_anomalies: column monitors list
+ dimensions: sql expression
+ exclude_prefix: string
+ exclude_regexp: regex
+ where_expression: sql expression
+ anomaly_sensitivity: int
+ anomaly_direction: [both | spike | drop]
+ detection_period:
+ period: [hour | day | week | month]
+ count: int
+ training_period:
+ period: [hour | day | week | month]
+ count: int
+ time_bucket:
+ period: [hour | day | week | month]
+ count: int
+ seasonality: day_of_week
+ detection_delay:
+ period: [hour | day | week | month]
+ count: int
+ ignore_small_changes:
+ spike_failure_percent_threshold: int
+ drop_failure_percent_threshold: int
+ anomaly_exclude_metrics: [SQL expression]
@@ -58,13 +66,14 @@ models:
config:
elementary:
timestamp_column: < timestamp column >
- tests:
+ data_tests:
- elementary.all_columns_anomalies:
- column_anomalies: < specific monitors, all if null >
- where_expression: < sql expression >
- time_bucket: # Daily by default
- period: < time period >
- count: < number of periods >
+ arguments:
+ column_anomalies: < specific monitors, all if null >
+ where_expression: < sql expression >
+ time_bucket: # Daily by default
+ period: < time period >
+ count: < number of periods >
```
```yml Models example
@@ -73,15 +82,18 @@ models:
config:
elementary:
timestamp_column: "loaded_at"
- tests:
+ data_tests:
- elementary.all_columns_anomalies:
- where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
- time_bucket:
- period: day
- count: 1
- tags: ["elementary"]
- # optional - change global sensitivity
- anomaly_sensitivity: 3.5
+ config:
+ tags: ["elementary"]
+ arguments:
+ where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
+ time_bucket:
+ period: day
+ count: 1
+
+ # optional - change global sensitivity
+ anomaly_sensitivity: 3.5
```
- tests:
+ data_tests:
-- elementary.column_anomalies:
- column_anomalies: column monitors list
- dimensions: sql expression
- timestamp_column: column name
- where_expression: sql expression
- anomaly_sensitivity: int
- anomaly_direction: [both | spike | drop]
- detection_period:
- period: [hour | day | week | month]
- count: int
- training_period:
- period: [hour | day | week | month]
- count: int
- time_bucket:
- period: [hour | day | week | month]
- count: int
- seasonality: day_of_week
- detection_delay:
- period: [hour | day | week | month]
- count: int
- ignore_small_changes:
- spike_failure_percent_threshold: int
- drop_failure_percent_threshold: int
- anomaly_exclude_metrics: [SQL expression]
+ arguments:
+ column_anomalies: column monitors list
+ dimensions: sql expression
+ timestamp_column: column name
+ where_expression: sql expression
+ anomaly_sensitivity: int
+ anomaly_direction: [both | spike | drop]
+ detection_period:
+ period: [hour | day | week | month]
+ count: int
+ training_period:
+ period: [hour | day | week | month]
+ count: int
+ time_bucket:
+ period: [hour | day | week | month]
+ count: int
+ seasonality: day_of_week
+ detection_delay:
+ period: [hour | day | week | month]
+ count: int
+ ignore_small_changes:
+ spike_failure_percent_threshold: int
+ drop_failure_percent_threshold: int
+ anomaly_exclude_metrics: [SQL expression]
@@ -57,22 +64,24 @@ models:
timestamp_column: < timestamp column >
columns:
- name: < column name >
- tests:
+ data_tests:
- elementary.column_anomalies:
- column_anomalies: < specific monitors, all if null >
- where_expression: < sql expression >
- time_bucket: # Daily by default
- period: < time period >
- count: < number of periods >
+ arguments:
+ column_anomalies: < specific monitors, all if null >
+ where_expression: < sql expression >
+ time_bucket: # Daily by default
+ period: < time period >
+ count: < number of periods >
- name: < model name >
## if no timestamp is configured, elementary will monitor without time filtering
columns:
- name: < column name >
- tests:
+ data_tests:
- elementary.column_anomalies:
- column_anomalies: < specific monitors, all if null >
- where_expression: < sql expression >
+ arguments:
+ column_anomalies: < specific monitors, all if null >
+ where_expression: < sql expression >
```
```yml Models example
@@ -84,39 +93,46 @@ models:
timestamp_column: 'loaded_at'
columns:
- name: user_name
- tests:
+ data_tests:
- elementary.column_anomalies:
- column_anomalies:
- - missing_count
- - min_length
- where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
- time_bucket:
- period: day
- count: 1
- tags: ['elementary']
+ arguments:
+ column_anomalies:
+ - missing_count
+ - min_length
+ where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
+ time_bucket:
+ period: day
+ count: 1
+ config:
+ tags: ['elementary']
- name: users
## if no timestamp is configured, elementary will monitor without time filtering
- tests:
+ data_tests:
elementary.volume_anomalies
- tags: ['elementary']
+ config:
+ tags: ['elementary']
columns:
- name: user_id
- tests:
+ data_tests:
- elementary.column_anomalies:
- tags: ['elementary']
- timestamp_column: 'updated_at'
- where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
- time_bucket:
- period: < time period >
- count: < number of periods >
+ config:
+ tags: ['elementary']
+ arguments:
+ timestamp_column: 'updated_at'
+ where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
+ time_bucket:
+ period: < time period >
+ count: < number of periods >
- name: user_name
- tests:
+ data_tests:
- elementary.column_anomalies:
- column_anomalies:
- - missing_count
- - min_length
- tags: ['elementary']
+ arguments:
+ column_anomalies:
+ - missing_count
+ - min_length
+ config:
+ tags: ['elementary']
```
diff --git a/docs/data-tests/anomaly-detection-tests/dimension-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/dimension-anomalies.mdx
index b3de4c39c..bc1ab4700 100644
--- a/docs/data-tests/anomaly-detection-tests/dimension-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/dimension-anomalies.mdx
@@ -3,6 +3,12 @@ sidebarTitle: "Dimension anomalies"
title: "dimension_anomalies"
---
+import AiGenerateTest from '/snippets/ai-generate-test.mdx';
+
+
+
- tests:
+ data_tests:
-- elementary.dimension_anomalies:
- dimensions: sql expression
- timestamp_column: column name
- where_expression: sql expression
- anomaly_sensitivity: int
- anomaly_direction: [both | spike | drop]
- detection_period:
- period: [hour | day | week | month]
- count: int
- training_period:
- period: [hour | day | week | month]
- count: int
- time_bucket:
- period: [hour | day | week | month]
- count: int
- seasonality: day_of_week
- detection_delay:
- period: [hour | day | week | month]
- count: int
- ignore_small_changes:
- spike_failure_percent_threshold: int
- drop_failure_percent_threshold: int
- anomaly_exclude_metrics: [SQL expression]
- exclude_final_results: [SQL expression]
+ arguments:
+ dimensions: sql expression
+ timestamp_column: column name
+ where_expression: sql expression
+ anomaly_sensitivity: int
+ anomaly_direction: [both | spike | drop]
+ detection_period:
+ period: [hour | day | week | month]
+ count: int
+ training_period:
+ period: [hour | day | week | month]
+ count: int
+ time_bucket:
+ period: [hour | day | week | month]
+ count: int
+ seasonality: day_of_week
+ detection_delay:
+ period: [hour | day | week | month]
+ count: int
+ ignore_small_changes:
+ spike_failure_percent_threshold: int
+ drop_failure_percent_threshold: int
+ anomaly_exclude_metrics: [SQL expression]
+ exclude_final_results: [SQL expression]
@@ -55,14 +62,15 @@ models:
config:
elementary:
timestamp_column: < timestamp column >
- tests:
+ data_tests:
- elementary.dimension_anomalies:
- dimensions: < columns or sql expressions of columns >
- # optional - configure a where a expression to accurate the dimension monitoring
- where_expression: < sql expression >
- time_bucket: # Daily by default
- period: < time period >
- count: < number of periods >
+ arguments:
+ dimensions: < columns or sql expressions of columns >
+ # optional - configure a where a expression to accurate the dimension monitoring
+ where_expression: < sql expression >
+ time_bucket: # Daily by default
+ period: < time period >
+ count: < number of periods >
```
```yml Models example
@@ -71,28 +79,31 @@ models:
config:
elementary:
timestamp_column: "loaded_at"
- tests:
+ data_tests:
- elementary.dimension_anomalies:
- dimensions:
- - event_type
- - country_name
- where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
- time_bucket:
- period: hour
- count: 4
- # optional - use tags to run elementary tests on a dedicated run
- tags: ["elementary"]
+ arguments:
+ dimensions:
+ - event_type
+ - country_name
+ where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
+ time_bucket:
+ period: hour
+ count: 4
config:
+ # optional - use tags to run elementary tests on a dedicated run
+ tags: ["elementary"]
# optional - change severity
severity: warn
- name: users
# if no timestamp is configured, elementary will monitor without time filtering
- tests:
+ data_tests:
- elementary.dimension_anomalies:
- dimensions:
- - event_type
- tags: ["elementary"]
+ arguments:
+ dimensions:
+ - event_type
+ config:
+ tags: ["elementary"]
```
diff --git a/docs/data-tests/anomaly-detection-tests/event-freshness-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/event-freshness-anomalies.mdx
index 52f026239..675a347c0 100644
--- a/docs/data-tests/anomaly-detection-tests/event-freshness-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/event-freshness-anomalies.mdx
@@ -3,6 +3,11 @@ sidebarTitle: "Event freshness anomalies"
title: "event_freshness_anomalies"
---
+import AiGenerateTest from '/snippets/ai-generate-test.mdx';
+
+
+
- tests:
+ data_tests:
-- elementary.event_freshness_anomalies:
- event_timestamp_column: column name
- update_timestamp_column: column name
- where_expression: sql expression
- anomaly_sensitivity: int
- detection_period:
- period: [hour | day | week | month]
- count: int
- training_period:
- period: [hour | day | week | month]
- count: int
- time_bucket:
- period: [hour | day | week | month]
- count: int
- seasonality: day_of_week
- detection_delay:
- period: [hour | day | week | month]
- count: int
- ignore_small_changes:
- spike_failure_percent_threshold: int
- drop_failure_percent_threshold: int
- anomaly_exclude_metrics: [SQL expression]
+ arguments:
+ event_timestamp_column: column name
+ update_timestamp_column: column name
+ where_expression: sql expression
+ anomaly_sensitivity: int
+ detection_period:
+ period: [hour | day | week | month]
+ count: int
+ training_period:
+ period: [hour | day | week | month]
+ count: int
+ time_bucket:
+ period: [hour | day | week | month]
+ count: int
+ seasonality: day_of_week
+ detection_delay:
+ period: [hour | day | week | month]
+ count: int
+ ignore_small_changes:
+ spike_failure_percent_threshold: int
+ drop_failure_percent_threshold: int
+ anomaly_exclude_metrics: [SQL expression]
@@ -57,26 +63,28 @@ _Default configuration: `anomaly_direction: spike` to alert only on delays._
```yml Models
models:
- name: < model name >
- tests:
+ data_tests:
- elementary.event_freshness_anomalies:
- event_timestamp_column: < timestamp column > # Mandatory
- update_timestamp_column: < timestamp column > # Optional
- where_expression: < sql expression >
- time_bucket: # Daily by default
- period: < time period >
- count: < number of periods >
+ arguments:
+ event_timestamp_column: < timestamp column > # Mandatory
+ update_timestamp_column: < timestamp column > # Optional
+ where_expression: < sql expression >
+ time_bucket: # Daily by default
+ period: < time period >
+ count: < number of periods >
```
```yml Models example
models:
- name: login_events
- tests:
+ data_tests:
- elementary.event_freshness_anomalies:
- event_timestamp_column: "occurred_at"
- update_timestamp_column: "updated_at"
- # optional - use tags to run elementary tests on a dedicated run
- tags: ["elementary"]
+ arguments:
+ event_timestamp_column: "occurred_at"
+ update_timestamp_column: "updated_at"
config:
+ # optional - use tags to run elementary tests on a dedicated run
+ tags: ["elementary"]
# optional - change severity
severity: warn
```
diff --git a/docs/data-tests/anomaly-detection-tests/freshness-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/freshness-anomalies.mdx
index 8215ebfa8..108f0b5ef 100644
--- a/docs/data-tests/anomaly-detection-tests/freshness-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/freshness-anomalies.mdx
@@ -3,12 +3,17 @@ title: "freshness_anomalies"
sidebarTitle: "Freshness anomalies"
---
+import AiGenerateTest from '/snippets/ai-generate-test.mdx';
+
+
+
- tests:
+ data_tests:
-- elementary.freshness_anomalies:
- timestamp_column: column name
- where_expression: sql expression
- anomaly_sensitivity: int
- detection_period:
- period: [hour | day | week | month]
- count: int
- training_period:
- period: [hour | day | week | month]
- count: int
- time_bucket:
- period: [hour | day | week | month]
- count: int
- detection_delay:
- period: [hour | day | week | month]
- count: int
- ignore_small_changes:
- spike_failure_percent_threshold: int
- drop_failure_percent_threshold: int
- anomaly_exclude_metrics: [SQL expression]
+ arguments:
+ timestamp_column: column name
+ where_expression: sql expression
+ anomaly_sensitivity: int
+ detection_period:
+ period: [hour | day | week | month]
+ count: int
+ training_period:
+ period: [hour | day | week | month]
+ count: int
+ time_bucket:
+ period: [hour | day | week | month]
+ count: int
+ detection_delay:
+ period: [hour | day | week | month]
+ count: int
+ ignore_small_changes:
+ spike_failure_percent_threshold: int
+ drop_failure_percent_threshold: int
+ anomaly_exclude_metrics: [SQL expression]
@@ -51,24 +57,26 @@ _Default configuration: `anomaly_direction: spike` to alert only on delays._
```yml Models
models:
- name: < model name >
- tests:
+ data_tests:
- elementary.freshness_anomalies:
- timestamp_column: < timestamp column > # Mandatory
- where_expression: < sql expression >
- time_bucket: # Daily by default
- period: < time period >
- count: < number of periods >
+ arguments:
+ timestamp_column: < timestamp column > # Mandatory
+ where_expression: < sql expression >
+ time_bucket: # Daily by default
+ period: < time period >
+ count: < number of periods >
```
```yml Models example
models:
- name: login_events
- tests:
+ data_tests:
- elementary.freshness_anomalies:
- timestamp_column: "updated_at"
- # optional - use tags to run elementary tests on a dedicated run
- tags: ["elementary"]
+ arguments:
+ timestamp_column: "updated_at"
config:
+ # optional - use tags to run elementary tests on a dedicated run
+ tags: ["elementary"]
# optional - change severity
severity: warn
```
diff --git a/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx
index b564514fc..724d564e4 100644
--- a/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx
@@ -3,6 +3,11 @@ title: "volume_anomalies"
sidebarTitle: "Volume anomalies"
---
+import AiGenerateTest from '/snippets/ai-generate-test.mdx';
+
+
+
- tests:
+ data_tests:
- elementary.volume_anomalies:
- timestamp_column: column name
- where_expression: sql expression
- anomaly_sensitivity: int
- anomaly_direction: [both | spike | drop]
- detection_period:
- period: [hour | day | week | month]
- count: int
- training_period:
- period: [hour | day | week | month]
- count: int
- time_bucket:
- period: [hour | day | week | month]
- count: int
- seasonality: day_of_week
- fail_on_zero: [true | false]
- ignore_small_changes:
- spike_failure_percent_threshold: int
- drop_failure_percent_threshold: int
- detection_delay:
- period: [hour | day | week | month]
- count: int
- anomaly_exclude_metrics: [SQL expression]
+ arguments:
+ timestamp_column: column name
+ where_expression: sql expression
+ anomaly_sensitivity: int
+ anomaly_direction: [both | spike | drop]
+ detection_period:
+ period: [hour | day | week | month]
+ count: int
+ training_period:
+ period: [hour | day | week | month]
+ count: int
+ time_bucket:
+ period: [hour | day | week | month]
+ count: int
+ seasonality: day_of_week
+ fail_on_zero: [true | false]
+ ignore_small_changes:
+ spike_failure_percent_threshold: int
+ drop_failure_percent_threshold: int
+ detection_delay:
+ period: [hour | day | week | month]
+ count: int
+ anomaly_exclude_metrics: [SQL expression]
@@ -55,13 +61,14 @@ No mandatory configuration, however it is highly recommended to configure a `tim
```yml Models
models:
- name: < model name >
- tests:
+ data_tests:
- elementary.volume_anomalies:
- timestamp_column: < timestamp column >
- where_expression: < sql expression >
- time_bucket: # Daily by default
- period: < time period >
- count: < number of periods >
+ arguments:
+ timestamp_column: < timestamp column >
+ where_expression: < sql expression >
+ time_bucket: # Daily by default
+ period: < time period >
+ count: < number of periods >
```
```yml Models example
@@ -70,23 +77,25 @@ models:
config:
elementary:
timestamp_column: "loaded_at"
- tests:
+ data_tests:
- elementary.volume_anomalies:
- where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
- time_bucket:
- period: day
- count: 1
- # optional - use tags to run elementary tests on a dedicated run
- tags: ["elementary"]
+ arguments:
+ where_expression: "event_type in ('event_1', 'event_2') and country_name != 'unwanted country'"
+ time_bucket:
+ period: day
+ count: 1
config:
+ # optional - use tags to run elementary tests on a dedicated run
+ tags: ["elementary"]
# optional - change severity
severity: warn
- name: users
# if no timestamp is configured, elementary will monitor without time filtering
- tests:
+ data_tests:
- elementary.volume_anomalies:
- tags: ["elementary"]
+ config:
+ tags: ["elementary"]
```
diff --git a/docs/data-tests/data-freshness-sla.mdx b/docs/data-tests/data-freshness-sla.mdx
new file mode 100644
index 000000000..41c1c2574
--- /dev/null
+++ b/docs/data-tests/data-freshness-sla.mdx
@@ -0,0 +1,145 @@
+---
+title: "data_freshness_sla"
+sidebarTitle: "Data Freshness SLA"
+---
+
+import AiGenerateTest from '/snippets/ai-generate-test.mdx';
+
+
+
+
+ data_tests:
+ -- elementary.data_freshness_sla:
+ arguments:
+ timestamp_column: column name # Required - timestamp column to check for freshness
+ sla_time: string # Required - e.g., "07:00", "7am", "2:30pm", "14:30"
+ timezone: string # Required - IANA timezone name, e.g., "America/Los_Angeles"
+ day_of_week: string | array # Optional - Day(s) to check: "Monday" or ["Monday", "Wednesday"]
+ day_of_month: int | array # Optional - Day(s) of month to check: 1 or [1, 15]
+ where_expression: sql expression # Optional - filter the data before checking
+
+
+
+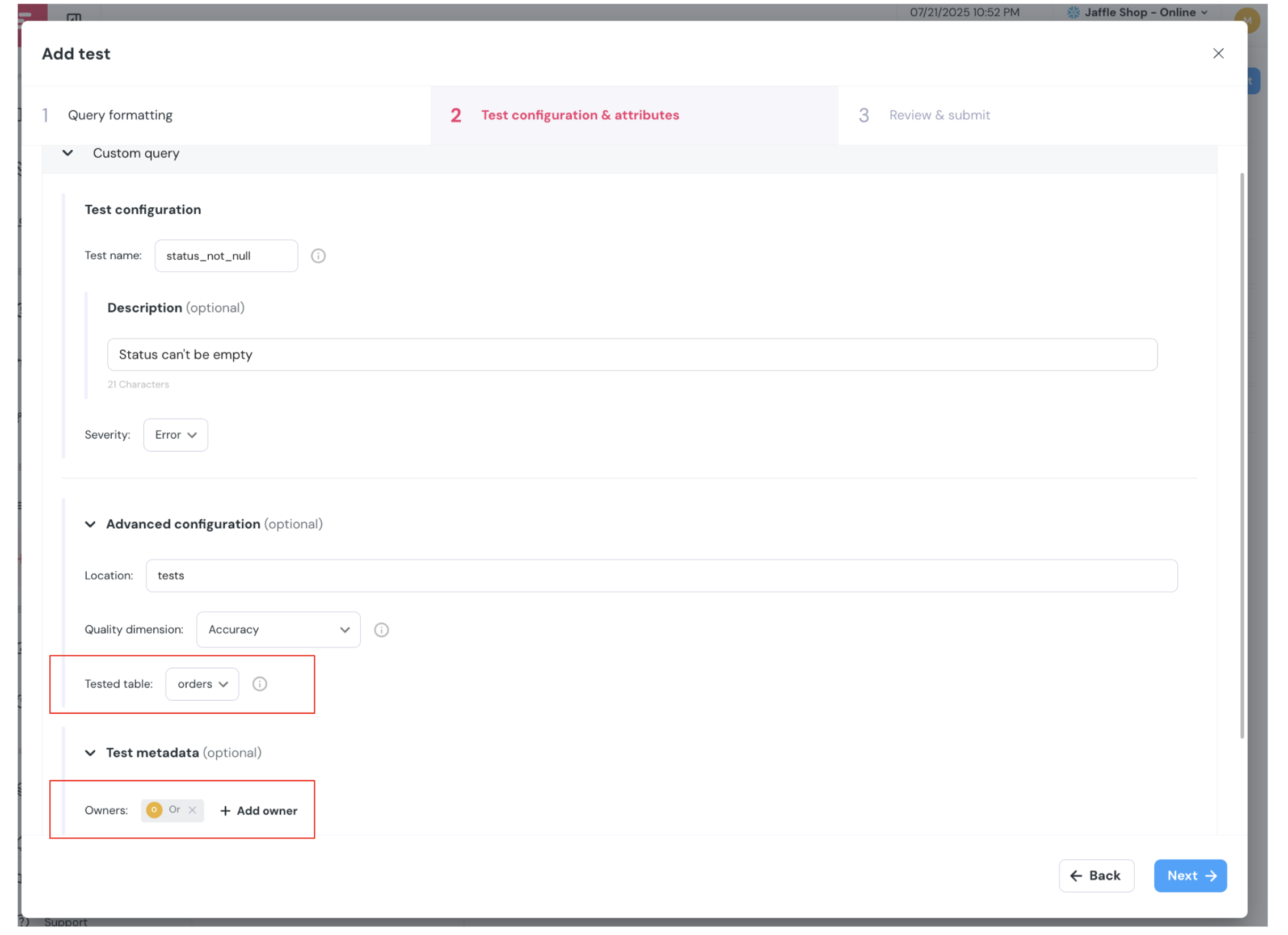 +
+The UI automatically handles the conversion of your test into a proper dbt singular test file, including the `override_primary_test_model_id` configuration when needed.
+
+## Best Practices
+
+- **Use descriptive names** — Name your singular test files clearly to indicate what they're testing (e.g., `assert_orders_have_valid_payments.sql`)
+- **Set the primary model** — Always use `override_primary_test_model_id` when your query involves multiple tables to ensure proper incident attribution
+- **Add descriptions** — Include comments in your SQL explaining the business logic being tested
+- **Configure severity** — Use `severity='error'` for critical tests and `severity='warn'` for non-critical validations
+- **Link to assets** — When possible, configure the primary model to link the test to the most relevant asset for better visibility
+
diff --git a/docs/data-tests/dbt/upgrade-package.mdx b/docs/data-tests/dbt/upgrade-package.mdx
new file mode 100644
index 000000000..df536b379
--- /dev/null
+++ b/docs/data-tests/dbt/upgrade-package.mdx
@@ -0,0 +1,33 @@
+---
+title: "Upgrade Elementary dbt package"
+sidebarTitle: "Upgrade package"
+---
+
+On new releases, you will need to upgrade the Elementary dbt package.
+
+## Upgrade Elementary dbt package
+
+1. On your `packages.yml` file, change the version to the latest:
+
+```yml packages.yml
+packages:
+ - package: elementary-data/elementary
+ version: 0.23.0
+```
+
+2. Run the command:
+
+```shell
+dbt deps
+```
+
+3. When there's a change in the structure of the Elementary tables, the minor version is raised. If you're updating a minor version (for example 0.22.X -> 0.23.X), run this command to rebuild the Elementary tables:
+
+```shell
+dbt run --select elementary
+```
+
+
+
+The UI automatically handles the conversion of your test into a proper dbt singular test file, including the `override_primary_test_model_id` configuration when needed.
+
+## Best Practices
+
+- **Use descriptive names** — Name your singular test files clearly to indicate what they're testing (e.g., `assert_orders_have_valid_payments.sql`)
+- **Set the primary model** — Always use `override_primary_test_model_id` when your query involves multiple tables to ensure proper incident attribution
+- **Add descriptions** — Include comments in your SQL explaining the business logic being tested
+- **Configure severity** — Use `severity='error'` for critical tests and `severity='warn'` for non-critical validations
+- **Link to assets** — When possible, configure the primary model to link the test to the most relevant asset for better visibility
+
diff --git a/docs/data-tests/dbt/upgrade-package.mdx b/docs/data-tests/dbt/upgrade-package.mdx
new file mode 100644
index 000000000..df536b379
--- /dev/null
+++ b/docs/data-tests/dbt/upgrade-package.mdx
@@ -0,0 +1,33 @@
+---
+title: "Upgrade Elementary dbt package"
+sidebarTitle: "Upgrade package"
+---
+
+On new releases, you will need to upgrade the Elementary dbt package.
+
+## Upgrade Elementary dbt package
+
+1. On your `packages.yml` file, change the version to the latest:
+
+```yml packages.yml
+packages:
+ - package: elementary-data/elementary
+ version: 0.23.0
+```
+
+2. Run the command:
+
+```shell
+dbt deps
+```
+
+3. When there's a change in the structure of the Elementary tables, the minor version is raised. If you're updating a minor version (for example 0.22.X -> 0.23.X), run this command to rebuild the Elementary tables:
+
+```shell
+dbt run --select elementary
+```
+
+
+
+ data_tests:
+ -- elementary.execution_sla:
+ arguments:
+ sla_time: string # Required - e.g., "07:00", "7am", "2:30pm", "14:30"
+ timezone: string # Required - IANA timezone name, e.g., "America/Los_Angeles", "Europe/Amsterdam"
+ day_of_week: string | array # Optional - Day(s) to check: "Monday" or ["Monday", "Wednesday"]
+ day_of_month: int | array # Optional - Day(s) of month to check: 1 or [1, 15]
+
+
+
+
+
+ data_tests:
+ -- elementary.volume_threshold:
+ arguments:
+ timestamp_column: column name # Required
+ warn_threshold_percent: int # Optional - default: 5
+ error_threshold_percent: int # Optional - default: 10
+ direction: [both | spike | drop] # Optional - default: both
+ time_bucket: # Optional
+ period: [hour | day | week | month]
+ count: int
+ where_expression: sql expression # Optional
+ days_back: int # Optional - default: 14
+ backfill_days: int # Optional - default: 2
+ min_row_count: int # Optional - default: 100
+
+
+
+
+ The Data & AI
+ Control Plane
+
+
+ Elementary is built for and trusted by
+ 1000+ engineering and analytics teams.
+
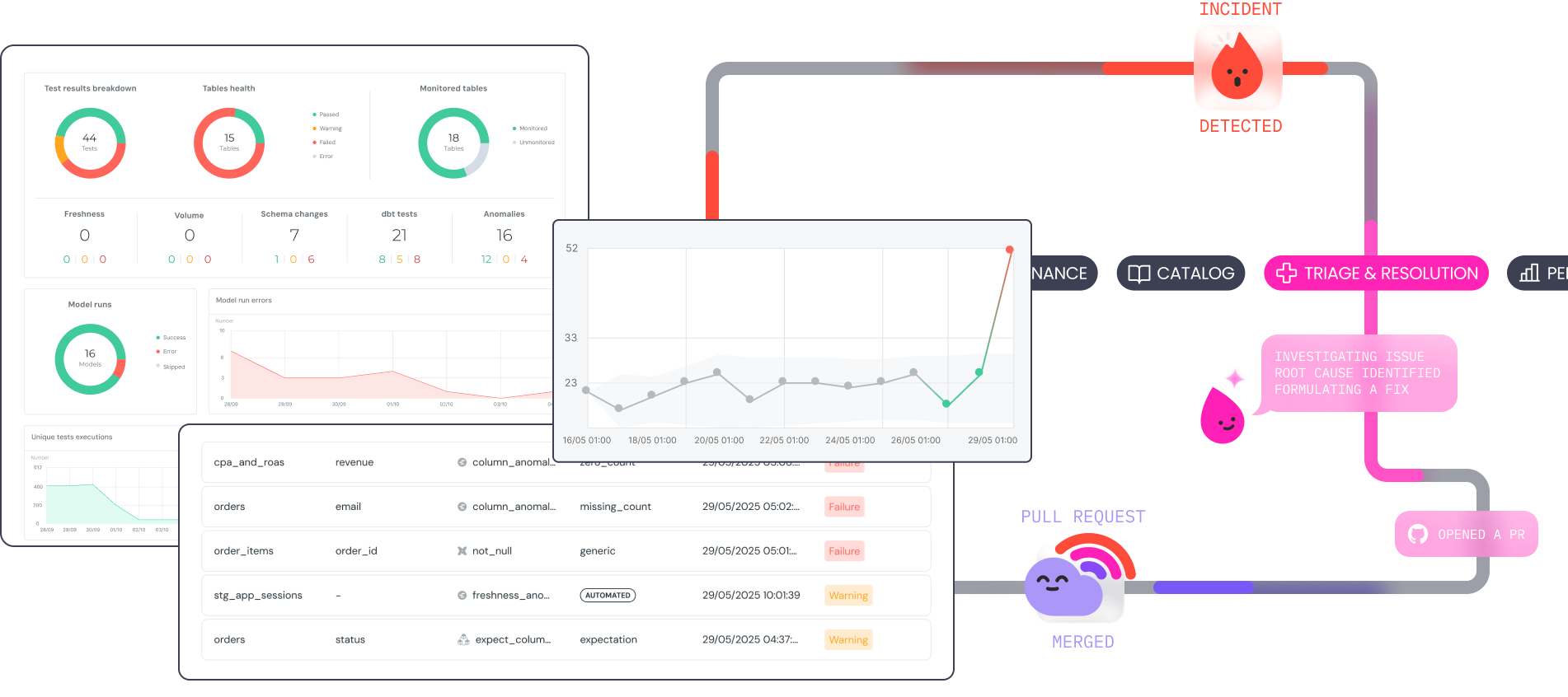 +
+ SOC 2 & HIPAA Compliant
+Enterprise-grade security standards
+Metadata-only Architecture
+We never access or process your raw data
+
+ Discover what you can do
+ with Elementary
+
+ Learn more about Elementary
+Elementary context
in your tools
+ The MCP Server brings models, lineage, and incidents into tools like Cursor and Claude—so you can act without leaving your workflow.
+ +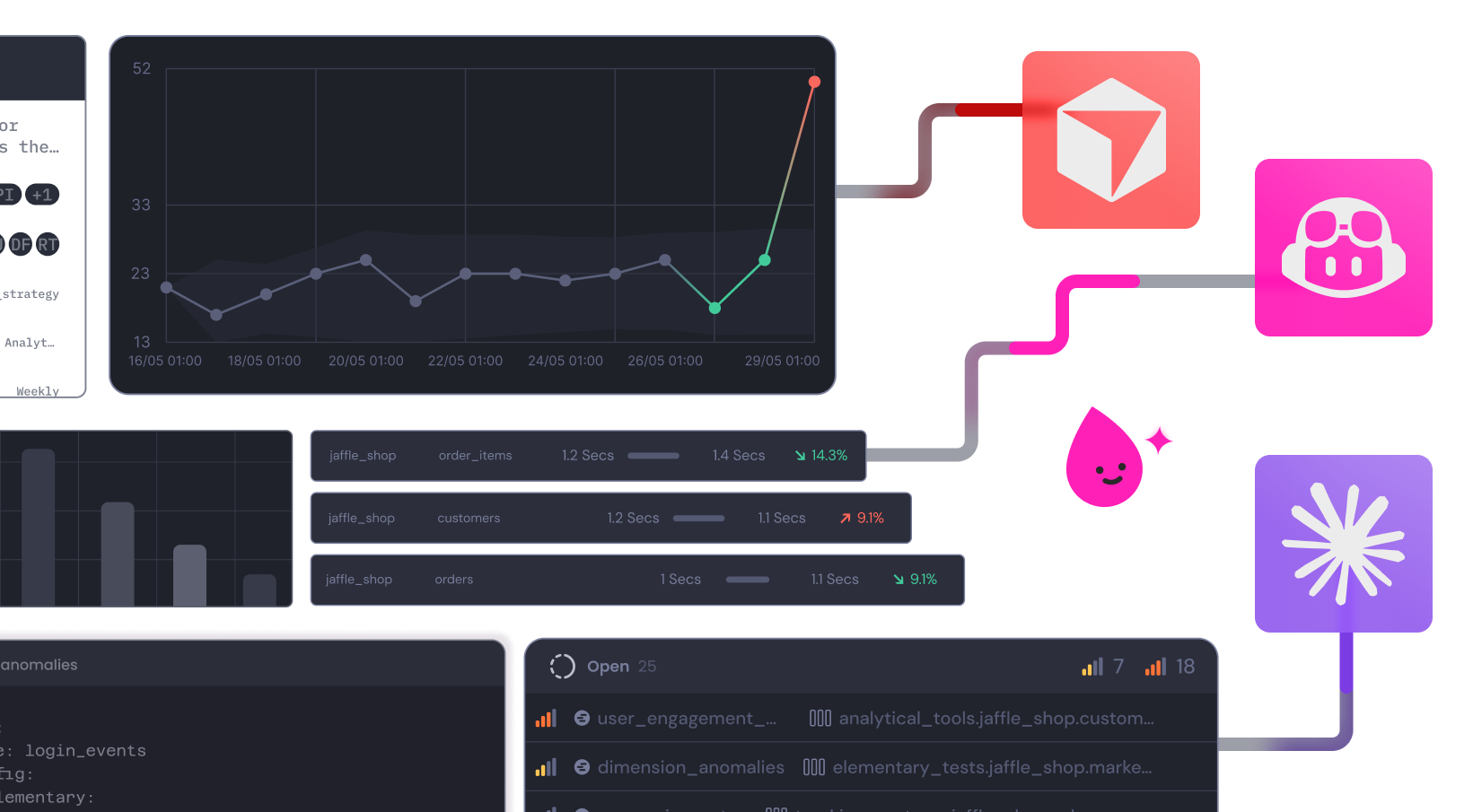 +
+ Integrations
++ Connect Elementary to every part of your data stack—from your warehouse to BI, + incident management and messaging tools. +
+ Check out the integrationsOSS integrations
+Cloud integrations
+Get started now
++ Whether you need a lightweight start or an enterprise-ready platform, Elementary has a solution for you. +
+Featured guides
++ Learn from the Elementary team and thousands of users from our community how to set up + effective, scalable data observability. +
+Join the community
++ Join the Elementary Community for AI and team support, explore best practices, and stay up to + date on OSS and Cloud. Connect with other data professionals and help shape what's next. +
+{heading}
+{description}
+{children}
+Leave your email in case a follow up is needed:'; + popover.appendChild(message); + + var form = document.createElement('form'); + form.style.margin = '0'; + + var input = document.createElement('input'); + input.type = 'email'; + input.placeholder = 'you@company.com'; + input.style.cssText = + 'width:100%;box-sizing:border-box;padding:12px 14px;font-size:14px;color:#111;background:#fff;background-color:#fff;border-radius:8px;border:1px solid #e5e7eb;margin-bottom:12px;outline:none;'; + form.appendChild(input); + + var errEl = document.createElement('p'); + errEl.id = 'elementary-kapa-error'; + errEl.style.cssText = 'font-size:12px;color:#dc2626;margin:8px 0 0;display:none;'; + form.appendChild(errEl); + + var submitBtn = document.createElement('button'); + submitBtn.type = 'submit'; + submitBtn.textContent = 'Start chat'; + submitBtn.style.cssText = + 'width:100%;padding:12px 16px;font-size:14px;font-weight:600;color:#fff;background:' + + PRIMARY + + ';border:none;border-radius:8px;cursor:pointer;'; + form.appendChild(submitBtn); + + popover.appendChild(form); + + function hidePopover() { + popover.style.display = 'none'; + } + + function showPopover() { + popover.style.display = 'block'; + input.value = ''; + errEl.style.display = 'none'; + errEl.textContent = ''; + setTimeout(function () { + input.focus(); + }, 50); + } + + form.onsubmit = function (e) { + e.preventDefault(); + var emailVal = (input.value || '').trim(); + if (!emailVal) { + errEl.textContent = 'Please enter your email.'; + errEl.style.display = 'block'; + return; + } + var re = /^[^\s@]+@[^\s@]+\.[^\s@]+$/; + if (!re.test(emailVal)) { + errEl.textContent = 'Please enter a valid email address.'; + errEl.style.display = 'block'; + return; + } + if (isBlockedConsumerEmailDomain(emailVal)) { + errEl.textContent = FREE_EMAIL_NOT_ACCEPTED_MSG; + errEl.style.display = 'block'; + return; + } + errEl.style.display = 'none'; + errEl.textContent = ''; + submitBtn.disabled = true; + submitBtn.textContent = 'Submitting…'; + submitToHubSpot(emailVal).then(function (result) { + submitBtn.disabled = false; + submitBtn.textContent = 'Start chat'; + if (!result.ok) { + errEl.textContent = result.message || 'Please try a different email.'; + errEl.style.display = 'block'; + return; + } + storeEmail(emailVal); + openKapa(emailVal); + hidePopover(); + }); + }; + + button.onclick = function () { + var stored = getStoredEmail(); + if (stored && stored.trim()) { + var s = stored.trim(); + var reStored = /^[^\s@]+@[^\s@]+\.[^\s@]+$/; + if (!reStored.test(s)) { + try { + localStorage.removeItem(STORAGE_KEY); + } catch (removeErr) {} + showPopover(); + return; + } + if (isBlockedConsumerEmailDomain(s)) { + try { + localStorage.removeItem(STORAGE_KEY); + } catch (removeErr2) {} + showPopover(); + return; + } + openKapa(s); + return; + } + if (popover.style.display === 'block') { + hidePopover(); + } else { + showPopover(); + } + }; + + document.addEventListener('mousedown', function (e) { + if ( + popover.style.display !== 'block' || + popover.contains(e.target) || + button.contains(e.target) + ) { + return; + } + hidePopover(); + }); + + root.appendChild(popover); + root.appendChild(button); + } + + function loadKapaScript() { + var script = document.createElement('script'); + script.src = 'https://widget.kapa.ai/kapa-widget.bundle.js'; + script.async = true; + script.setAttribute('data-website-id', 'e558d15b-d976-4a89-b2f0-e33ee6dab58b'); + script.setAttribute('data-project-name', 'Ask Elementary AI'); + script.setAttribute('data-modal-title', 'Ask Elementary AI'); + script.setAttribute('data-modal-title-ask-ai', 'Ask Elementary AI'); + script.setAttribute('data-modal-title-search', 'Ask Elementary AI'); + script.setAttribute('data-modal-ask-ai-input-placeholder', 'Ask any question about Elementary...'); + script.setAttribute('data-project-color', '#FF20B8'); + script.setAttribute('data-project-logo', 'https://res.cloudinary.com/do5hrgokq/image/upload/v1771424391/Elementary_2025_Pink_Mark_Black_Frame_rbexli.png'); + script.setAttribute('data-button-hide', 'true'); + document.head.appendChild(script); + } + + function init() { + loadKapaScript(); + if (document.readyState === 'loading') { + document.addEventListener('DOMContentLoaded', injectButtonAndPopover); + } else { + injectButtonAndPopover(); + } + } + + init(); +})(); diff --git a/docs/key-features.mdx b/docs/key-features.mdx index 75068c125..a16ec539b 100644 --- a/docs/key-features.mdx +++ b/docs/key-features.mdx @@ -9,7 +9,7 @@ icon: "stars" title="Data anomaly detection" icon="monitor-waveform" iconType="solid" - href="/features/data-tests" + href="cloud/features/data-tests" > Monitor data quality metrics, freshness, volume and schema changes. @@ -17,7 +17,7 @@ icon: "stars" title="dbt artifacts and run results" icon="table-tree" iconType="regular" - href="/dbt/dbt-artifacts" + href="/data-tests/dbt/dbt-artifacts" > Upload metadata, run and test results to tables as part of your jobs. @@ -25,7 +25,7 @@ icon: "stars" title="Alerts" icon="bell-exclamation" iconType="regular" - href="/features/elementary-alerts" + href="cloud/features/elementary-alerts" > Send informative alerts to different channels and users. @@ -33,7 +33,7 @@ icon: "stars" title="Data observability dashboard" icon="browsers" iconType="solid" - href="/features/data-observability-dashboard" + href="cloud/features/collaboration-and-communication/data-observability-dashboard" > Inspect your data health overview, test results, models performance and data lineage. @@ -42,14 +42,14 @@ icon: "stars" title="End-to-end data lineage" icon="arrow-progress" iconType="solid" - href="/features/lineage" + href="cloud/features/data-lineage/lineage" > Inspect dependencies including Column Level Lineage and integration with BI tools.
-
+ + +
+
+
+### Supported adapters
+
++
 +
+ +
 +
+
+
+
+## Generate Tests Report UI
+
+### Execute `edr report` in your terminal
+
+After installing and configuring the CLI, execute the command:
+
+```shell
+edr report
+```
+
+The command will use the provided connection profile to access the data warehouse, read from the Elementary tables, and generate the report as an HTML file.
+
+---
+
+## Generating a report for single invocation
+
+Elementary support filtering the report by invocation on generation.
+The filtered report will only include data for the selected invocation (This applies only on the `Test Results` and `Lineage` screens).
+
+There are 3 ways to filter the report by invocation:
+
+- **Last invocation** - Filter by the last invocation (`dbt test` / `dbt build`) that ran.
+- **Invocation time** - Filter by the closest invocation (`dbt test` / `dbt build`) to the provided time (the provided time should be in ISO format local time).
+- **Invocation id** - Filter by the provided invocation (`dbt test` / `dbt build`) id.
+
+Filters usage example:
+
+```shell edr report invocation filters
+edr report --select last_invocation
+edr report --select "invocation_time:2022-12-25 10:10:35"
+edr report --select invocation_id:XXXXXXXXXXXXX
+```
+
+---
+
+
+
+
+
+
+## Generate Tests Report UI
+
+### Execute `edr report` in your terminal
+
+After installing and configuring the CLI, execute the command:
+
+```shell
+edr report
+```
+
+The command will use the provided connection profile to access the data warehouse, read from the Elementary tables, and generate the report as an HTML file.
+
+---
+
+## Generating a report for single invocation
+
+Elementary support filtering the report by invocation on generation.
+The filtered report will only include data for the selected invocation (This applies only on the `Test Results` and `Lineage` screens).
+
+There are 3 ways to filter the report by invocation:
+
+- **Last invocation** - Filter by the last invocation (`dbt test` / `dbt build`) that ran.
+- **Invocation time** - Filter by the closest invocation (`dbt test` / `dbt build`) to the provided time (the provided time should be in ISO format local time).
+- **Invocation id** - Filter by the provided invocation (`dbt test` / `dbt build`) id.
+
+Filters usage example:
+
+```shell edr report invocation filters
+edr report --select last_invocation
+edr report --select "invocation_time:2022-12-25 10:10:35"
+edr report --select invocation_id:XXXXXXXXXXXXX
+```
+
+---
+
+ +
diff --git a/docs/snippets/alerts/description.mdx b/docs/snippets/alerts/description.mdx
new file mode 100644
index 000000000..76e249ffe
--- /dev/null
+++ b/docs/snippets/alerts/description.mdx
@@ -0,0 +1,31 @@
+Elementary supports configuring description for tests that are included in alerts.
+It's recommended to add an explanation of what does it mean if this test fails, so alert will include this context.
+
+
+
diff --git a/docs/snippets/alerts/description.mdx b/docs/snippets/alerts/description.mdx
new file mode 100644
index 000000000..76e249ffe
--- /dev/null
+++ b/docs/snippets/alerts/description.mdx
@@ -0,0 +1,31 @@
+Elementary supports configuring description for tests that are included in alerts.
+It's recommended to add an explanation of what does it mean if this test fails, so alert will include this context.
+
+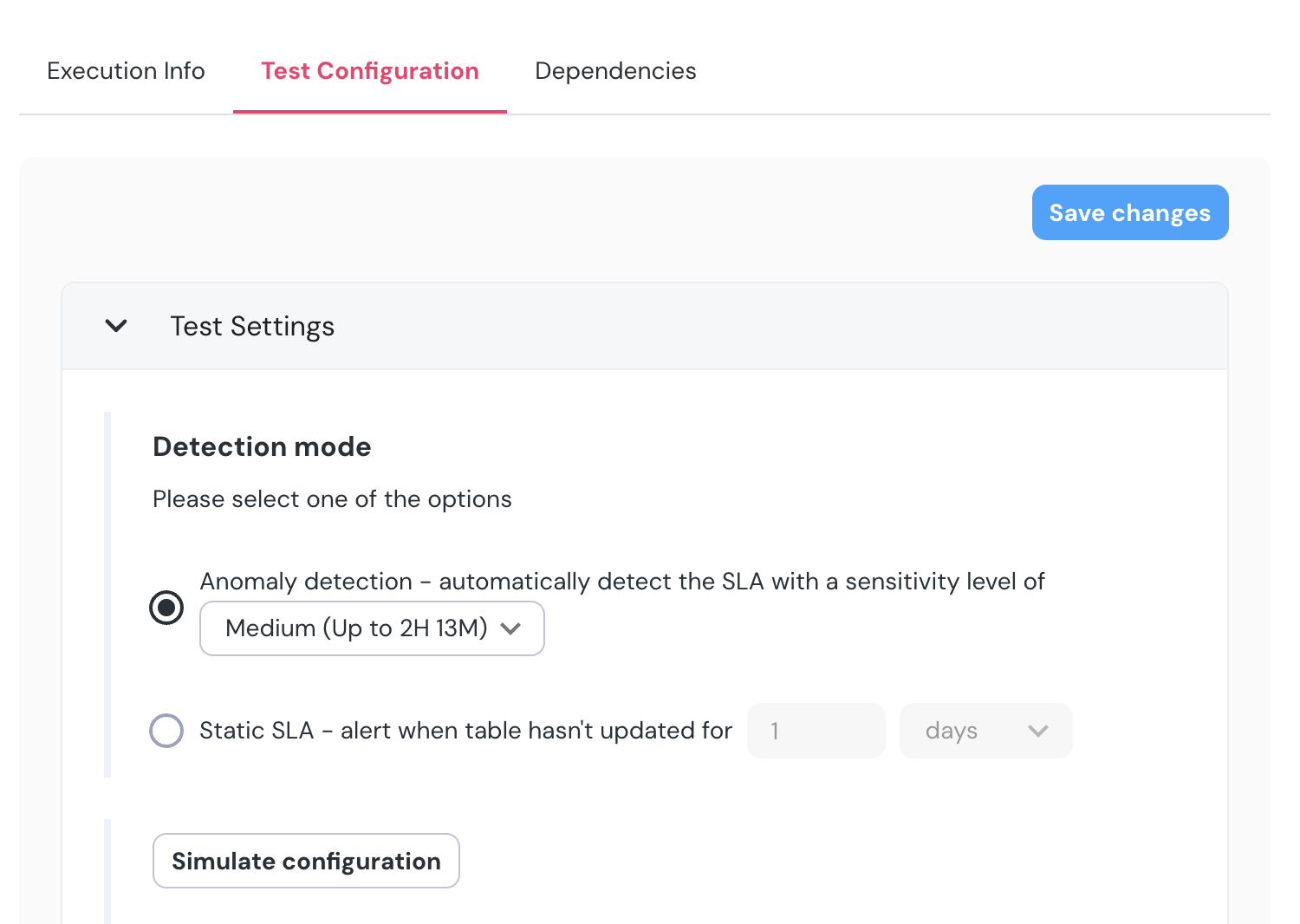 \ No newline at end of file
diff --git a/docs/snippets/cloud/features/anomaly-detection/volume-configuration.mdx b/docs/snippets/cloud/features/anomaly-detection/volume-configuration.mdx
new file mode 100644
index 000000000..13729e492
--- /dev/null
+++ b/docs/snippets/cloud/features/anomaly-detection/volume-configuration.mdx
@@ -0,0 +1,3 @@
+- **Anomaly Direction** - Whether you want the monitor to fail on anomalous drops, spikes, or both. Default is both.
+- **Sensitivity** - You can set the monitor's sensitivity levels to *Low*, *Medium*, or *High*. In the future, we plan to allow for more nuanced adjustments to this parameter. You can use the `Simulate Configuration` button for testing how the change will affect the monitor.
+- **Detection Period** - The period in which the monitor look for anomalies. Default is the last 2 days.
\ No newline at end of file
diff --git a/docs/snippets/cloud/features/data-health/data-health-intro.mdx b/docs/snippets/cloud/features/data-health/data-health-intro.mdx
new file mode 100644
index 000000000..4e4bdb24f
--- /dev/null
+++ b/docs/snippets/cloud/features/data-health/data-health-intro.mdx
@@ -0,0 +1,11 @@
+Once you start sharing data with downstream consumers and stakeholders one of the most important things that you want to create is trust.
+Trust that the data that is being used is “healthy”. Imagine being a data analyst using a specific data asset but you constantly run into data quality issues.
+You will eventually lose trust.
+
+This is why we created **data health scores** in Elementary. It is a way to share an overview of the health of your data assets.
+
+To measure health we use an industry standard framework of [Data Quality Dimensions](/cloud/features/collaboration-and-communication/data-quality-dimensions#data-quality-dimensions).
+These dimensions help assess the reliability of data in various business contexts.
+Ensuring high-quality data across these dimensions is critical for accurate analysis, informed decision-making, and operational efficiency.
+
+
\ No newline at end of file
diff --git a/docs/snippets/cloud/features/anomaly-detection/volume-configuration.mdx b/docs/snippets/cloud/features/anomaly-detection/volume-configuration.mdx
new file mode 100644
index 000000000..13729e492
--- /dev/null
+++ b/docs/snippets/cloud/features/anomaly-detection/volume-configuration.mdx
@@ -0,0 +1,3 @@
+- **Anomaly Direction** - Whether you want the monitor to fail on anomalous drops, spikes, or both. Default is both.
+- **Sensitivity** - You can set the monitor's sensitivity levels to *Low*, *Medium*, or *High*. In the future, we plan to allow for more nuanced adjustments to this parameter. You can use the `Simulate Configuration` button for testing how the change will affect the monitor.
+- **Detection Period** - The period in which the monitor look for anomalies. Default is the last 2 days.
\ No newline at end of file
diff --git a/docs/snippets/cloud/features/data-health/data-health-intro.mdx b/docs/snippets/cloud/features/data-health/data-health-intro.mdx
new file mode 100644
index 000000000..4e4bdb24f
--- /dev/null
+++ b/docs/snippets/cloud/features/data-health/data-health-intro.mdx
@@ -0,0 +1,11 @@
+Once you start sharing data with downstream consumers and stakeholders one of the most important things that you want to create is trust.
+Trust that the data that is being used is “healthy”. Imagine being a data analyst using a specific data asset but you constantly run into data quality issues.
+You will eventually lose trust.
+
+This is why we created **data health scores** in Elementary. It is a way to share an overview of the health of your data assets.
+
+To measure health we use an industry standard framework of [Data Quality Dimensions](/cloud/features/collaboration-and-communication/data-quality-dimensions#data-quality-dimensions).
+These dimensions help assess the reliability of data in various business contexts.
+Ensuring high-quality data across these dimensions is critical for accurate analysis, informed decision-making, and operational efficiency.
+
+ +
+- **Client ID**: The Application (client) ID of the service principal (the "Application ID" you copied in [step 5](#create-service-principal)).
+- **Client secret**: The OAuth secret you generated for the service principal (see [step 7](#create-service-principal)).
+
+
+
+- **Client ID**: The Application (client) ID of the service principal (the "Application ID" you copied in [step 5](#create-service-principal)).
+- **Client secret**: The OAuth secret you generated for the service principal (see [step 7](#create-service-principal)).
+
+ +
+This is the recommended approach, as it provides better security and follows AWS best practices.
+After choosing **Direct storage access**, select **AWS role ARN** under **Select S3 authentication method**.
+
+1. Create an IAM role that Elementary can assume.
+2. Select "Another AWS account" as the trusted entity.
+3. Enter Elementary's AWS account ID: `743289191656`.
+4. Optionally enable an external ID.
+5. Attach a policy that grants read access to the Delta log files.
+
+Use a policy similar to the following:
+
+```json
+{
+ "Version": "2012-10-17",
+ "Statement": [
+ {
+ "Sid": "VisualEditor0",
+ "Effect": "Allow",
+ "Action": [
+ "s3:GetObject",
+ "s3:ListBucket"
+ ],
+ "Resource": [
+ "arn:aws:s3:::databricks-metastore-bucket",
+ "arn:aws:s3:::databricks-metastore-bucket/*_delta_log*"
+ ]
+ }
+ ]
+}
+```
+
+This policy is scoped to the bucket itself and objects matching `*_delta_log*`, so it does not grant access to other objects in the bucket.
+
+Provide the role ARN in the Elementary UI, and the external ID as well if you configured one.
+
+__AWS access keys__
+
+
+
+This is the recommended approach, as it provides better security and follows AWS best practices.
+After choosing **Direct storage access**, select **AWS role ARN** under **Select S3 authentication method**.
+
+1. Create an IAM role that Elementary can assume.
+2. Select "Another AWS account" as the trusted entity.
+3. Enter Elementary's AWS account ID: `743289191656`.
+4. Optionally enable an external ID.
+5. Attach a policy that grants read access to the Delta log files.
+
+Use a policy similar to the following:
+
+```json
+{
+ "Version": "2012-10-17",
+ "Statement": [
+ {
+ "Sid": "VisualEditor0",
+ "Effect": "Allow",
+ "Action": [
+ "s3:GetObject",
+ "s3:ListBucket"
+ ],
+ "Resource": [
+ "arn:aws:s3:::databricks-metastore-bucket",
+ "arn:aws:s3:::databricks-metastore-bucket/*_delta_log*"
+ ]
+ }
+ ]
+}
+```
+
+This policy is scoped to the bucket itself and objects matching `*_delta_log*`, so it does not grant access to other objects in the bucket.
+
+Provide the role ARN in the Elementary UI, and the external ID as well if you configured one.
+
+__AWS access keys__
+
+ +
+If needed, you can instead provide direct AWS credentials.
+After choosing **Direct storage access**, select **Secret access key** under **Select S3 authentication method**.
+
+1. Create an IAM user that Elementary will use for storage access.
+2. Enable programmatic access.
+3. Attach the same read-only S3 policy shown above.
+4. Provide the AWS access key ID and secret access key in the Elementary UI.
+
+#### Access token (legacy)
+
+
+
+If needed, you can instead provide direct AWS credentials.
+After choosing **Direct storage access**, select **Secret access key** under **Select S3 authentication method**.
+
+1. Create an IAM user that Elementary will use for storage access.
+2. Enable programmatic access.
+3. Attach the same read-only S3 policy shown above.
+4. Provide the AWS access key ID and secret access key in the Elementary UI.
+
+#### Access token (legacy)
+
+ +
+- **Access token**: A personal access token generated for the Elementary service principal.
+
+
+
+- **Access token**: A personal access token generated for the Elementary service principal.
+
+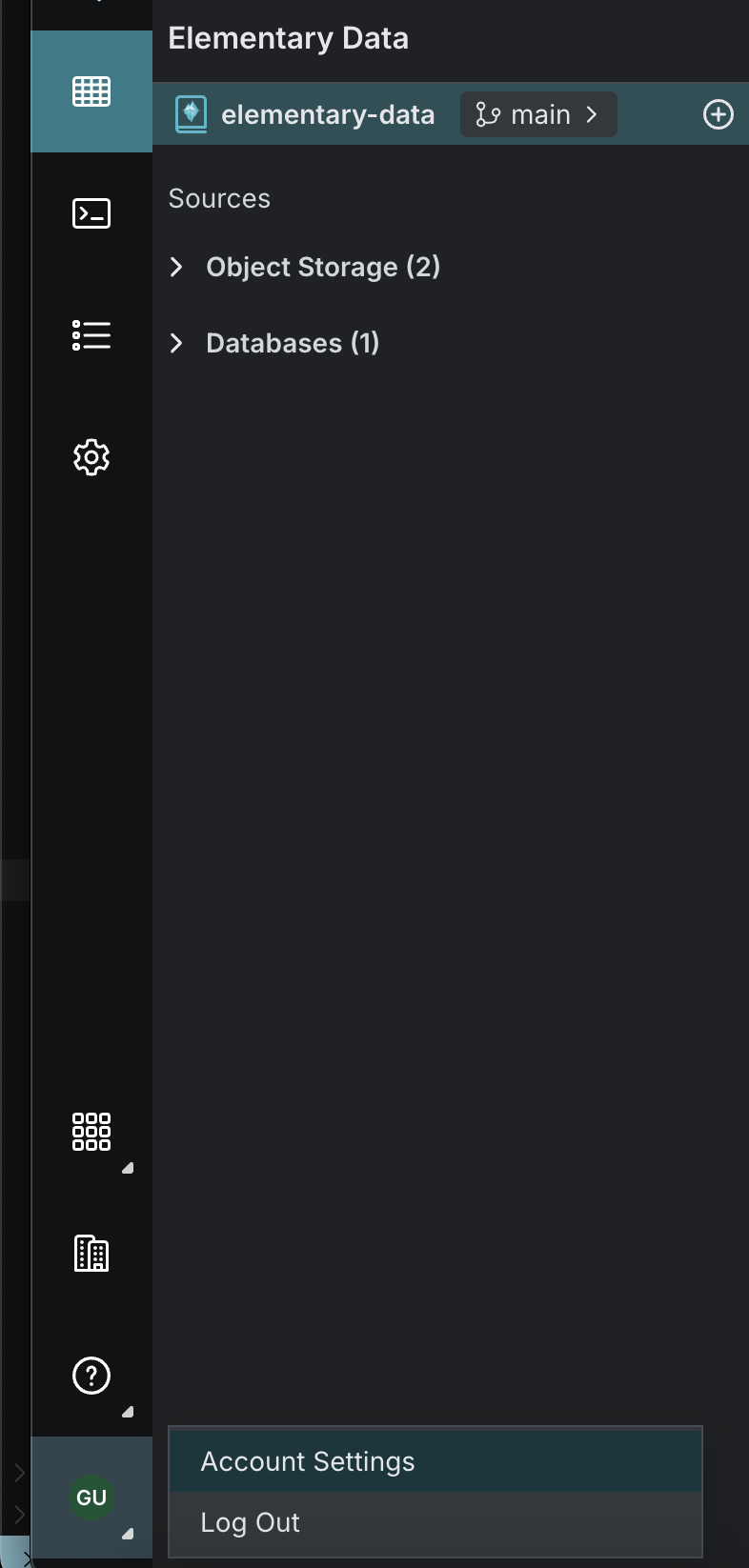 +
+Click **Generate Token**:
+
+
+
+
+
+
+Click **Generate Token**:
+
+
+
+
+ 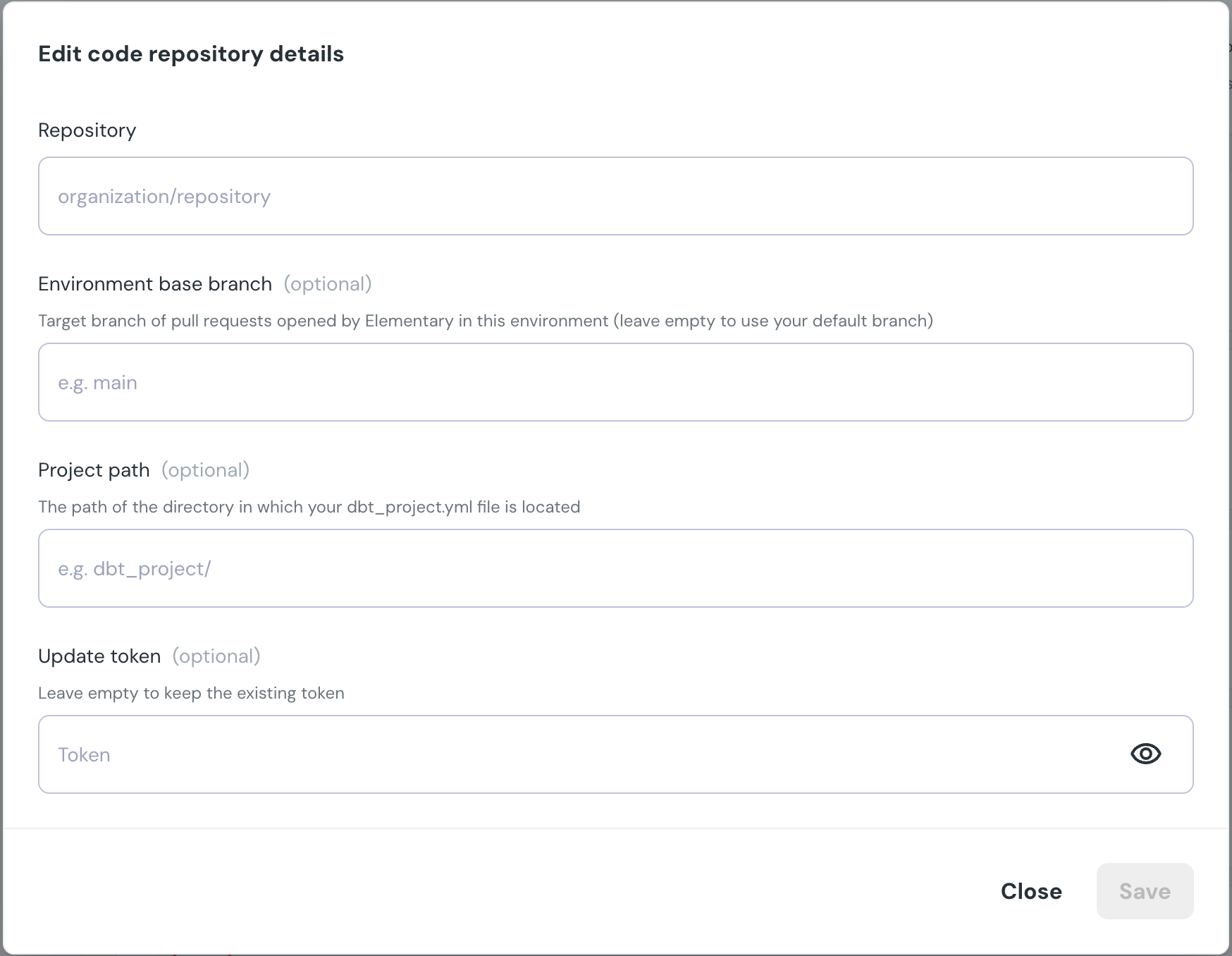 +
\ No newline at end of file
diff --git a/docs/_snippets/cloud/integrations/snowflake.mdx b/docs/snippets/cloud/integrations/snowflake.mdx
similarity index 63%
rename from docs/_snippets/cloud/integrations/snowflake.mdx
rename to docs/snippets/cloud/integrations/snowflake.mdx
index 6a2ba656b..e1cdb930a 100644
--- a/docs/_snippets/cloud/integrations/snowflake.mdx
+++ b/docs/snippets/cloud/integrations/snowflake.mdx
@@ -1,6 +1,8 @@
-You will connect Elementary Cloud to Snowflake for syncing the Elementary schema (created by the [Elementary dbt package](/cloud/onboarding/quickstart-dbt-package)).
+import CreateUserOperationSnowflake from '/snippets/cloud/integrations/create-user-operation-snowflake.mdx';
-
+
\ No newline at end of file
diff --git a/docs/_snippets/cloud/integrations/snowflake.mdx b/docs/snippets/cloud/integrations/snowflake.mdx
similarity index 63%
rename from docs/_snippets/cloud/integrations/snowflake.mdx
rename to docs/snippets/cloud/integrations/snowflake.mdx
index 6a2ba656b..e1cdb930a 100644
--- a/docs/_snippets/cloud/integrations/snowflake.mdx
+++ b/docs/snippets/cloud/integrations/snowflake.mdx
@@ -1,6 +1,8 @@
-You will connect Elementary Cloud to Snowflake for syncing the Elementary schema (created by the [Elementary dbt package](/cloud/onboarding/quickstart-dbt-package)).
+import CreateUserOperationSnowflake from '/snippets/cloud/integrations/create-user-operation-snowflake.mdx';
- +
+3. On the sidebar, click on *Identity and access*, and then under the *Service Principals* row click on *Manage*.
+
+
+
+3. On the sidebar, click on *Identity and access*, and then under the *Service Principals* row click on *Manage*.
+
+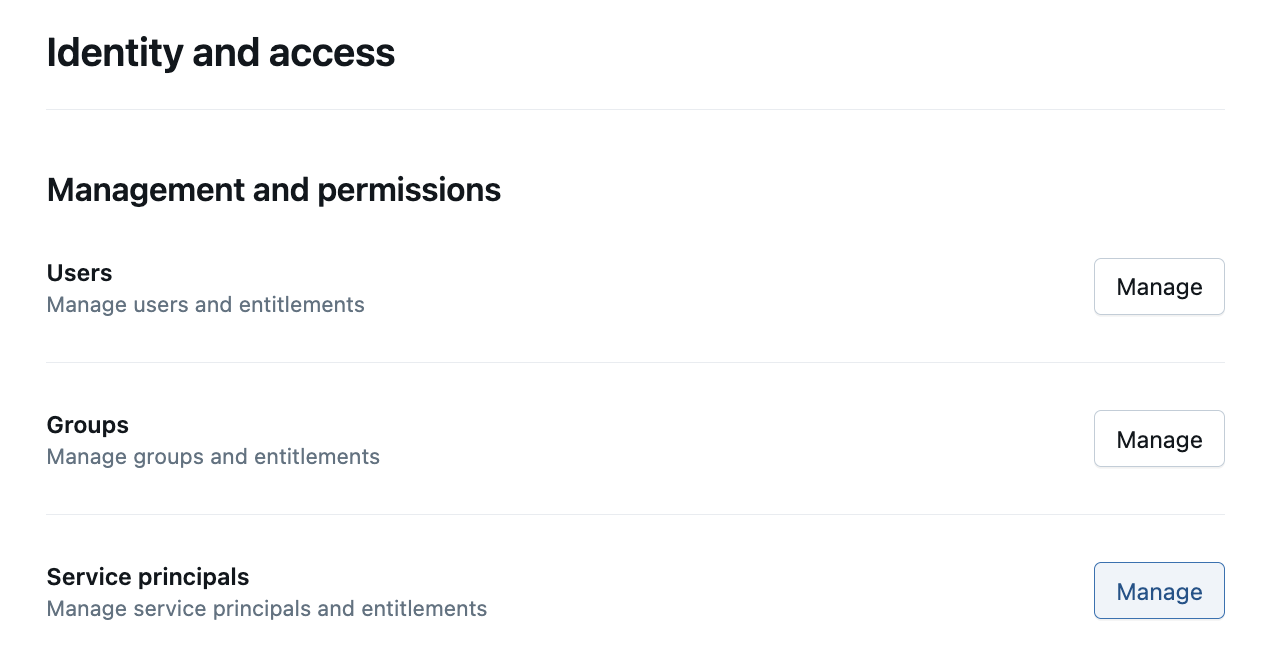 +
+4. Click on the *Add service principal* button, choose "Add new" and give a name to the service principal. This will be used by Elementary Cloud
+to access your Databricks instance.
+
+
+
+4. Click on the *Add service principal* button, choose "Add new" and give a name to the service principal. This will be used by Elementary Cloud
+to access your Databricks instance.
+
+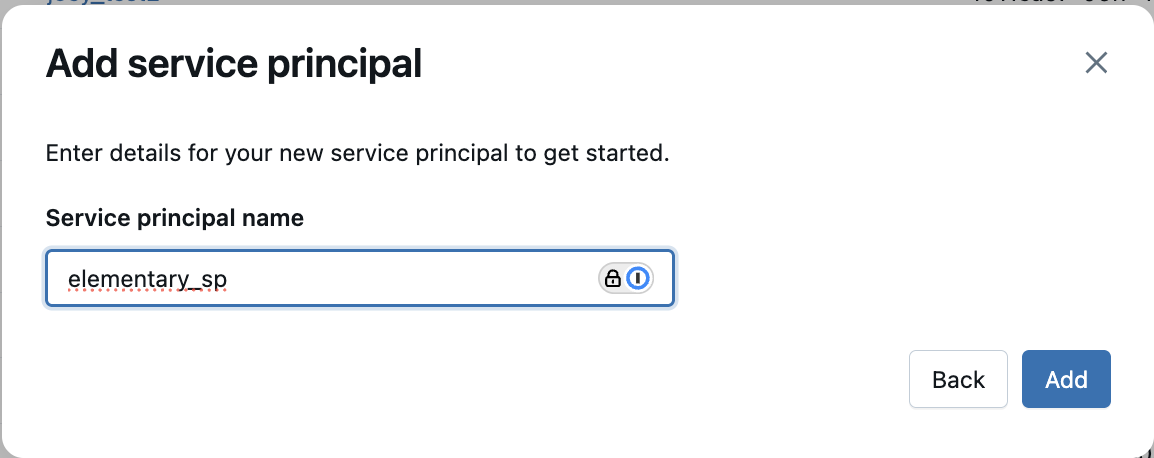 +
+5. Click on your newly created service principal, add the "Databricks SQL access" entitlement, and click Update. Also, please copy the
+"Application ID" field as it will be used later in the permissions section.
+
+
+
+5. Click on your newly created service principal, add the "Databricks SQL access" entitlement, and click Update. Also, please copy the
+"Application ID" field as it will be used later in the permissions section.
+
+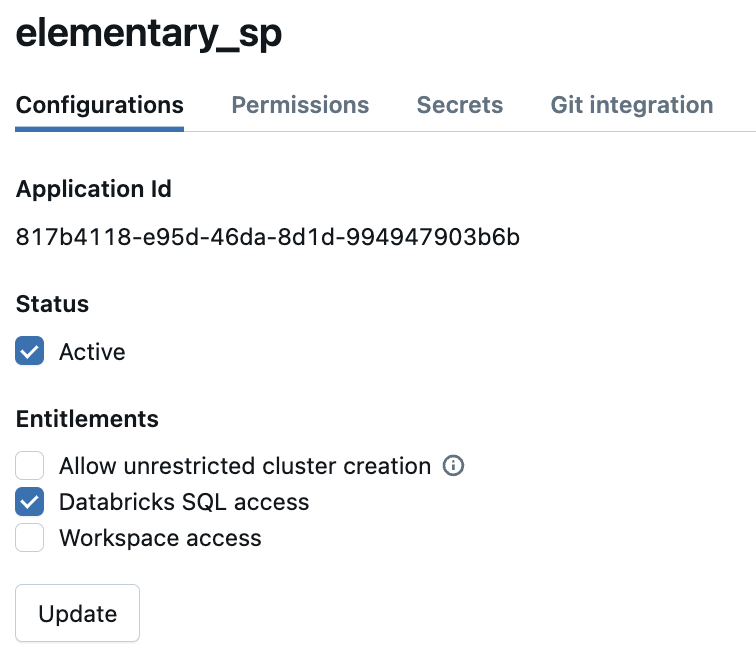 +
+6. Next, generate credentials for your service principal. Choose one of the following methods:
+
+ **Option A: Generate an OAuth secret (Recommended)**
+
+ On the service principal page, go to the *Secrets* tab and click *Generate secret*. Copy the **Client ID** (this is the same as the "Application ID" from step 5) and the generated **Client secret** — you will need both when configuring the Elementary environment.
+
+ {/* TODO: Add screenshot of Databricks service principal Secrets tab with "Generate secret" button */}
+
+
+6. Next, generate credentials for your service principal. Choose one of the following methods:
+
+ **Option A: Generate an OAuth secret (Recommended)**
+
+ On the service principal page, go to the *Secrets* tab and click *Generate secret*. Copy the **Client ID** (this is the same as the "Application ID" from step 5) and the generated **Client secret** — you will need both when configuring the Elementary environment.
+
+ {/* TODO: Add screenshot of Databricks service principal Secrets tab with "Generate secret" button */}
+ 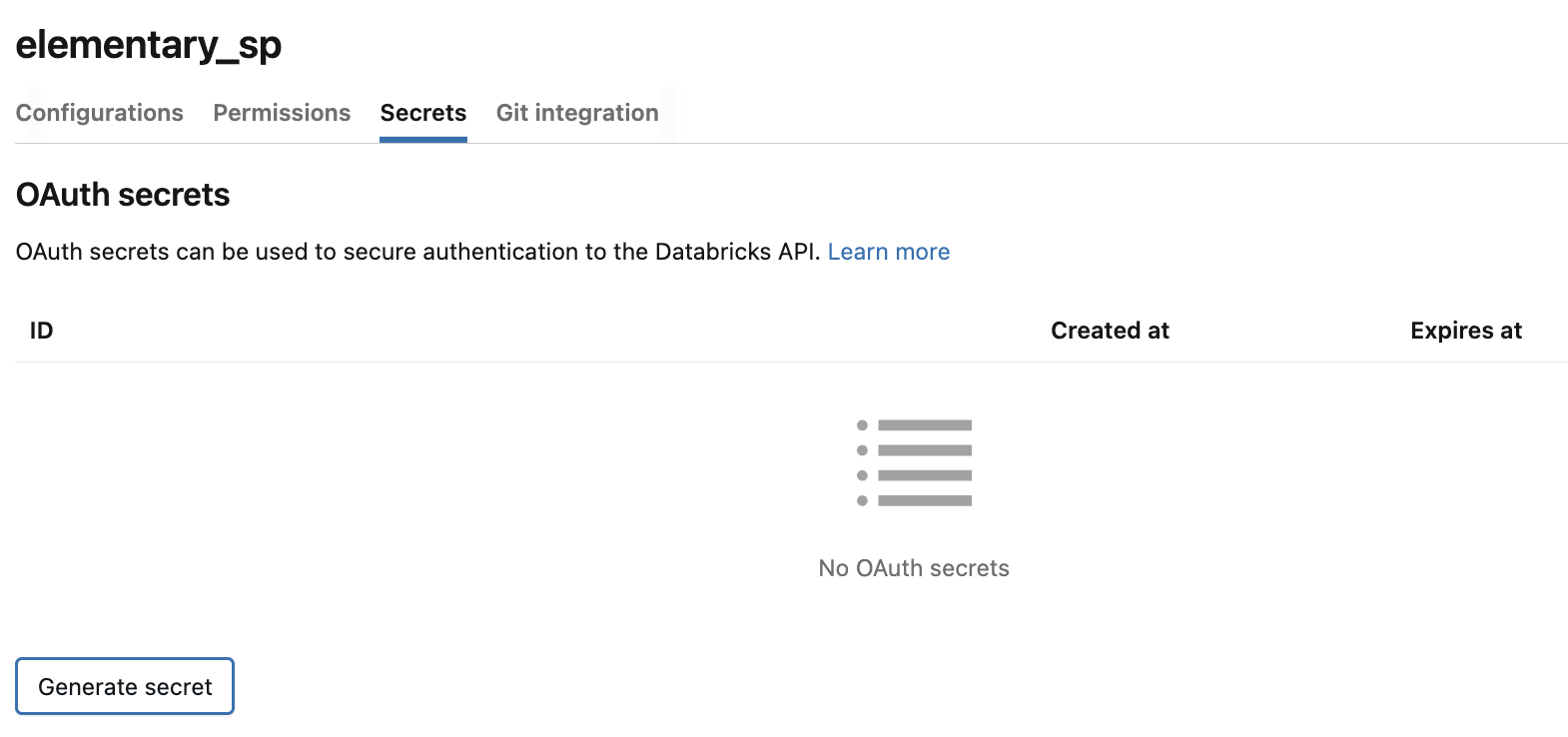 +
+ 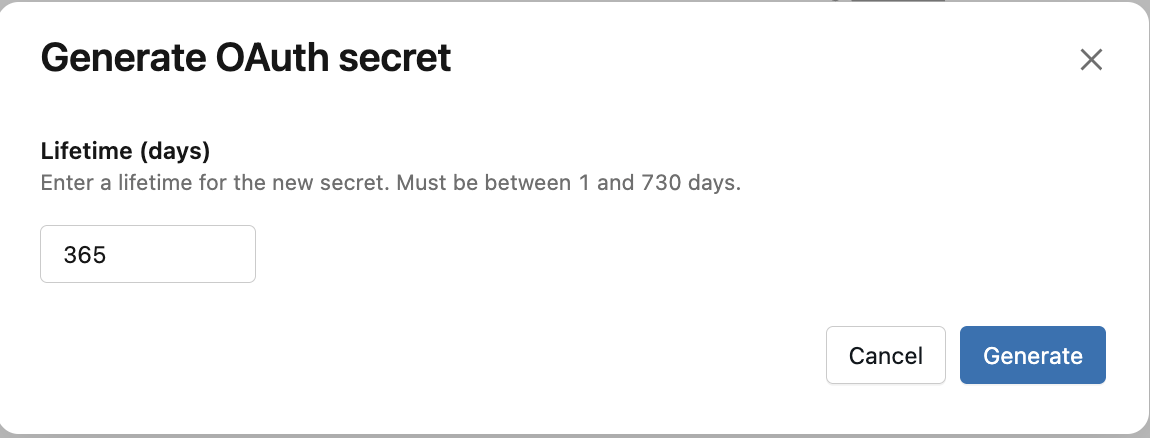 +
+
+
+ 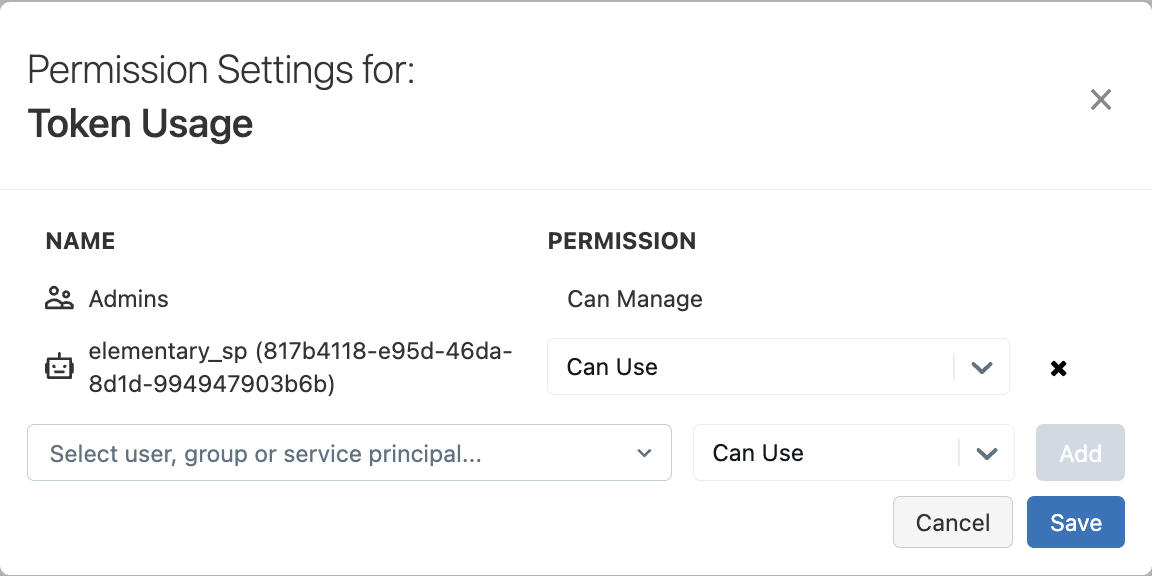 +
+ Then, create a personal access token for your service principal. For more details, please click [here](https://docs.databricks.com/aws/en/dev-tools/auth/pat#databricks-personal-access-tokens-for-service-principals).
+
+7. Finally, in order to enable Elementary's automated monitors feature, please ensure [predictive optimization](https://docs.databricks.com/aws/en/optimizations/predictive-optimization#enable-or-disable-predictive-optimization-for-your-account) is enabled in your account.
+This is required for table statistics to be updated (Elementary relies on this to obtain up-to-date row counts)
diff --git a/docs/snippets/dwh/databricks/databricks_permissions_and_security.mdx b/docs/snippets/dwh/databricks/databricks_permissions_and_security.mdx
new file mode 100644
index 000000000..32ef78686
--- /dev/null
+++ b/docs/snippets/dwh/databricks/databricks_permissions_and_security.mdx
@@ -0,0 +1,37 @@
+### Permissions and security
+
+#### Required permissions
+
+Elementary cloud requires the following permissions:
+
+- **Elementary schema read-only access** - This is required by Elementary to read dbt metadata & test results collected by the Elementary dbt package as a part of your pipeline runs.
+This permission does not give access to your data.
+
+- **Information schema metadata access** - Elementary needs access to the `system.information_schema.tables` and `system.information_schema.columns` system tables, to get metadata
+about existing tables and columns in your data warehouse. This is used to power features such as column-level lineage and automated volume & freshness monitors.
+
+- **Read access needed for some metadata operations (optional)** - In order to enable Elementary's automated volume & freshness monitors, Elementary needs access to query history, as well
+as Databricks APIs to obtain table statistics.
+These operations require granting SELECT access on your tables. This is a Databricks limitation - Elementary **never** reads any data from your tables, only metadata. However, there isn't
+today any table-level metadata-only permission available in Databricks, so SELECT is required.
+
+
+#### Grants SQL template
+
+Please use the following SQL statements to grant the permissions specified above (you should replace the placeholders with the correct values):
+
+```sql
+-- Grant read access on the elementary schema (usually [your dbt target schema]_elementary)
+GRANT USE CATALOG ON CATALOG
+
+ Then, create a personal access token for your service principal. For more details, please click [here](https://docs.databricks.com/aws/en/dev-tools/auth/pat#databricks-personal-access-tokens-for-service-principals).
+
+7. Finally, in order to enable Elementary's automated monitors feature, please ensure [predictive optimization](https://docs.databricks.com/aws/en/optimizations/predictive-optimization#enable-or-disable-predictive-optimization-for-your-account) is enabled in your account.
+This is required for table statistics to be updated (Elementary relies on this to obtain up-to-date row counts)
diff --git a/docs/snippets/dwh/databricks/databricks_permissions_and_security.mdx b/docs/snippets/dwh/databricks/databricks_permissions_and_security.mdx
new file mode 100644
index 000000000..32ef78686
--- /dev/null
+++ b/docs/snippets/dwh/databricks/databricks_permissions_and_security.mdx
@@ -0,0 +1,37 @@
+### Permissions and security
+
+#### Required permissions
+
+Elementary cloud requires the following permissions:
+
+- **Elementary schema read-only access** - This is required by Elementary to read dbt metadata & test results collected by the Elementary dbt package as a part of your pipeline runs.
+This permission does not give access to your data.
+
+- **Information schema metadata access** - Elementary needs access to the `system.information_schema.tables` and `system.information_schema.columns` system tables, to get metadata
+about existing tables and columns in your data warehouse. This is used to power features such as column-level lineage and automated volume & freshness monitors.
+
+- **Read access needed for some metadata operations (optional)** - In order to enable Elementary's automated volume & freshness monitors, Elementary needs access to query history, as well
+as Databricks APIs to obtain table statistics.
+These operations require granting SELECT access on your tables. This is a Databricks limitation - Elementary **never** reads any data from your tables, only metadata. However, there isn't
+today any table-level metadata-only permission available in Databricks, so SELECT is required.
+
+
+#### Grants SQL template
+
+Please use the following SQL statements to grant the permissions specified above (you should replace the placeholders with the correct values):
+
+```sql
+-- Grant read access on the elementary schema (usually [your dbt target schema]_elementary)
+GRANT USE CATALOG ON CATALOG
+ Ask any question about Elementary.
+
+
+ Leave your email in case a follow up is needed:
+
{error}
} +Integrations:
 @@ -20,13 +19,14 @@
title="Elementary OSS Package"
icon="square-terminal"
iconType="solid"
+ href="/oss/oss-introduction"
+
>
@@ -20,13 +19,14 @@
title="Elementary OSS Package"
icon="square-terminal"
iconType="solid"
+ href="/oss/oss-introduction"
+
>
For data and analytics engineers that require basic observability capabilities or for evaluating features without vendor approval. Our community can provide great support if needed.
Integrations:
 diff --git a/docs/snippets/quickstart/quickstart-elementary-prod.mdx b/docs/snippets/quickstart/quickstart-elementary-prod.mdx
new file mode 100644
index 000000000..682357f85
--- /dev/null
+++ b/docs/snippets/quickstart/quickstart-elementary-prod.mdx
@@ -0,0 +1,82 @@
+import QuestionSchema from '/snippets/faq/question-schema.mdx';
+
+
diff --git a/docs/snippets/quickstart/quickstart-elementary-prod.mdx b/docs/snippets/quickstart/quickstart-elementary-prod.mdx
new file mode 100644
index 000000000..682357f85
--- /dev/null
+++ b/docs/snippets/quickstart/quickstart-elementary-prod.mdx
@@ -0,0 +1,82 @@
+import QuestionSchema from '/snippets/faq/question-schema.mdx';
+
+## Running Elementary @@ -68,4 +74,4 @@ edr report ## Congratulations! Congratulations, you successfully configured Elementary's tests and ran the report! -